この記事は自作している強化学習フレームワークの解説記事です。
前:World Models
次:Dreamer
世界(World)の次は星(Planet)ですね。
モデルベース強化学習
強化学習は環境をブラックボックスと見るモデルフリーな手法と、ホワイトボックスと見るモデルベースな手法に分かれます。
もし環境が分かっているならば、エージェントは AlphaZero のように長期的な未来を予想し、より慎重にアクションを選択できます。
モデルベース強化学習は、モデルベースな学習を実現するために実環境の振る舞いをエージェントに学習させ、その振る舞いを元にアクションを決定する手法です。1
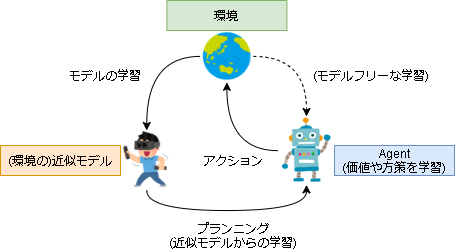
モデルベース強化学習では、近似モデルからの学習を"プランニング"といい、モデルフリーな学習と分けて考えます。
また、PlaNetでは実環境の振る舞いをダイナミクス(dynamics)、近似モデルはそれを学習したモデルとしてダイナミクスモデル(dynamics model)と表現しているのでこの記事ではそれに倣って使います。
PlaNet
PlaNet は Deep Planning Network の略で、プランニングするニューラルネットを意味します。
0.モチベーション
ダイナミクスを学習したモデルは、実環境の不要な情報が減り、また実行も仮想的に行えるのでより自然な形で高効率な学習が可能です。
ただプランニングを成功させるための十分なダイナミクスモデルを作成することは難しく、長年の研究課題となっています。
そこで、モデルベース強化学習を促進させるためにDeepMind社が協力して提案された手法が PlaNet になります。
参考
・論文:https://arxiv.org/abs/1811.04551
・blog:https://planetrl.github.io/
・コードサンプル:https://paperswithcode.com/paper/learning-latent-dynamics-for-planning-from
・Introducing PlaNet: A Deep Planning Network for Reinforcement Learning | Google AI Blog
・PlaNet:画像入力から世界モデルを学ぶ強化学習 | WebBigdata
1.ダイナミクスモデル(Dynamics Model)
ダイナミクスモデルの概要は以下です。
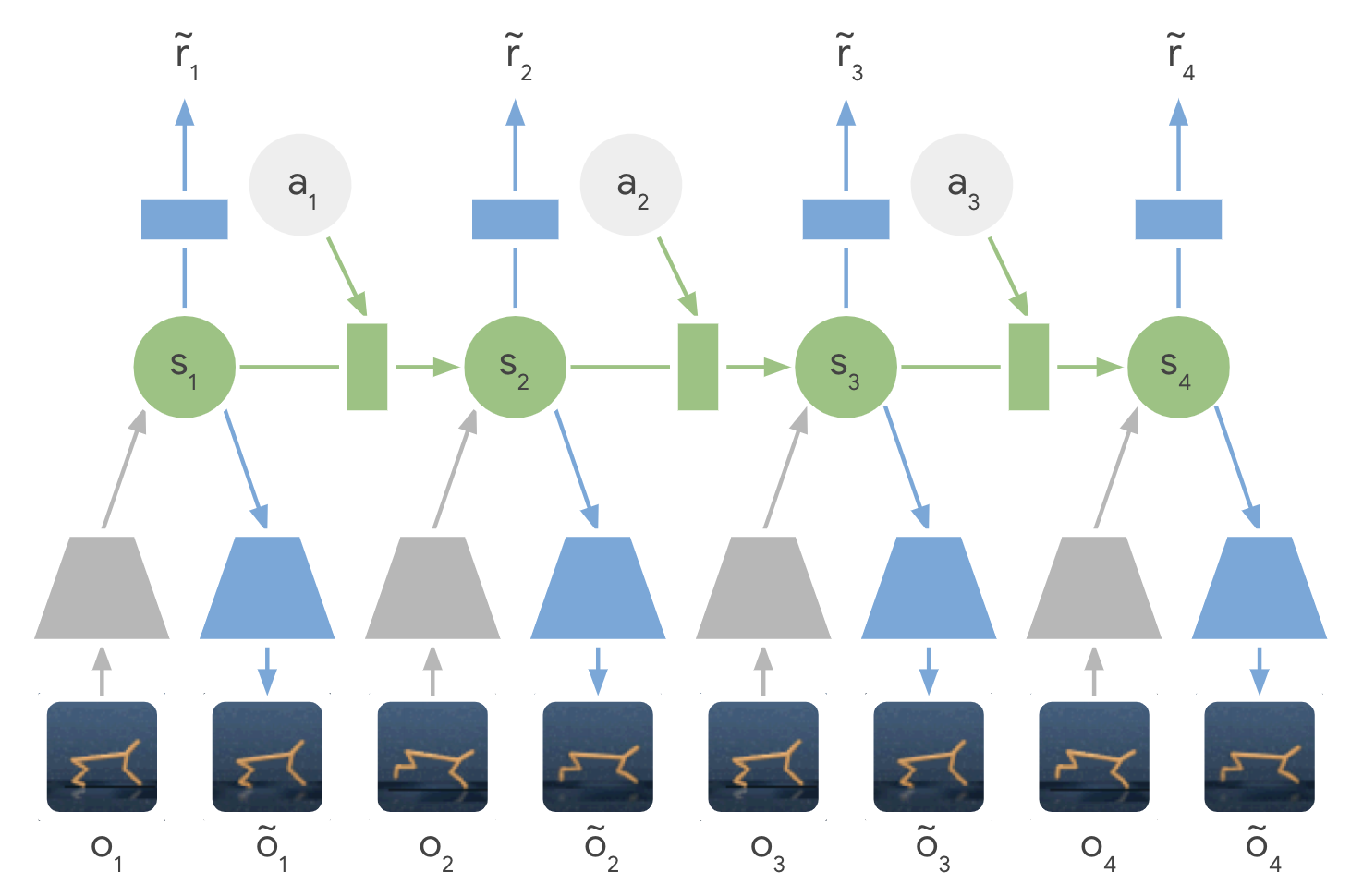
灰色の台形が Encoder を表し、状態を潜在空間 $s_1$ に変換します。
潜在空間 $s_1$ はアクション $a_1$ と合わせて次の潜在空間 $s_2$ に遷移します。
潜在空間 $s_2$ からは報酬 $\tilde{r}_2$ と状態 $\tilde{o}_2$ が予測可能です。
詳細な構成は以下です。
※2023/3 図を大幅に変えました。
※githubに上がっているDreamerの実装コード(https://github.com/danijar/dreamer)から図示しています。
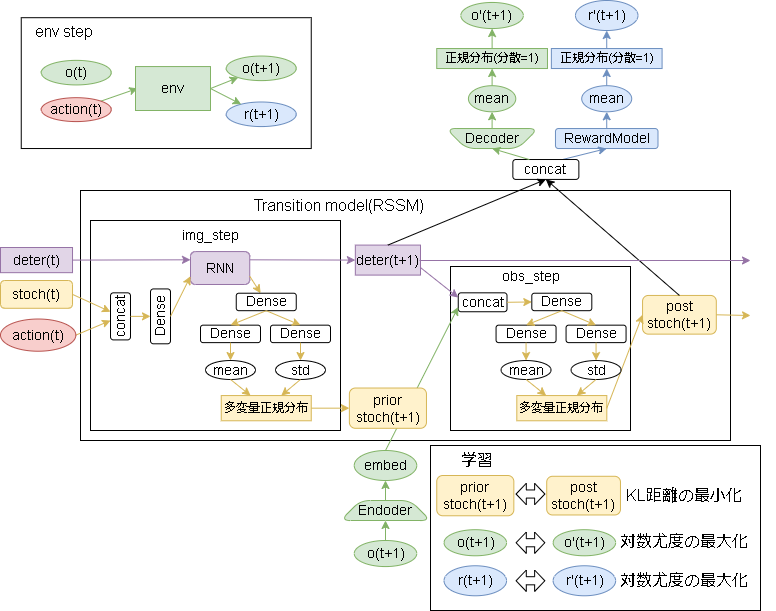
緑色が Encoder/Decoder モデルでほぼVAEです。
(Decoderに潜在空間 $embed$ だけではなく、RSSMの特徴量(deter,stoch)も入力する点が違います)
(Decoder部分は論文内だと Observation model になります)
真ん中のRSSMが遷移を表すモデルで、前の特徴量 deter(決定的特徴量),stoch(確率的特徴量)とアクションから次の特徴量を出力します。
論文からは読み取れませんでしたがコード上はimg_stepとobs_stepに分かれており、img_step は前ステップの情報から次の特徴量を予測し、obs_stepは次の状態から正解ラベルとなる特徴量を出力する構造に読み取れました。
最後に青部分ですが、報酬を予測するモデルです。
RSSM(Recurrent State Space Model)
RSSM の目的は決定的に変化する状態と確率的に変化する状態を分けて学習することです。
PlaNet が想定している状態は映像(時系列な画像)で、例えば背景などはほぼ決定的に変化し、メインの物体は確率的に変化します。
これを明確に分けてモデル化し、高精度化しようというのがRSSMです。(この有用性については本記事では触れません、興味がある方は論文を見てください)
構成としては、決定論的遷移(Deterministic Model)と確率論的遷移(Stochastic Model)から構成され、前者は RNN、後者はガウス過程2としてモデル化されます。
Latent Overshooting
モデルの予測フローですが、各ステップの遷移に関して2つのフローが考えられます。
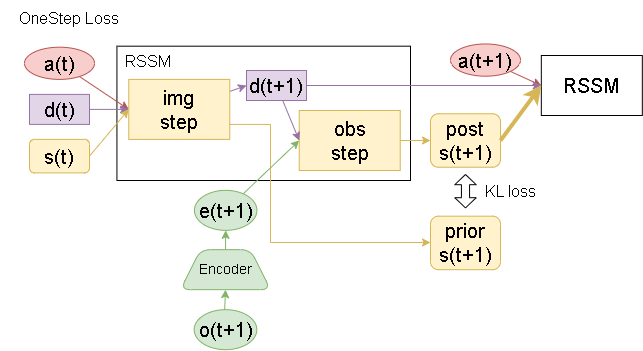
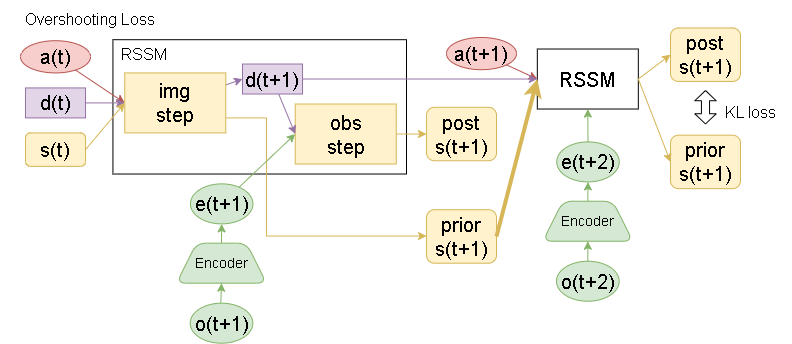
stochの使用に関して、post側を使う場合か、prior側を使う場合かです。
KL損失において、OneStep Loss のみを学習する場合、複数ステップにわたる勾配が流れません。
