文書の性質・目的に合わせて、適切に形態素解析する方法について、考えていきたいと思います。
今回は、①ルーズな文法、②未知語だらけ、という2つの性質を持つ文書に対して、辞書を用いずに形態素解析する方法を調べます。
※形態素解析全般に関する話題をスキップしたい場合は、辞書を用いない形態素解析まで飛ばしてください
背景
日本語の文書に対して、テキストマイニングを実施する場合、形態素解析の結果が正しいことは前提となります。
形態素解析の結果に誤りがあった場合、その後のテキストマイニングで非常に苦労します。
形態素解析は、文法的に正しく書かれており、未知語が比較的少ない文書(特許、新聞記事、論文など)に対しては良い結果を得やすいですが、
ルーズな文法で、未知語が多い文書(SNSの文書、会議での発言文書など)に対しては良い結果を得られない場合があります。
近年は、SNSの発達、スマートスピーカーの普及などが進んでいるため、①ルーズな文法、②未知語だらけの文書は今後増加していくものと考えられます。
そのため、上記のような性質を持った文書に対して、適切な形態素解析を可能とする技術について考えることは有益です。
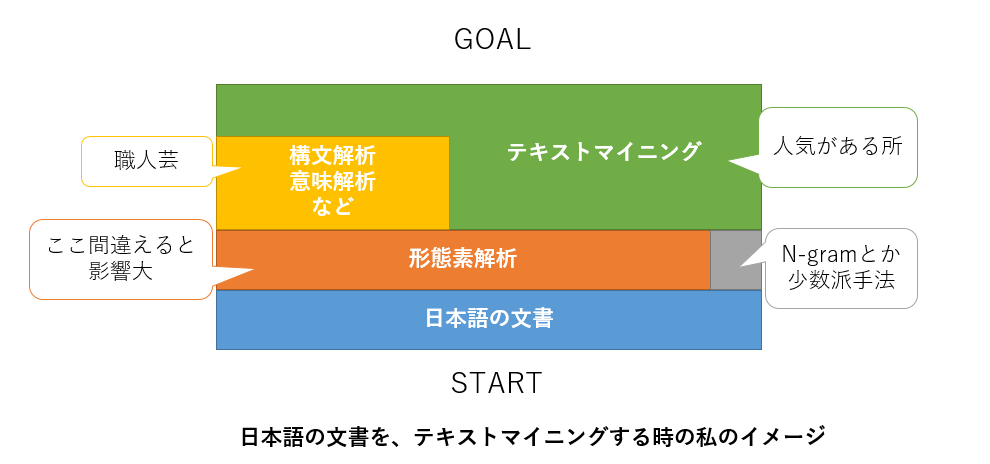
形態素解析とは?
日本語の文書を単語に分割する処理のことです。
例えば、「うらにわにはにわにわにはにわにわとりがいる」という文書があった時、
うらにわ(裏庭)
には
にわ(二羽)
にわ(庭)
には
にわ(二羽)
鶏(にわとり)
が
いる
と分割するのが形態素解析です。
より詳しくて正確な記述は、形態素解析 - Wikipediaにあります。
形態素解析の歴史
ここでは、コンピュータ上での自然言語処理としての形態素解析の歴史についてのみ言及します。
AIの歴史と概ね同じような流れを辿っているようです。(参考[2])
1980年代~90年代
・日本語の語彙、文法構造に基づくルールベースでの形態素解析
2000年前後
・日本語の文書における単語出現頻度等を加味した、機械学習的な自動調整を行う形態素解析
(JUMAN、Chasen、Mecab、Kuromojiなど)
2010年代中盤~後半
・**Deep Learining(RNNなど)**を利用した形態素解析
(JUMAN++など)
2010年代中盤以降からはDeep Learningを活用した形態素解析ツールも公開されていますが、
2018年現在は、2000年前後に開発された手法に基づく形態素解析ツールが主流のように思われます。
これは、実行速度・使い勝手などの面で、2000年前後の技術をベースとしたツールに一日の長があるためです。
また、Deep Learningを用いて学習したとしても、学習した時のデータと、適用先のデータのドメインが異なる場合(※)には、結局、形態素解析があまり上手くいかない、というケースも多いため、Deep Learningを用いた形態素解析が普及しないという背景もあるように思います。
※Wikipediaの文書で学習し、Twitterの文書に適用する場合、など。
出現する単語、文体の違いが想定されます
形態素解析って、一般的にはどうやっているの?
