この記事は Enigmo Advent Calendar 2018 の19日目の記事です。
はじめに
ネタ何にしようかなぁと思って、
- カジュアルな感じでかつ単発で終わるようなもの
- 検索、自然言語処理関連で何か
- 年末的な何か
ということを踏まえて、
Qiitaチームに日々挙げている自分の作業日報を可視化して2018年の振り返りをしてみることにしました。
私がエニグモに入社したのが今年の2月なので、正確には1年ではないですが、
細かいことは気にせずいきたいと思います。
作業フロー
作業フローとしては、
- Qiita API v2を利用して自分の作業日報の本文と作成日時を取得
- 取得した本文を形態素解析器にかけてキーワードのみを抽出
- 抽出したキーワードをword cloudを利用して可視化
- 可視化したものを見て思い出に浸る
という感じで進めようと思います。
Qiita APIで日報の本文を取得
-
アクセストークンの発行
Qiitaチームからデータを取得するためアクセストークンを発行します -
アクセストークンの利用
- 取得したアクセストークンはAuthorizationリクエストヘッダに指定して利用します。
- 今回はpythonで実装しましたが、curlの場合は下記のような感じで取得できます。
$ curl https://qiita.com/api/v2/authenticated_user/items \
-H "Authorization: Bearer [アクセストークン]"
- 下記のメソッドを定義して日報データを取得します
- APIを利用して20件ずつデータを取得
- 取得したデータはDataframeに突っ込み、不要なデータは取り除く
- 取得した作成日時をDatetimeIndexに設定して、月単位でデータが扱えるようにしておく
def get_report():
BASE_URL = 'https://XXXX.qiita.com/api/v2/items?'
PER_PAGE = 20
# tagで絞り込み
QUERY = 'tag%3A%E6%97%A5%E5%A0%B1%2F%E4%BC%8A%E8%97%A4%E6%98%8E%E5%A4%A7'
curr_page = 1
with open('qiita_access_token.txt') as f:
qiita_access_token = f.read().strip()
header = {'Authorization': 'Bearer {}'.format(qiita_access_token)}
# レスポンスヘッダを見てページング処理
df_list = []
total_cnt = 0
while(True):
target_url = '{0}page={1}&per_page={2}&query={3}'.format(BASE_URL, curr_page, PER_PAGE, QUERY)
req = urllib.request.Request(target_url, headers=header)
res = urllib.request.urlopen(req)
if curr_page == 1:
# ヘッダから全投稿数を取得
total_cnt = int(res.info()['Total-Count'])
# 最終ページの計算
if total_cnt % PER_PAGE == 0:
last_page = total_cnt // PER_PAGE
else:
last_page = total_cnt // PER_PAGE + 1
res_body = res.read()
res_dict = json.loads(res_body.decode('utf-8'))
# dataframeに変換
df_list.append(pd.io.json.json_normalize(res_dict))
# 最終ページチェック
if curr_page == last_page:
break
curr_page+=1
# df_listを結合
report_df = pd.concat(df_list, ignore_index=True)
# 必要なデータのみ抽出
report_df = report_df[['body', 'created_at']]
# created_atの文字列をdate型に変換
report_df['created_at'] = pd.to_datetime(report_df['created_at'])
# DatetimeIndexに変換
report_df.set_index('created_at', inplace=True)
return report_df
形態素解析器でtokenize&前処理
- janome(辞書はneologd)を利用し、前処理として下記を実施します。
- unicode正規化
- 改行コード削除
- 大文字→小文字に統一
- 名詞のみ抽出(数字は対象外)
def analyze():
# charfilter
## unicode正規化
## 改行コード削除
charfilters = [UnicodeNormalizeCharFilter(),