そこで下図のような Overshooting された状態でのKL損失も加えることで複数ステップに渡る損失も流れるようにさせる事を考えます。
複数ステップを加味した場合のKL損失のイメージは以下です。
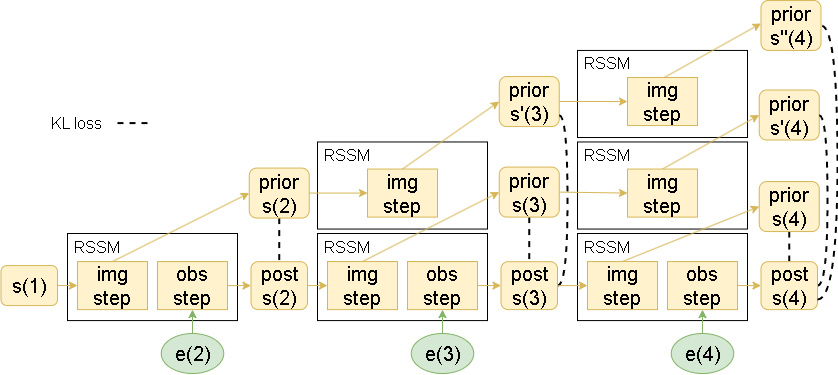
ステップを踏むごとに選択肢が増えていくイメージです。
損失
Encoder/Decoder部分の損失はVAEと同じく再構築損失(reconstruction loss)です。
RSSM側の損失目標は img_step から予測された特徴量(prior stoch)と obs_step から予測された特徴量(post stoch)とのKL距離の最小化です。(どちらもガウス分布)

$D$ は Overshooting のstep数を表しています。
$\beta$ は β-VAE と同じ役割を果たす係数です。
(Overshooting項は長期的な予測をする正則化項とも見なせるのでβ-VAEのような解釈ができるとのこと)
βは1より大きい値($\beta > 1$)を取り、潜在空間の各次元にて独立した特徴量を持たせる役割があります。
参考:深層生成モデルを巡る旅(2): VAE | Qiita
$\beta$ は Overshooting のstep数毎に変えてもいいらしいですが論文では一律で同じ値を使っているそうです。
最後に報酬ですが、報酬はガウス過程で予測し損失目標は対数尤度の最大化となります。
PlaNetは報酬の損失は数式は明に記載されていませんが、Dreamerに倣って同時に勾配を計算しています。
3. プランニング
PlaNetでは方策を事前に学習せず、1ステップ毎に探索してアクションを決定します。
アクションの決め方(プランニング)は未来の報酬が予想できるので、数ステップ先の報酬を予測してその合計報酬が一番高いアクションを選択します。
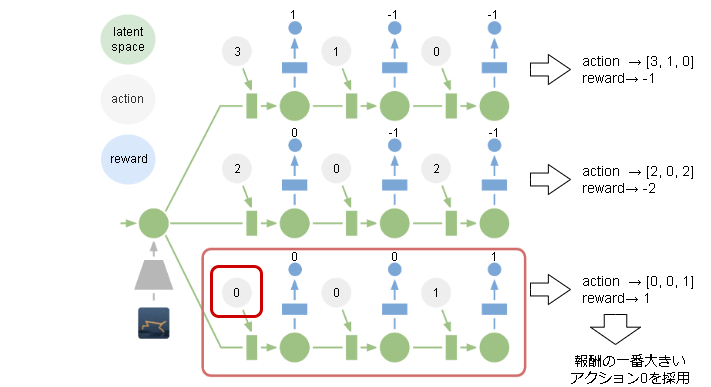
具体的な予測は以下です。
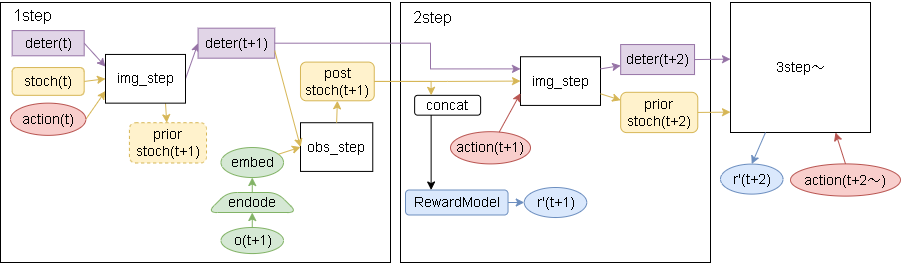
action(t)~action(t+n)までを入力とし、r'(t+1)~r'(t+n)の報酬の合計をスコアとします。
報酬の合計が最も大きい任意のactionが方策として選ばれます。
これら一連のアクションの探索ですが、進化戦略アルゴリズムを使用して探索します。3
論文では進化戦略アルゴリズムとしてクロスエントロピー法(cross entropy method; CEM)が使われていますが、フレームワーク上はWorldModelsと同様に遺伝的アルゴリズムで実装しました。
実装
コード全体はこちらです。
ハイパーパラメータ
class Config(DiscreteActionConfig):
lr: float = 0.001
batch_size: int = 50
batch_length: int = 50
capacity: int = 100_000
memory_warmup_size: int = 1000
# Model
deter_size: int = 200
stoch_size: int = 30
num_units: int = 400
dense_act: Any = "elu"
cnn_act: Any = "relu"
cnn_depth: int = 32
free_nats: float = 3.0
kl_scale: float = 1.0
enable_overshooting_loss: bool = False
# GA
action_algorithm: str = "ga" # "ga" or "random"
pred_action_length: int = 5
num_generation: int = 10
num_individual: int = 5
num_simulations: int = 20
mutation: float = 0.1
# other
clip_rewards: str = "none" # "none" or "tanh"
RemoteMemory
1エピソードを1batchとしてランダムに取り出します。
実装は ExperienceReplayBuffer と同じなのでコードは省略します。
DynamicsModel
説明にも書きましたが、Dreamerの実装コード(https://github.com/danijar/dreamer)を元に書いています。
またRNNですが、LSTMではなく GRU(Gated recurrent unit) で実装されています。
GRUをざっくり言うと、LSTMから長期記憶を省略することで高速化したRNNです。
- RSSM
class _RSSM(keras.Model):
def __init__(self, stoch=30, deter=200, hidden=200, act=tf.nn.elu):
super().__init__()
self.rnn_cell = kl.GRUCell(deter)
self.obs1 = kl.Dense(hidden, activation=act)
self.obs_mean = kl.Dense(stoch, activation=None)
