はじめに
暫定テナントから恒久テナントにチーム移行するのに、Wikiをどうしても移行したい。
しかし移行ツールではWikiは移行されない。
TeamsのWikiのエクスポートで四苦八苦する人が多いっぽいがあまり情報がない。
Sharepointでサイトコンテンツを見てみたら、「wikiのデータがmhtファイルとかpngファイルとかで保存されてるから、いい感じになんとかできるかなぁ」と思ってやってみた。
結果、mhtファイルをこねくり回してhtmlファイルとして保存しておくとか、ローカルのOfficeファイル(OneNoteのブック)にコピペするのはできそうだとわかった。
ただ、新しいTeamsにコピペすると、画像部分がコピーされないので、しゅん……。結局1枚1枚画像をコピーして貼り付けを繰り返す必要がありそう。
備忘録として書き記しておく。
やったこと
- SharepointでWikiのmhtファイルとpngファイル等をまとめてダウンロードする
- Chromeで開けるようにmhtファイルをhtmファイルに拡張子を変更する
- Python+Selenium(Chrome)を使ってmhtファイルの画像表示部分のソースを書き換える
- 書き換えたhtmファイルをChromeで開いて、エクスポートしたいローカルのofficeファイルにコピペ
- (もしTeamsWikiにコピーしたいなら、1つ1つ画像をコピーして少しずつ移設する…)
データの取得
チームをSharePointで開いて、サイトコンテンツの中に「Teams Wiki Data」があるのでクリックして開く。

Generalの点々を開いてダウンロードをクリックするとZipファイルでダウンロードできる
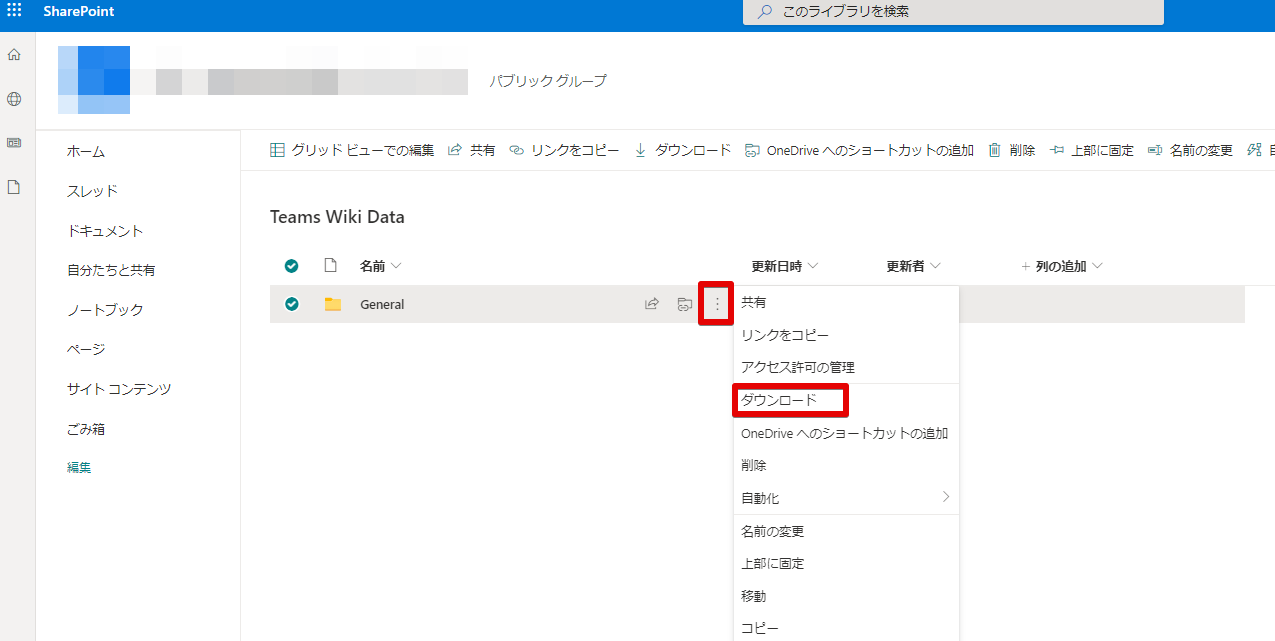
この中には、コピペした画像ファイルがpngで保存されていたり、mhtファイルが保存されている。
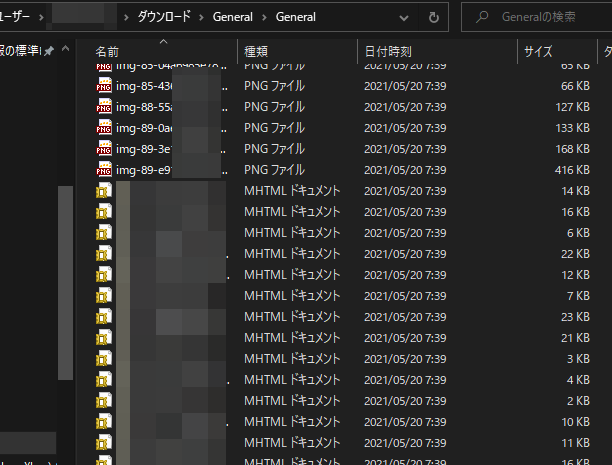
しかし、mhtファイルを開いてもリンクされているわけではなく謎。
mhtファイルを単純にhtmlファイルに拡張子を変えて開いてもリンクが切れてて見れない。
たまに見れるときがあるけど、見れないときもある。うん。
なので、seleniumつかって<img>タグの属性から画像ファイルのパスを引っ張ってきて、PNG画像ファイルを相対パスで表示させてみてはどうかと思い、pythonでなんとかしてみる。
python+seleniumを使ってmhtファイルをこねくり回す
ソースは以下の通り
from selenium import webdriver
from selenium.webdriver.common.by import By
import os
import glob
# Generalフォルダ内にあるmhtファイルをhtmファイルにリネームする
[os.rename("General/"+fn,"General/"+fn[:-4]+".htm") for fn in glob.glob("General/*.mht")]
# 変換対象のhtmlファイルの絶対パスのリストを作っておく
files=[os.path.abspath(x).replace("\\","/") for x in glob.glob("General/*.htm")]