RegexReplaceCharFilter(u'\r\n', u'')]
# tokenizer
tokenizer = Tokenizer(mmap=True)
# tokenfilter
## 大文字→小文字
## 名詞のみ抽出(数は除去)
tokenfilters = [POSKeepFilter('名詞'), POSStopFilter(['名詞,数']), LowerCaseFilter()]
# analyzer
analyzer = Analyzer(char_filters=charfilters, tokenizer=tokenizer, token_filters=tokenfilters)
return analyzer
def get_word_list(report_list, analyzer):
word_list = []
for report in report_list:
word_list.append(" ".join( analyzed_line.base_form for analyzed_line in analyzer.analyze(report)))
return word_list
可視化処理
word cloudを利用して可視化するためのメソッドを定義します
def draw_wc(vecs_dic, fig_title):
font_path = '/System/Library/Fonts/ヒラギノ角ゴシック W3.ttc'
wordcloud = WordCloud(background_color='white',
font_path = font_path,
min_font_size=15,
max_font_size=200,
width=1000,
height=1000)
wordcloud.generate_from_frequencies(vecs_dic)
plt.figure(figsize=[20,20])
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis("off")
plt.title(fig_title,fontsize=25)
plt.show()
指定した月の日報を可視化する
では実際にやっていきます。
まず、私が入社した月の日報を見てみましょう。
- 1年間分の日報データを取得
df_reports = get_report()
- 可視化したい月を指定
target_month = '2018-02'
- 月の日報をまとめて形態素解析でtokenize
my_analyzer = analyze()
words = get_word_list(df_reports[target_month].body.tolist(), my_analyzer)
- TF-IDFで各単語を重み付け
vectorizer = TfidfVectorizer(use_idf=True, token_pattern=u'(?u)\\b\\w+\\b')
vecs = vectorizer.fit_transform(words)
words_vectornumber = {}
for k,v in sorted(vectorizer.vocabulary_.items(), key=lambda x:x[1]):
words_vectornumber[v] = k
vecs_array = vecs.toarray()
all_reports = []
vecs_dic = {}
for vec in vecs_array:
words_report = []
vector_report = []
for i in vec.nonzero()[0]:
vecs_dic[words_vectornumber[i]] = vec[i]
- 可視化
draw_wc(vecs_dic, target_month)
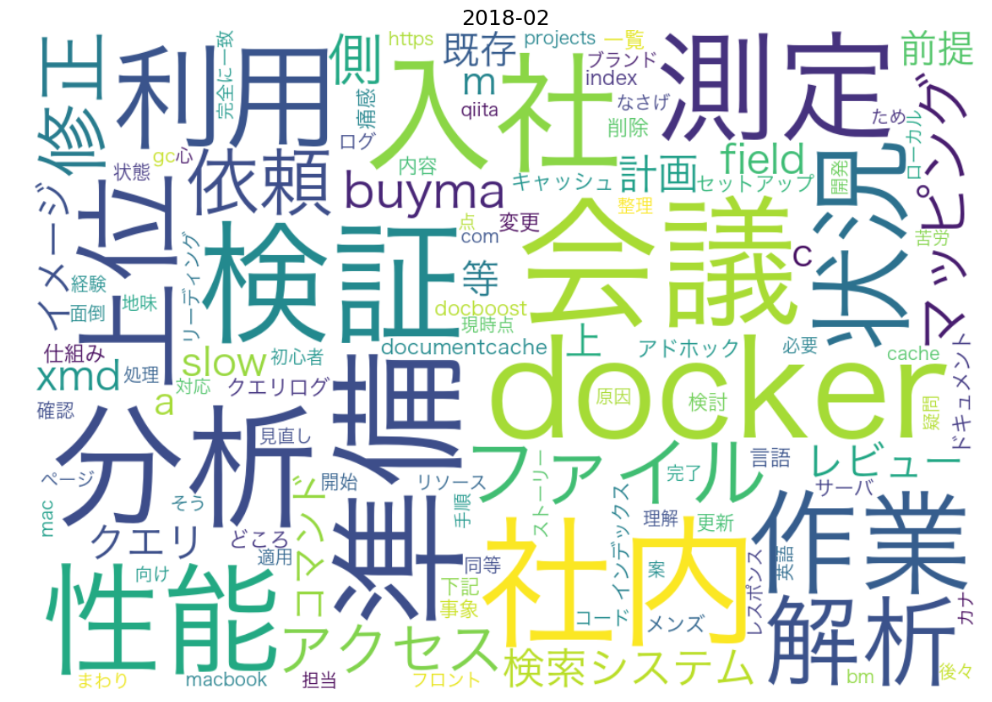
「入社」というキーワードでフレッシュ感がほのかに漂っています。
その他でみると「性能」、「分析」、「検証」、「測定」とかが大きくでてますね。
そういえば、この月は検索システムの性能改善をメインでやっていた気がします。
続いて6月の日報を見てみます。

「韓国」と大きく出てますが、これな何でしょうかね。全く覚えがありません(笑)
「chef」、「レシピ」、「zero」とかはこのあたりでchef zeroで何かの検証をしていたんでしょう。きっと。。
「パーソナライズド」、「fasttext」があるので、この時期あたりからパーソナライズサーチの検証をしてたんだと思います。
最後に11月
他人の日報なんて誰も興味ないと思うので、これで最後にします。
せっかくなのでクリスマスっぽくしてみました。

先月の内容なので、特に振り返ることもありませんが、
Gitlab CI周りの調査/検証やAPIの開発をメインで実施していた時期でした。
おわりに
今回初めてword cloudを使ってみましたが、
視覚的にデータを見るのって新たな気付きがあったりして楽しいですね。
来年はフォントとか画像をもうちょっとオサレな感じにして日報Tシャツ作ってヘビロテしようと思います。