self.obs_std = kl.Dense(stoch, activation=None)
self.img1 = kl.Dense(hidden, activation=act)
self.img2 = kl.Dense(hidden, activation=act)
self.img_mean = kl.Dense(stoch, activation=None)
self.img_std = kl.Dense(stoch, activation=None)
def obs_step(self, prev_stoch, prev_deter, prev_action, embed, training=False, _summary: bool = False):
deter, prior = self.img_step(prev_stoch, prev_deter, prev_action, training=training, _summary=_summary)
x = tf.concat([deter, embed], -1)
x = self.obs1(x)
mean = self.obs_mean(x)
std = self.obs_std(x)
std = tf.nn.softplus(std) + 0.1
if _summary:
return [mean, std, prior["mean"], prior["std"]]
stoch = tfd.MultivariateNormalDiag(mean, std).sample()
post = {"mean": mean, "std": std, "stoch": stoch}
return post, deter, prior
def img_step(self, prev_stoch, prev_deter, prev_action, training=False, _summary: bool = False):
x = tf.concat([prev_stoch, prev_action], -1)
x = self.img1(x)
x, deter = self.rnn_cell(x, [prev_deter], training=training)
deter = deter[0]
x = self.img2(x)
mean = self.img_mean(x)
std = self.img_std(x)
std = tf.nn.softplus(std) + 0.1
if _summary:
return deter, {"mean": mean, "std": std}
stoch = tfd.MultivariateNormalDiag(mean, std).sample()
prior = {"mean": mean, "std": std, "stoch": stoch}
return deter, prior
def get_initial_state(self, batch_size: int = 1):
return self.rnn_cell.get_initial_state(None, batch_size, dtype=tf.float32)
- Encoder/Decoder
class _ConvEncoder(keras.Model):
def __init__(self, depth: int = 32, act=tf.nn.relu):
super().__init__()
kwargs = dict(kernel_size=4, strides=2, activation=act)
self.conv1 = kl.Conv2D(filters=1 * depth, **kwargs)
self.conv2 = kl.Conv2D(filters=2 * depth, **kwargs)
self.conv3 = kl.Conv2D(filters=4 * depth, **kwargs)
self.conv4 = kl.Conv2D(filters=8 * depth, **kwargs)
self.hout = kl.Flatten()
def call(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.hout(x)
return x
class _ConvDecoder(keras.Model):
def __init__(self, depth: int = 32, act=tf.nn.relu):
super().__init__()
kwargs = dict(strides=2, activation=act)
self.in_layer = kl.Dense(32 * depth)
self.reshape = kl.Reshape([1, 1, 32 * depth])
self.c1 = kl.Conv2DTranspose(4 * depth, kernel_size=5, **kwargs)
self.c2 = kl.Conv2DTranspose(2 * depth, kernel_size=5, **kwargs)
self.c3 = kl.Conv2DTranspose(1 * depth, kernel_size=6, **kwargs)
