概要
Seleniumで、以下のようにセル結合されたテーブルをいい感じに読み込みたい。
今回は、横方向に結合されたテーブルを対象とし、データの補完も左方向に補完して読み込みたいケースを想定しています。
インプット
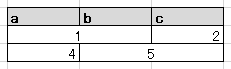
table.html
<table id="tbl">
<tr>
<td> a </td>
<td> b </td>
<td> c </td>
</tr>
<tr>
<td colspan=2> 1 </td>
<td> 2 </td>
</tr>
<tr>
<td> 4 </td>
<td colspan=2> 5 </td>
</tr>
</table>
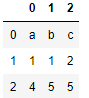
得たいアウトプット
実装
pandasのread_htmlを使います。
※参考にした記事:https://stackoverflow.com/questions/60823159/parsing-nested-td-and-colspan-elements-in-an-html-table-with-selenium-python
# seleniumでサンプルのhtmlファイルを読み込む
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path = '<<<CHROMEDRIVER>>>')
driver.get(r'C:\Users\<<<USERNAME>>>\Desktop\table.html')
# seleniumのfind_elementでテーブル要素を探してHTMLテキスト化して
table_id = driver.find_element(By.ID, 'tbl')
tabletext = table_id.get_attribute('outerHTML')
# pandasのread_htmlでDataFrameに変換する
import pandas as pd
df = pd.read_html(tabletext)
df = df[0]
df
# 0 1 2
# 0 a b c
# 1 1 1 2
# 2 4 5 5
失敗例
いままでセルのデータを各セルごとに走査してしまっており、うまくいってませんでした。(そもそもこれもあんまりですけど…)
どうにかしてcolspanの情報を取ってこないとダメなのかなぁとか、悶々としていましたが、先述の記事みて目から鱗ボロボロでした。
table_id = driver.find_element(By.ID, 'tbl')
rows = table_id.find_elements(By.TAG_NAME, "tr")
r_data = []
for i, row in enumerate(rows):
cols = row.find_elements(By.TAG_NAME, "td")
c_data = []
for j, col in enumerate(cols):
c_data.append(col.text)
r_data.append(c_data)
r_data
# [['a', 'b', 'c'], ['1', '2'], ['4', '5']]
まとめ
pandasってしゅごい
※行方向にセル結合されたものとかは検証していません。