前回までやったこと
前回まで、kaggleのタイタニック号の生存予測のデータ確認と前処理、さらにlightGBMによる訓練・予測を実施した(以下の記事に詳細記載)。
- https://qiita.com/tasuku303/items/becded4c6ec73d72ddbc
- https://qiita.com/tasuku303/items/e942227823fd0838018c
これらを踏まえ、今回は特徴量変換から学習の仕方、モデル評価等を少し変更し再度予測してみました。
今回行ったこと
概要
今回、新たに行ったことは以下の通りです。
- LabelEncoderの利用
- TrainingAPIからScikit-learnAPIへの変換
- 交差検証の分割数の変更(10->30)
- 学習曲線のプロット
- 変数重要度の算出
LabelEncoder
# trainデータ読み込み
import pandas as pd
from sklearn.preprocessing import LabelEncoder
train = pd.read_csv('train.csv')
train_p = train.copy()
feature_name = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
train = train[feature_name]
lr = LabelEncoder()
train["Sex"] = lr.fit_transform(train["Sex"])
train["Embarked"] = lr.fit_transform(train["Embarked"])
# 説明変数と目的変数に分離
X = train
y = train_p.iloc[:, 1:2]
#testデータ読み込み
test = pd.read_csv('test.csv')
test_p = test.copy()
test = test[feature_name]
test["Sex"] = lr.fit_transform(test["Sex"])
test["Embarked"] = lr.fit_transform(test["Embarked"])
前回、特徴量においてカテゴリ変数である「Sex」と「Embarked」に関しては、one-hotエンコーディングを利用しました。one-hotでは、カテゴリ変数の各カテゴリに0,1の二値変数を作成します。その結果カテゴリ変数を学習に反映させることができますが、0が多い疎行列になってしまうこと、カテゴリ数が多いと変数が大量に作られてしまうことが欠点です、、、
それに対して、LabelEncoderは各カテゴリに数値を割り当てる手法です。欠点は、数値自体に本来意味はないのですが、モデルによってはその大小関係を学習に組み込んでしまうため、影響が出てしまうことであリます。そのため、決定木をベースにした手法のように分岐を繰り返して予測値に反映するようなモデルで用いらます。今回は、lightGBMを利用しており、決定木ベースの手法であるためLabelEncoderに変更しました!
Scikit-learnAPI
lightGBMには、TrainingAPIとScikit-learnAPIがあり、前回はTrainingAPIを利用した。しかし、特徴量を再検討した段階で、パラメータの設定がよくなかったのかうまく訓練が出来なくなってしまったため、学習曲線のプロットや交差検証等をscikit-learnで手軽にやりたかったため、Scikit-learnAPIを利用しました。この二つの手法の違いは、以下の記事に詳しく記載されているが、TrainingAPIの方が細かい調整等ができるそうです!
k分割交差検証
k分割交差検証は、モデルにとって学習不足と過学習の適切なバランスをとるためにモデルを評価する手法です。前回はk=10で交差検証しましたが、今回は30に増やして実施しました。分割数を増やすと訓練データが増えるため学習を効率的に行えるメリットがある一方で、計算時間の増大や過学習のリスクがあるためデータセットの規模から大まかな値を決めます。コードは以下のようになります。
# optunaによる最適化
from sklearn.model_selection import cross_validate
from lightgbm import LGBMClassifier
import optuna
def objective(trial):
learning_rate = trial.suggest_loguniform("learning_rate", 0.01, 10)
n_estimators = trial.suggest_int("n_estimators", 10, 2000)
num_leaves = trial.suggest_int("num_leaves", 3, 10),
reg_lambda = trial.suggest_loguniform("reg_lambda", 1e-3, 1e+2)
lgb = LGBMClassifier(learning_rate = learning_rate,
n_estimators = n_estimators,
num_leaves = num_leaves,
reg_lambda = reg_lambda,)
result = cross_validate(estimator=lgb, X = X, y = y,
cv = 30, scoring="accuracy" )
val_accuracy = result["test_score"].mean()
return val_accuracy
optuna.logging.set_verbosity(optuna.logging.WARNING)
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials =100)
study.best_params, study.best_value
# 最適パラメータで訓練・予測
from sklearn import metrics