self.c4_mean = kl.Conv2DTranspose(3, kernel_size=6, strides=2)
self.c4_std = kl.Conv2DTranspose(3, kernel_size=6, strides=2)
def call(self, x, _summary: bool = False):
x = self.in_layer(x)
x = self.reshape(x)
x = self.c1(x)
x = self.c2(x)
x = self.c3(x)
x_mean = self.c4_mean(x)
x_std = self.c4_std(x)
x_std = tf.nn.softplus(x_std) + 0.1
if _summary:
return x_mean
return tfd.Independent(tfd.Normal(x_mean, x_std), reinterpreted_batch_ndims=len(x.shape) - 1)
ConvDecoder は参考にしたコード上はなぜか分散が1で固定になっています。
(Normalの部分ですが、tfd.Normal(x_mean, 1) と分散の箇所が1になっています)
理由は分からなかったのですが、コード上は分散も含め学習する形に変更しています。
- Reward
class _DenseDecoder(keras.Model):
def __init__(self, out_shape, layers: int, units: int, dist: str = "normal", act=tf.nn.elu):
super().__init__()
self._out_shape = out_shape
self._dist = dist
self.h_layers = [kl.Dense(units, activation=act) for i in range(layers)]
self.hout_mean = kl.Dense(np.prod(self._out_shape))
self.hout_std = kl.Dense(np.prod(self._out_shape))
def call(self, x, _summary: bool = False):
for layer in self.h_layers:
x = layer(x)
x_mean = self.hout_mean(x)
x_std = self.hout_std(x)
x_std = tf.nn.softplus(x_std) + 0.1
x_mean = tf.reshape(x_mean, (-1,) + self._out_shape)
x_std = tf.reshape(x_std, (-1,) + self._out_shape)
if _summary:
return x_mean
if self._dist == "normal":
return tfd.Independent(tfd.Normal(x_mean, x_std), reinterpreted_batch_ndims=len(self._out_shape))
if self._dist == "binary":
return tfd.Independent(tfd.Bernoulli(x), reinterpreted_batch_ndims=len(self._out_shape))
raise NotImplementedError(self._dist)
Decoder と同じく分散が1固定だったので学習できるように変更しています。
Parameter
Config含め以下のような実装になります。
class Parameter(RLParameter):
def __init__(self, *args):
super().__init__(*args)
self.encode = _ConvEncoder(self.config.cnn_depth, self.config.cnn_act)
self.dynamics = _RSSM(self.config.stoch_size, self.config.deter_size, self.config.deter_size)
self.decode = _ConvDecoder(self.config.cnn_depth, self.config.cnn_act)
self.reward = _DenseDecoder((1,), 2, self.config.num_units, "normal", self.config.dense_act)
Trainer
overshooting を加味すると1step毎に次の状態を予測する必要があり、計算にかなり時間がかかります。
overshooting がない場合はRNNの計算を一括でできるためかなり早いです。
それぞれの場合を書いておきます。
- overshootingなし
class Trainer(RLTrainer):
def train(self):
if self.remote_memory.length() < self.config.memory_warmup_size:
return {}
batchs = self.remote_memory.sample(self.config.batch_size)
