これは?
Firebase Meetup #10 で 「Firestore導入前に検討したかったベスト5」 というテーマで発表したアーキテクチャ部分の話その2。(めちゃくちゃゆっくりな更新...)
①Firestoreを中心に据えた全体設計のコンセプト
②PubSubとCloud Functionsを使って、FirestoreのCollectionをマイクロサービスに見立てた話 ←今回
③パフォーマンスの劣化対策として、CacheのCollectionを作った話
トライしたこと
まず、どんなトライをしたのか説明していきます。
この中で、今回お話するのが、赤丸をした部分です。
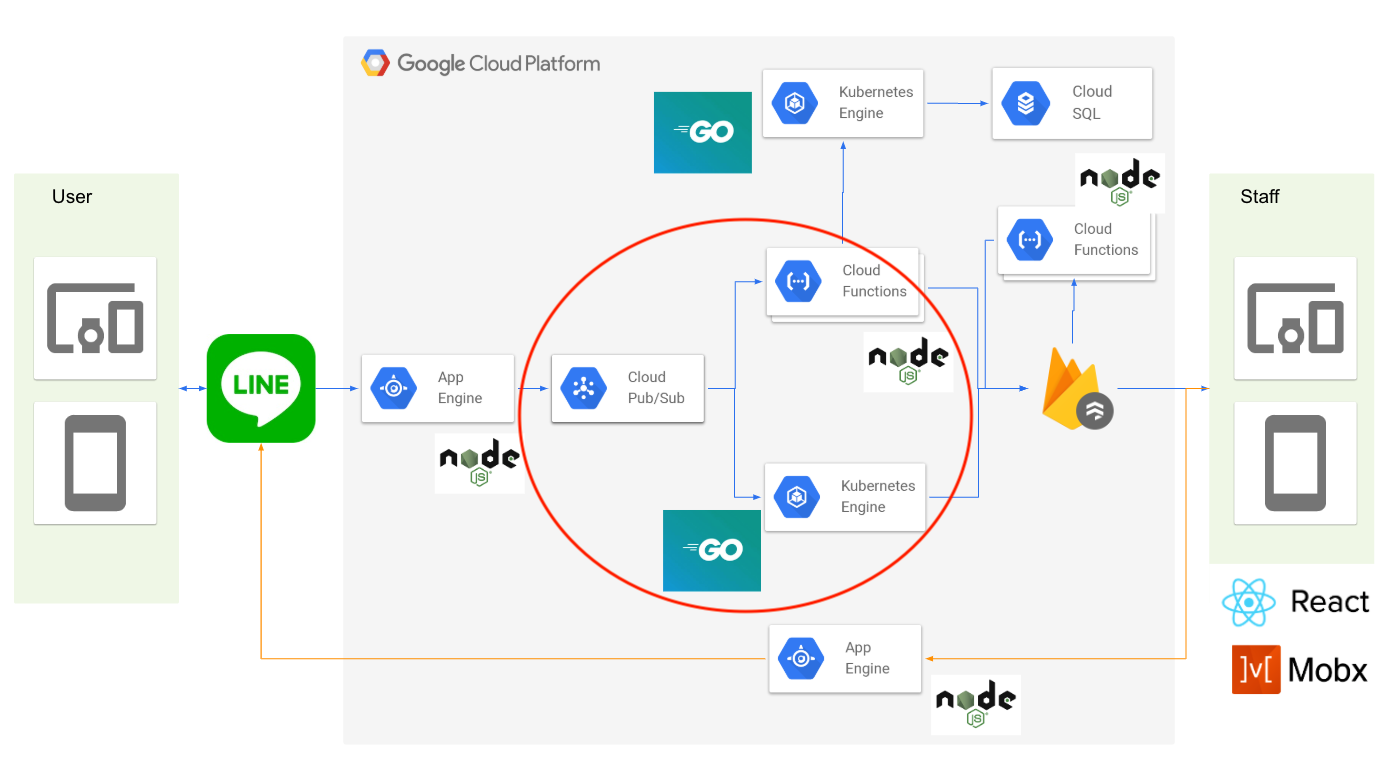
ここでは何をしているかというと、
1つのObjectを、PubSubにPublishするんですが、そのPublishされたもの(Topicと呼ばれます)に、複数のSubscriptionを付与しています。
そのSubscriptionは、Cloud Functionsなど、別々のアプリケーションに紐付けられてます。
つまり、何か新しいObjectがPublishされると、Cloud Functionsやらが、同時に並行して処理をはじめます。
その時に、それぞれのアプリケーションが、それぞれFirestoreの 1つのcollection に書き込みます。
つまり、そのcollectionにデータを入れるために、どんな処理が必要か、という責務に集中したアプリケーション群を並列に動かしました。
これは何でか、というと、
FirestoreはJOINできない = つまり、1つ1つのcollectionが別のデータベースのように振る舞っている と思ったからです。
もちろん、writeBatchを使ったり、transactionを使ったりして、リレーションを保つ方法はあります。
でも、そうやって自らに制約をどんどん課していくと、Firestoreの本来の力を引き出しきれなくなるのでは、と思いました。
というのも、 並列に動いて一時的にNullableになったとしても、本来、スキーマレスなのですべての値がNullableになりえるので、そういう設計をしていないといけないし、
何よりリアルタイム性が高いので、そのNullableな状態を許容した上で、整合性取れた時点で画面にリアルタイムに表示されていくべき だよな、
そう考えたわけです。
これはイメージ的には、それぞれ1アプリケーションと1Collectionのひとまとまりが、1マイクロサービスのような形になっています。
ちなみに、この設計にできたのは、そもそも僕が、最初にFirestoreを使い始めるときに、RDBのようにある程度正規化していたためです。
最初にその設計になっていないと、やろうとしても他のデータが混ざってできない気がします。
良かったこと
当たり前ですが、実装がめちゃくちゃシンプルになって、かなり突貫でつくっていたんですが、汚染なく、ステートレスになりました。
ただ、途中から変えたので、元々あった部分はステートフルが残っていて、最初にこの形にしていなかったのを後悔していました。。
悪かったこと
当たり前ですが、並列性を担保すると、同期が取れにくくなります。
ということは、データの入り方によって種々のパターンが発生してしまいます。
本来nullable、ということに基づいて設計できていれば問題ないのですが、
それをチームでちゃんと理解を浸透させないとリスクを生む、というのが1点。
もう一つは、ただデータを保存するだけならいいけれども、そのデータを元にすぐに他の処理(副作用)を起こそう、という時に、
1つのcollectionのデータだけでは完結しない場合があります。
そうすると、複数のcollectionのデータをまたがるので、こうなるとFirestoreはめちゃくちゃ弱い。
Firestoreにデータが入ってから何かするぞ、というときに、1つのcollectionだけウォッチすればいいわけではないので、
こういう感じになると、複数のcollectionをウォッチしたり、専用に新たにcollectionつくったり、
めちゃくちゃにややこくなるので、
だったら最初っから同期でつくった方がよい!となります。
僕らはそのケースに当てはまったので、突貫でつくったものをリファクタするときに、同期式へ書き換えていったのでした。
わりとこの辺は要件次第ですが、ハマれば強いとおもいました。