lgb = LGBMClassifier(learning_rate=study.best_params["learning_rate"],
n_estimators=study.best_params["n_estimators"],
num_leaves = study.best_params["num_leaves"],
reg_lambda=study.best_params["reg_lambda"])
lgb.fit(X, y)
pred_train = lgb.predict(X)
print('訓練データの正解率: ', metrics.accuracy_score(y, pred_train))
pred_test = lgb.predict(test.values)
df = pd.DataFrame({"PassengerId": test_p["PassengerId"], "Survived": pred_test})
df.to_csv('submission.csv', index=False)
訓練データの正解率: 0.8608305274971941
Scikit-learnAPIに変更したことで、scikit-learnと同じようにcross_validateメソッドやこの後登場するlearn_curveメソッドを利用できるので、個人的には使いやすいと感じました。訓練データの正解率は約86%でした。そして、提出した結果は、、、
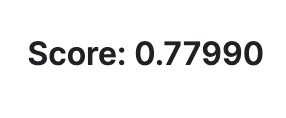
約78%...!! ちょっとだけ、上がりました(笑)一応今回の学習の様子を学習曲線で確認しておきます。
学習曲線
# 学習曲線
from sklearn.model_selection import learning_curve
import numpy as np
import matplotlib.pyplot as plt
lgb = LGBMClassifier(learning_rate=study.best_params["learning_rate"],
n_estimators=study.best_params["n_estimators"],
num_leaves = study.best_params["num_leaves"],
reg_lambda=study.best_params["reg_lambda"])
train_sizes, train_scores, test_scores = learning_curve(estimator = lgb, X=X, y = y, train_sizes=np.linspace(0.1, 1.0, 10), cv=10, n_jobs=1)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(train_sizes, train_mean, color="blue", marker="o", markersize=5, label = "Training accuracy")
plt.fill_between(train_sizes, train_mean + train_std, train_mean - train_std, alpha=0.15, color="blue")
plt.plot(train_sizes, test_mean, color="red", marker="s", markersize=5, label = "Validation accuracy")
plt.fill_between(train_sizes, test_mean + test_std, test_mean - test_std, alpha=0.15, color="red")
plt.grid()
plt.xlabel("Number of training examples")
plt.ylabel("Accuracy")
plt.legend(loc="lower right")
plt.ylim([0.5, 1.0])
plt.tight_layout()
plt.show()
学習曲線は、モデルが学習不足と過学習を起こしているか調べるためにプロットします。scikit-learnのlearn_curveメソッドを利用して、プロットしました。求めた学習曲線は以下のようになりました。
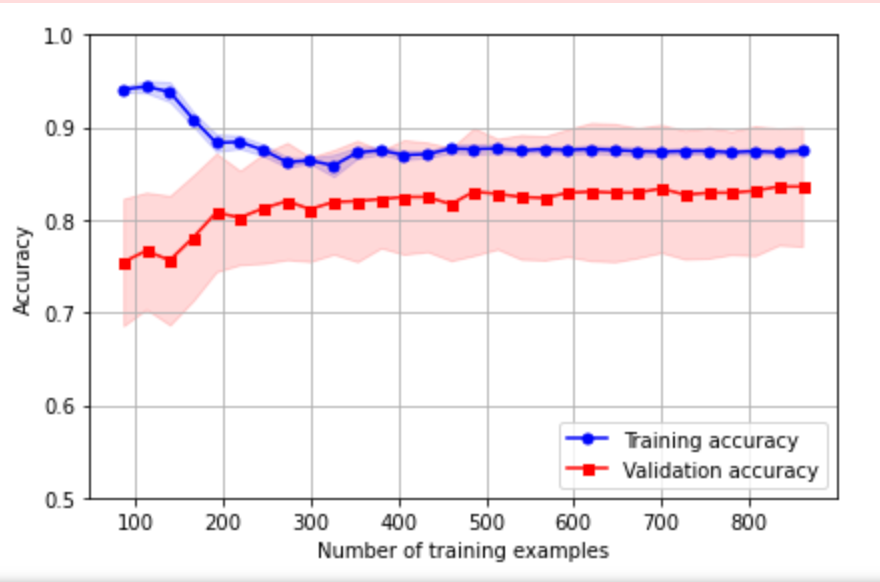
このグラフは、縦軸に正解率、横軸に訓練データの個数を表しています。青線が訓練データで赤線が検証用データを表しています。学習不足が起きている場合、両方とも正解率が低くなります。一方、過学習が起きている場合二つの曲線の幅が広くなってきます。また、平均正解率の標準偏差を帯状にプロットしています。今回は、学習曲線が適切に収束しているのでモデルは問題なく学習できていると判断しました。
変数重要度
# 変数重要度
importances = lgb.feature_importances_
importances = importances / np.sum(importances)
indices = np.argsort(importances)
plt.barh(np.asarray(feature_name)[indices], importances[indices], color="r", align="center")
plt.show()
変数重要度はlightGBMにおける各特徴量の重要度を算出した値です。
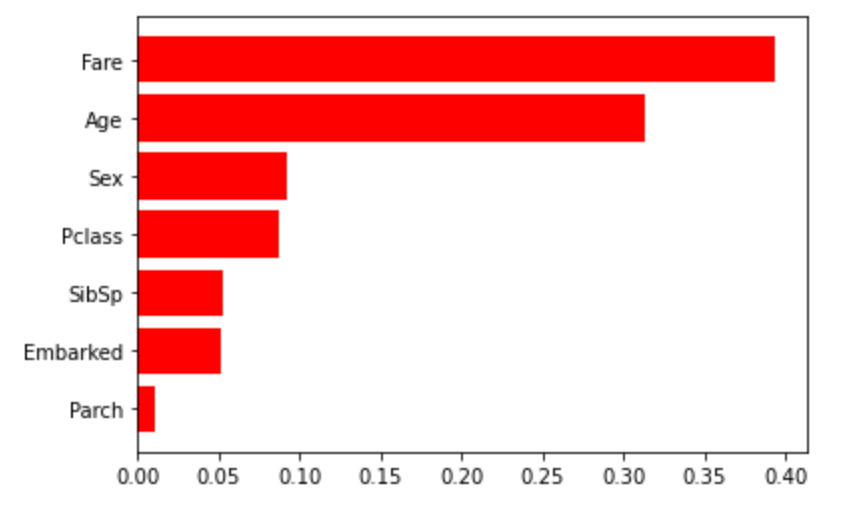
今回は、FareやAgeが高くParchが低くなっていました。ただし、この変数重要度が低いからという理由で、その特徴量を削除してもモデル予測精度が上がるとは限りません。Parchに関してはSibSpと関連づけて考えられそうなので、特徴量を再検討してみたいです!
まとめ
- 今回は特徴量変換とモデル評価を少し工夫しましたが、モデルが正しく学習できているかを把握することや特徴量の扱いの大切さを再確認しました。
- 今後は、扱っていない特徴量を深くみていきたいと思います。