states = np.asarray([b["states"] for b in batchs], dtype=np.float32)
actions = [b["actions"] for b in batchs]
rewards = np.asarray([b["rewards"] for b in batchs], dtype=np.float32)[..., np.newaxis]
# onehot action
actions = tf.one_hot(actions, self.config.action_num, axis=2)
# (batch, seq, shape) -> (batch * seq, shape)
states = tf.reshape(states, (self.config.batch_size * self.config.batch_length,) + states.shape[2:])
rewards = tf.reshape(rewards, (self.config.batch_size * self.config.batch_length,) + rewards.shape[2:])
with tf.GradientTape() as tape:
embed = self.parameter.encode(states, training=True)
# (batch * seq, shape) -> (batch, seq, shape)
# (batch, seq, shape) -> (seq, batch, shape)
shape = (self.config.batch_size, self.config.batch_length) + embed.shape[1:]
embed = tf.reshape(embed, shape)
embed = tf.transpose(embed, [1, 0, 2])
actions = tf.transpose(actions, [1, 0, 2])
stochs = []
deters = []
stoch = tf.zeros([self.config.batch_size, self.config.stoch_size], dtype=tf.float32)
deter = self.parameter.dynamics.get_initial_state(self.config.batch_size)
post_mean = []
post_std = []
prior_mean = []
prior_std = []
for i in range(self.config.batch_length):
post, deter, prior = self.parameter.dynamics.obs_step(
stoch, deter, actions[i], embed[i], training=True
)
stoch = post["stoch"]
stochs.append(stoch)
deters.append(deter)
post_mean.append(post["mean"])
post_std.append(post["std"])
prior_mean.append(prior["mean"])
prior_std.append(prior["std"])
stochs = tf.stack(stochs, axis=0)
deters = tf.stack(deters, axis=0)
post_mean = tf.stack(post_mean, axis=0)
post_std = tf.stack(post_std, axis=0)
prior_mean = tf.stack(prior_mean, axis=0)
prior_std = tf.stack(prior_std, axis=0)
# (seq, batch, shape) -> (batch, seq, shape)
stochs = tf.transpose(stochs, [1, 0, 2])
deters = tf.transpose(deters, [1, 0, 2])
post_mean = tf.transpose(post_mean, [1, 0, 2])
post_std = tf.transpose(post_std, [1, 0, 2])
prior_mean = tf.transpose(prior_mean, [1, 0, 2])
prior_std = tf.transpose(prior_std, [1, 0, 2])
feat = tf.concat([stochs, deters], -1)
feat = tf.reshape(feat, (self.config.batch_size * self.config.batch_length,) + feat.shape[2:])
image_pred = self.parameter.decode(feat)
reward_pred = self.parameter.reward(feat)
image_loss = tf.reduce_mean(image_pred.log_prob(states))
