概要
運用環境でない場合、AWS RDSを常時起動していると、コスト高になってしまうと感じたため、必要な時のみ起動するようにしました。RDSのスナップショットを保存しておき、コンソールから手動で立ち上げても問題はないですが、AWSのサービスを使ってみたい思いもあり、他サービスとの連携してボタン一つで完了するように試してみました。
手順
初めに、RDSのスナップショットを作成。
次に、RDSを操作するLambda関数の作成。
最後に、Lambda関数のコールを行うStepFunctionsの作成。
を行います。
(1)RDSのスナップショット作成
対象となるRDSのスナップショットを作成します。
今回は、Amazon AuroraのPostgreSQL互換性のものでクラスターを生成、クラスター内にインスタンスを1つ作成したものを対象のRDSとします。
スナップショットはRDSのページから作成することが可能です。
※クラスターのスナップショットを生成すると、RDSのデータも合わせて保存されます、クラスター内のインスタンスに対してスナップショットを取得する必要はありません。
もしくは、Lambda関数からpythonを用いて、以下のような関数を作成し、作成することが可能です。
snapshotidは生成するスナップショットの名前、instanceは生成するスナップショット対象元のクラスター名です。
import boto3
rds = boto3.client('rds')
def create_db_cluster_snapshot(snapshotid, instance):
# スナップショット作成処理
rds.create_db_cluster_snapshot(
DBClusterSnapshotIdentifier=snapshotid,
DBClusterIdentifier=instance
)
※関数のみ表記 def lambda_handler(event, context):は省略
上記は、RDSのクラスターに対してスナップショット作成を行います。インスタンスに対してではないです。
(2)RDSを操作するLambda関数作成
下記に示す4つのLambda関数には、それぞれ、ロールの権限付与で、RDSのアクセスを付与してください。
① RDSクラスターのスナップショットからRDSを復元する関数(restore_db_cluster_from_snapshot)
import json
import boto3
rds = boto3.client('rds')
# クラスターのスナップショットよりDB復元関数
def restore_db_cluster_from_snapshot():
rds.restore_db_cluster_from_snapshot(
AvailabilityZones=['ap-northeast-1a'],
DBClusterIdentifier='XXX',#復元後のDBクラスター名
SnapshotIdentifier='XXX',#復元するスナップショット名
Engine='aurora-postgresql',
EngineVersion='10.7',
Port=5432,
DBSubnetGroupName='XXX',# DB作成時に合わせて作ったサブネットグループ名
DatabaseName='postgres',# DB名がデフォルトではpostgresですが違いがあれば変更
VpcSecurityGroupIds=[
'XXX' #セキュリティグループを設定。複数設定可
],
KmsKeyId='XXX', #keyIDを設定
DBClusterParameterGroupName='default.aurora-postgresql10'
)
def lambda_handler(event, context):
# DBの復元
restore_db_cluster_from_snapshot()
return {
'status': 'OK'
}
※エラー処理までは入れておりませんので、OK応答にしてしまいます。
DB復元時の設定は最小限設定しておく必要があると思ったものを入れてます
詳細は、下記ドキュメントで関数を確認ください。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/rds.html
②RDSクラスターのステータスチェック関数(get_describe_db_clusters)
RDSの復元には時間が掛かります。
そのため、起動完了しDBクラスターが使用可能となっているか、ステータス確認用の関数を作成します。
import json
import boto3
rds = boto3.client('rds')
# 引数指定したDBクラスターのステータス情報取得
# 引数: db_name フィルタリングに使用
def get_describe_db_clusters(db_name):
rds_info = rds.describe_db_clusters(
DBClusterIdentifier=db_name)
status=rds_info['DBClusters'][0]['Status']
return status
def lambda_handler(event, context):
# DBクラスターのステータス確認(引数は、クラスター名を入れる)
status=get_describe_db_clusters('XXX')
# StepFuncitonへの戻り値はjson 形式にする
return {
'status': status
}
※本来、StepFunctionからのInputでDBクラスター名を指定した方がスマートなやり方だと
思いますが、今回はLambda関数内でクラスター名を記述しております。
③DBクラスター内インスタンスを生成する(create_db_instance)
import json
import boto3
rds = boto3.client('rds')
# クラスター内部のインスタンス作成関数
def create_db_instance():
rds.create_db_instance(
DBInstanceIdentifier='XXX', # 生成するインスタンス名称
DBInstanceClass="XXX", #DBインスタンスサイズ
Engine='aurora-postgresql',
DBClusterIdentifier='XXX' #クラスター名称
)
def lambda_handler(event, context):
create_db_instance()
# StepFuncitonへの戻り値はjson 形式にする
return {
'status': 'OK'
}
④RDSクラスター内のインスタンスステータスチェック関数(get_describe_db_instances)
