他の記事を探してもなかなか行方向で特定文字列を集計するやり方を書いてある記事がなかったので、
試行錯誤した内容を記載します。
データの準備
データの準備
import pandas as pd
list = [['a', 'c', 'a', 'a'],
['b', 'a', 'b', 'b'],
['b', 'c', 'a', 'a'],
['c', 'a', 'b', 'b']]
df = pd.DataFrame(list, columns = ['first', 'second', 'third', 'forth'])
df

今回はこのデータのを行向きの文字列aとbをカウントしてcountという列に集計結果を追記していきます。
転置させる
データの転置
# 転置する
df_T = df.T
df_T
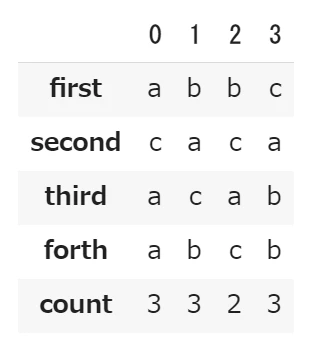
置換してカウントの準備
replaceはオブジェクトで複数文字を置換できるので、
カウントしたい文字列をTrueへ変換する。
カウントしたい文字の置換
# replaceでカウントしたい文字をTrueに変更
replacer = {'a': True, 'b': True}
df_T = df_T.replace(replacer)
df_T
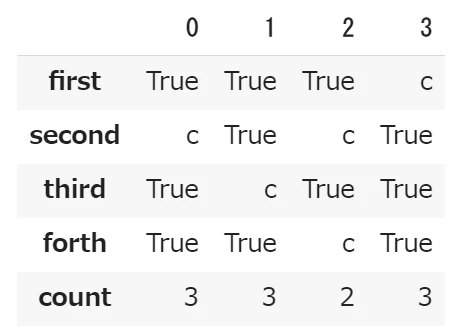
カウントさせる
カウントしたい文字の置換
(df_T[df_T.columns.tolist()] == True).sum()

カウントさせた内容を元のデータの新しい項目に追加させる
上記の内容を元のデータフレームの新しい項目に追加させる
カウントさせたのも元のデータの項目に追加させる
df['count'] = (df_T[df_T.columns.tolist()] == True).sum()
df

全体のコード
全コード
import pandas as pd
list = [['a', 'c', 'a', 'a'],
['b', 'a', 'c', 'b'],
['b', 'c', 'a', 'c'],
['c', 'a', 'b', 'b']]
df = pd.DataFrame(list, columns = ['first', 'second', 'third', 'forth'])
df_T = df.T
replacer = {'a': True, 'b': True}
df_T = df_T.replace(replacer)
df['count'] = (df_T[df_T.columns.tolist()] == True).sum()
もっと良い方法があれば追記していきます。