reward_loss = tf.reduce_mean(reward_pred.log_prob(rewards))
prior_dist = tfd.MultivariateNormalDiag(prior_mean, prior_std)
post_dist = tfd.MultivariateNormalDiag(post_mean, post_std)
kl_loss = tfd.kl_divergence(post_dist, prior_dist)
kl_loss = tf.reduce_mean(kl_loss)
kl_loss = tf.maximum(kl_loss, self.config.free_nats)
loss = self.config.kl_scale * kl_loss - image_loss - reward_loss
variables = [
self.parameter.encode.trainable_variables,
self.parameter.dynamics.trainable_variables,
self.parameter.decode.trainable_variables,
self.parameter.reward.trainable_variables,
]
grads = tape.gradient(loss, variables)
for i in range(len(variables)):
self.optimizer.apply_gradients(zip(grads[i], variables[i]))
self.train_count += 1
return {
"img_loss": -image_loss.numpy() / (64 * 64 * 3),
"reward_loss": -reward_loss.numpy(),
"kl_loss": kl_loss.numpy(),
}
- overshootingあり
class Trainer(RLTrainer):
def train(self):
if self.remote_memory.length() < self.config.memory_warmup_size:
return {}
batchs = self.remote_memory.sample(self.config.batch_size)
states = np.asarray([b["states"] for b in batchs], dtype=np.float32)
actions = [b["actions"] for b in batchs]
rewards = np.asarray([b["rewards"] for b in batchs], dtype=np.float32)[..., np.newaxis]
# onehot action
actions = tf.one_hot(actions, self.config.action_num, axis=2)
# (batch, seq, shape) -> (batch * seq, shape)
states = tf.reshape(states, (self.config.batch_size * self.config.batch_length,) + states.shape[2:])
rewards = tf.reshape(rewards, (self.config.batch_size * self.config.batch_length,) + rewards.shape[2:])
with tf.GradientTape() as tape:
embed = self.parameter.encode(states, training=True)
# (batch * seq, shape) -> (batch, seq, shape)
# (batch, seq, shape) -> (seq, batch, shape)
shape = (self.config.batch_size, self.config.batch_length) + embed.shape[1:]
embed = tf.reshape(embed, shape)
embed = tf.transpose(embed, [1, 0, 2])
actions = tf.transpose(actions, [1, 0, 2])
stochs = []
deters = []
stoch = tf.zeros([self.config.batch_size, self.config.stoch_size], dtype=tf.float32)
deter = self.parameter.dynamics.get_initial_state(self.config.batch_size)
kl_loss_list = []
overshooting_list = []
for i in range(self.config.batch_length):
post, n_deter, prior = self.parameter.dynamics.obs_step(
stoch, deter, actions[i], embed[i], training=True
)