②と同様、インスタンスも生成に時間が掛かります。
インスタンスの利用が可能か否かのステータス確認用の関数を作成します。
import json
import boto3
rds = boto3.client('rds')
# 引数指定したDBインスタンスのステータス情報取得
# 引数: instance_name フィルタリングに使用
def get_describe_db_instances(instance_name):
rds_info = rds.describe_db_instances(
DBInstanceIdentifier=instance_name)
status=rds_info['DBInstances'][0]['DBInstanceStatus']
return status
def lambda_handler(event, context):
status=get_describe_db_instances('XXX')
# StepFuncitonへの戻り値はjson 形式にする
return {
'status': status
}
(3)Lambda関数のコールを行うStepFunctionsの作成
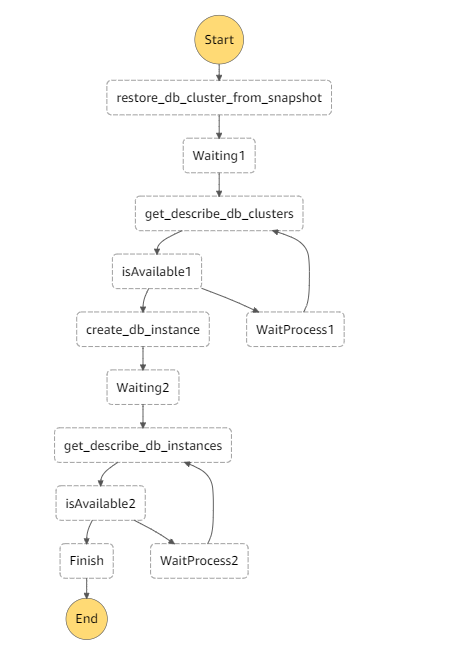
StepFunctionのページより、ステートマシンを作成し、以下のような処理を記載します。
Lambda関数のARNは、アカウント単位で異なりますのでLambda関数のページより参照し記載します。(下記は東京リージョンのARNとなっています)
フロー概要
・スナップショットからDBクラスターを復元し、復元完了までwaitをします。
・DBクラスター生成が完了し、利用可能となれば、DBクラスター内のインスタンスを生成します。
まだ、クラスターが利用可能(available)となってなかれば、一定時間wait後、再度ステータスを確認
・インスタンス生成完了までwaitし、利用可能となれば、処理完了です。(利用可能でなければ、クラスターと同様一定時間wait後再度ステータス確認します)
{
"Comment": "RDSクラスター自動起動処理",
"StartAt": "restore_db_cluster_from_snapshot",
"States": {
"restore_db_cluster_from_snapshot": {
"Comment": "RDSクラスターをスナップショットから復元",
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:XXX:function:restore_db_cluster_from_snapshot",
"Next": "Waiting1"
},
"Waiting1": {
"Comment": "RDSクラスターの生成完了まで待つ(ここでは300secとしている)",
"Type": "Wait",
"Seconds": 300,
"Next": "get_describe_db_clusters"
},
"get_describe_db_clusters": {
"Comment": "RDSクラスターのステータス状態取得",
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:XXX:function:get_describe_db_clusters",
"ResultPath": "$.iterator",
"Next": "isAvailable1"
},
"isAvailable1": {
"Type": "Choice",
"Choices": [{
"Comment": "RDSクラスターのステータス状態をチェックする",
"Variable": "$.iterator.status",
"StringEquals": "available",
"Next": "create_db_instance"
}],
"Default": "WaitProcess1"
},
"create_db_instance": {
"Comment": "RDSクラスターをスナップショットから復元",
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:XXX:function:create_db_instance",
"Next": "Waiting2"
},
"WaitProcess1": {
"Comment": "一定時間Wait後、再度RDSクラスターのステータス状態をチェックする",
"Type": "Wait",
"Seconds": 30,
"Next": "get_describe_db_clusters"
},
"Waiting2": {
"Comment": "RDSクラスター内のインスタンス生成完了まで待つ(ここでは300secとしている)",
"Type": "Wait",
"Seconds": 300,
"Next": "get_describe_db_instances"
},
"get_describe_db_instances": {
"Comment": "RDSクラスター内のインスタンスステータス状態取得",
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:XXX:function:get_describe_db_instances",
"ResultPath": "$.iterator",
"Next": "isAvailable2"
},
"isAvailable2": {
"Type": "Choice",
"Choices": [{
"Comment": "RDSクラスター内のインスタンスステータス状態をチェックする",
"Variable": "$.iterator.status",
"StringEquals": "available",
"Next": "Finish"
}],
"Default": "WaitProcess2"
},
"WaitProcess2": {
"Comment": "一定時間Wait後、再度RDSクラスターのステータス状態をチェックする",
"Type": "Wait",
"Seconds": 30,
"Next": "get_describe_db_instances"
},
"Finish": {
"Comment": "終了処理",
"Type": "Pass",
"Result": "OK",
"End": true
}
}
}
※StepFunctionからLambda関数をコールする際に引数を渡す場合には、
"InputPath": "$", を追記すると、StepFunction実行時の引数(json)を渡すことができます。
上記の記載で作成されたフローが下記となります。
あとは、StepFunctionのページより、実行をすると、RDS自動生成ができるようになります。