# ChromeDriverを立ち上げておく。chromedriverは同一フォルダ内に置いて相対パスで指定。
driver = webdriver.Chrome(executable_path='chromedriver_win32/chromedriver.exe')
# 全てのファイルに対して以下を実行する
for file in files:
print(file)
#fileを開く
driver.get("file:///"+file)
#imgエレメントを探す
elements = driver.find_elements_by_tag_name("img")
#data-preview-srcの属性を持ってきて、"/"区切りの末尾データ(=PNG画像ファイルの名前部分)だけを取得し、
#置換用の文字列を作っておく
s=[element.get_attribute("data-preview-src") for element in elements]
s=[e.split("/")[-1] if e is not None else "" for e in s ] #(((おまじない
s=['<div><img src="'+x+'"></div>' for x in s]
#元々のimgタグで表示されている画像の高さを0にするための工夫も施しておく
h=[element.get_attribute("height") for element in elements]
h=['height="'+x+'"' for x in h]
#ファイルを1行ずつ読み込んでreplaceで文字列を置換する(笑
lines=[]
n=0
x='<div><span contenteditable="false"><img alt data-preview-src='
with open(file, mode='rt', encoding='utf-8') as f:
for line in f:
if x in line:
line=line.replace(x,s[n]+x).replace(h[n],'height="0"')
n=n+1
lines.append(line)
#書き換えた文字列を使って新しいファイルを作る
with open(file[:-4]+"_copy.htm",mode="w",encoding="utf8") as f:
f.writelines(lines)
できあがったhtmlファイルを使ってさらにこねくりまわす
- ワクワクした気持ちで、新しく作ったhtmlファイルをChromeで開く
- コピーしたい部分をドラッグアンドドロップで選択してCtrl+Cする
- ブラウザ版TeamsでOneNoteのブックを作って貼付ける
- 画像の部分はお豆腐になることに絶句する(白目
- しくしく泣きながらhtmlファイルの画像を右クリックして「画像をコピー」して1枚ずつ丁寧にコピペし、かつお豆腐を消す
- かんせい!
おわりに
おうちかえりたい(白目)
いま宗教上の理由によりブラウザからしか使えないんですが、デスクトップアプリ版使えると悩まなくて済むようになるんですかね。