# image/reward
stochs.append(post["stoch"])
deters.append(n_deter)
# 0step KL loss
prior_dist = tfd.MultivariateNormalDiag(prior["mean"], prior["std"])
post_dist = tfd.MultivariateNormalDiag(post["mean"], post["std"])
step_kl_loss = tfd.kl_divergence(post_dist, prior_dist)
# calc overshooting KL loss
n_overshooting_list = [prior]
for o_prior in overshooting_list:
_, o_prior = self.parameter.dynamics.img_step(o_prior["stoch"], deter, actions[i], training=True)
o_prior_dist = tfd.MultivariateNormalDiag(o_prior["mean"], o_prior["std"])
step_kl_loss += tfd.kl_divergence(post_dist, o_prior_dist)
n_overshooting_list.append(o_prior)
# add overshooting KL loss
step_kl_loss /= len(overshooting_list) + 1
kl_loss_list.append(step_kl_loss)
# next
deter = n_deter
stoch = post["stoch"]
overshooting_list = n_overshooting_list
stochs = tf.stack(stochs, axis=0)
deters = tf.stack(deters, axis=0)
# (seq, batch, shape) -> (batch, seq, shape)
stochs = tf.transpose(stochs, [1, 0, 2])
deters = tf.transpose(deters, [1, 0, 2])
feat = tf.concat([stochs, deters], -1)
feat = tf.reshape(feat, (self.config.batch_size * self.config.batch_length,) + feat.shape[2:])
image_pred = self.parameter.decode(feat)
reward_pred = self.parameter.reward(feat)
image_loss = tf.reduce_mean(image_pred.log_prob(states))
reward_loss = tf.reduce_mean(reward_pred.log_prob(rewards))
kl_loss = tf.reduce_mean(kl_loss_list)
kl_loss = tf.maximum(kl_loss, self.config.free_nats)
loss = self.config.kl_scale * kl_loss - image_loss - reward_loss
variables = [
self.parameter.encode.trainable_variables,
self.parameter.dynamics.trainable_variables,
self.parameter.decode.trainable_variables,
self.parameter.reward.trainable_variables,
]
grads = tape.gradient(loss, variables)
for i in range(len(variables)):
self.optimizer.apply_gradients(zip(grads[i], variables[i]))
self.train_count += 1
return {
"img_loss": -image_loss.numpy() / (64 * 64 * 3),
"reward_loss": -reward_loss.numpy(),
"kl_loss": kl_loss.numpy(),
}
Worker
GAでアクションを決めますが、学習でもGAを使っていると時間がかかりすぎるので学習中はランダムにアクションを決めるようにしています。
アクションを決定する箇所のみを載せておきます。
class Worker(DiscreteActionWorker):
def call_policy(self, state: np.ndarray, invalid_actions: List[int]) -> int:
if self.training:
# トレーニング中はランダムアクション
action = self.sample_action()
else:
# zにエンコード
z = self.parameter.model.encode(state[np.newaxis, ...])