Chasen, Mecabなどでは、語彙に関する辞書と、日本語の文法を利用して形態素解析しています。
Chasen, Mecabで用いられている、辞書を用いてラティスを構築し、ラティスから最短経路を選択する方法について解説します。(参考[3])
ラティスの構築
「東京都に住む」という文章が入力として与えられた場合、形態素解析ツール内の辞書を参照して、下図のように全ての可能性のある語の組み合わせを、ノードとエッジで表現されるグラフ構造(ラティス)で構築します。
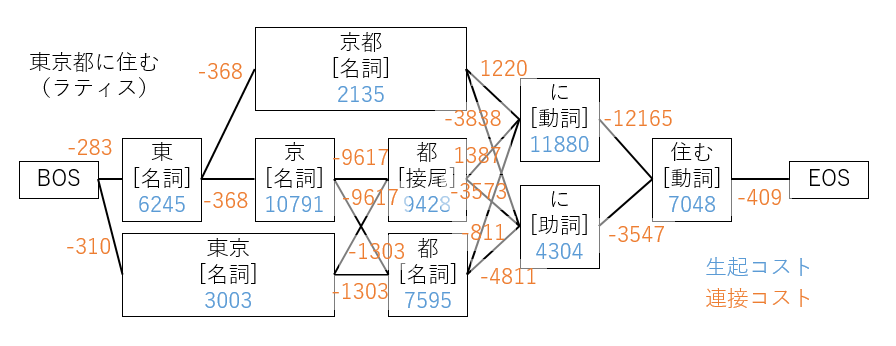
BOSは、Begining Of Sentenceを意味し、EOSは、End Of Sentenceを意味します。
各ノードには、生起コストが与えられます。
生起コストが高いものほど出現しにくく、低いものほど出現しやすいことを意味します。
また、各エッジには、連接コストが与えられます。
連接コストが低いものほどくっつきやすく、高いものほどくっつきにくいことを意味します。
生起コストと連接コストは、ルールベースでも決められますが、学習用の日本語の文書集合を用いて単語の出現頻度、品詞の連接関係などを用いて機械学習で自動調整する方法が一般的です。
このあたりの詳細の説明は、今回は割愛します。
また、Chasen、Mecabは、未知語が含まれていても一定の精度で動作するように工夫されていますが、そのあたりの説明も今回は割愛します。
※参考[3]に、詳細な説明があります。
最短経路の選択
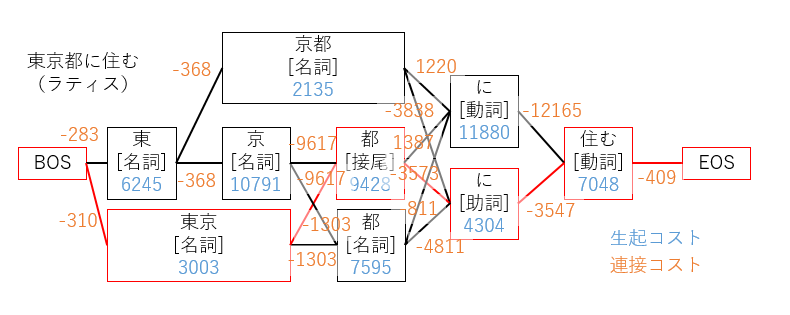
ラティスが構築できたら、コストが最短となるような経路を選択します。
この時、全ての経路の組み合わせを計算しようとすると、入力文章が長い場合に計算量が爆発します。
そこで、動的計画法の一つであるビタビアルゴリズムを利用することで計算量を抑えます。
ビタビアルゴリズムの詳細についても今回は割愛します。
参考[4]の説明がシンプルで分かりやすいです。
今回の例に対しては、以下のように最適な経路が求まります。
辞書を用いない形態素解析
ここまでの前提知識を踏まえて、辞書を用いない形態素解析の方法について説明します。
本記事では、梅村恭司氏が2000年に参考[5]で提唱している方法を紹介します。
基本的なアイディアは、
①形態素解析したい入力文書中の全てのN-gramの出現頻度を学習データの中から探索し、
②(N-gramが2回以上出現した文の数) / (N-gramが1回以上出現した文の数)に基づき重み付けし、
③N-gramとN-gramの重みで構成したラティスから、最短経路を選択する
というものです。
ポイントの1つ目は、形態素解析したい入力文書に含まれるN-gramについてのみ、学習データ中での出現頻度を計算する点です。これは、学習データに含まれる全てのN-gramの出現頻度の情報を保持すると、保持すべきデータ量が膨大となるためです。
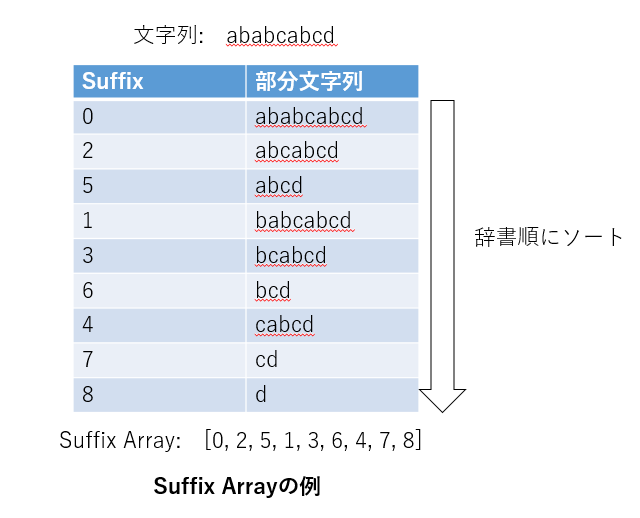
学習データ中から随時出現頻度を計算する場合は、処理速度が問題になりますが、これを解消するために、Suffix Arrayと呼ばれるデータ構造に学習データを保存します。
Suffix Arrayでは、対象となるテキスト中のすべての場所から最後までの部分文字列を,辞書順に並べた情報を保持します。このようにすることで、N-gramの出現有無を、$ \log (M) $(Mはテキストの長さ)の計算量で判定することが可能となります。
ポイントの2つ目は、(N-gramが2回以上出現した文の数) / (N-gramが1回以上出現した文の数)に基づき重み付けする点です。これは、文章を特徴づける重要なキーワードは文章中に複数回出現する可能性が1回だけ出現する可能性と比較して顕著に高い、という仮説に依拠したものです。この仮説は、英語・日本語の両方の文書で成り立つと主張されています。(参考[5],[6])
ポイントの3つ目は、N-gramと重みに基づき、ラティスを構築し、形態素解析を実施する点です。一般的な辞書ベースの形態素解析と似たアルゴリズムであるため、既存の方法と組み合わせることも容易であると推測されます。
まとめと今後
今回は、辞書なしで形態素解析を実施する方法を調べました。
辞書なしで形態素解析することで、未知語だらけの文書に対して良い解析結果が得られるとすれば、
役立つ機会も多そうです。
次回は、この方法をpythonで実装し、データ適用していきたいと思います。
参考
[1] 日本語未知語のテキストからの自動獲得
[2] 形態素解析の過去・現在・未来
[3] 日本語形態素解析の裏側を覗く!MeCab はどのように形態素解析しているか
[4] 自然言語処理プログラミング勉強会 4 - 単語分割
[5] 未踏テキスト情報中のキーワードの抽出システム開発
[6] Empirical Estimates of Adaptation: The chance of Two Noriegas is closer to p /2 than p2