# GAでアクションを決定
action = self._ga_policy(z)
# hidden_state を進める
_, self.hidden_state = self.parameter.model.one_step_transition(z, action, self.hidden_state)
return action
def _ga_policy(self, z):
# --- 初期個体
elite_actions = [
[random.randint(0, self.config.action_num - 1) for a in range(self.config.pred_action_length)]
for _ in range(self.config.num_individual)
]
best_actions = None
# --- 世代ループ
for g in range(self.config.num_generation):
# --- 個体を評価
t0 = time.time()
elite_rewards = []
for i in range(len(elite_actions)):
rewards = []
for _ in range(self.config.num_simulations):
reward = self._eval_actions(z, elite_actions[i], self.hidden_state)
rewards.append(reward)
elite_rewards.append(np.mean(rewards))
elite_rewards = np.array(elite_rewards)
# --- エリート戦略
next_elite_actions = []
best_idx = random.choice(np.where(elite_rewards == elite_rewards.max())[0])
best_actions = elite_actions[best_idx]
next_elite_actions.append(best_actions)
# 最後は交叉しない
if self.config.num_generation - 1 == g:
break
# weight
weights = elite_rewards - elite_rewards.min()
if weights.sum() == 0:
weights = np.full(len(elite_rewards), 1 / len(elite_rewards))
else:
weights = weights / weights.sum()
# --- 子の作成
while len(next_elite_actions) < self.config.num_individual:
# --- 親個体の選択(ルーレット方式、重複あり)
idx1 = np.argmax(np.random.multinomial(1, weights))
idx2 = np.argmax(np.random.multinomial(1, weights))
# --- 一様交叉
c1 = []
c2 = []
for i in range(self.config.pred_action_length):
if random.random() < 0.5:
_c1 = elite_actions[idx1][i]
_c2 = elite_actions[idx2][i]
else:
_c1 = elite_actions[idx2][i]
_c2 = elite_actions[idx1][i]
# 突然変異
if random.random() < self.config.mutation:
_c1 = random.randint(0, self.config.action_num - 1)
if random.random() < self.config.mutation:
_c2 = random.randint(0, self.config.action_num - 1)
c1.append(_c1)
c2.append(_c2)
next_elite_actions.append(c1)
next_elite_actions.append(c2)
elite_actions = next_elite_actions
# 一番いい結果のアクションを実行
return best_actions[0]
def _eval_actions(self, z, action_list, hidden_state):
""" z と hidden_state から action_list を実行して得た報酬を返す """
reward = 0
for step in range(len(action_list)):
h, hidden_state = self.parameter.model.one_step_transition(z, action_list[step], hidden_state)
# stochastic
z = self.parameter.model.pred_z(h)
# reward
s = tf.concat([z, h], axis=1)
pred_reward = self.parameter.reward_model(s)
reward += pred_reward.numpy()[0][0]
return reward
学習
アクションがGAで決まるのでなかなか安定しない印象です…。
overshootingを有効にすると時間がかかりすぎるのでないバージョンで学習させています。
コードは github を参照してください。

画像はWorldModelsと同じで、図の左上がオリジナルの環境で、original とあるのが強化学習が受け取る状態です。(64×64にリサイズされた後を受け取っています)
decode は original 画像を VAE を通して復元した結果です。
action の下にある画像は RSSM を通して予測された次の状態 z を復元したものです。
復元結果は一番上がmean(平均)を用いた画像で、下2つはランダムに出力した画像です。
おわりに
あまりネットに実装の情報がない印象でした。
やはりプランニングに時間がかかるのがネックですね。