旅行予約サイトの「今あなた以外に○○人が見ています」はウソだったことが判明 - GIGAZINEという記事が注目されています。
本記事の内容を要約すると、下記のような内容です。
- Harpaz氏がOneTravelで飛行機の搭乗券を予約しようとした時、「38人がこの搭乗券をチェックしています」と表示された。
- Harpaz氏がJSのソースコードをチェックすると、28から44までの数字がランダムに生成・表示されているだけだった。
こういうやつの話ですね。
では、日頃わたしたちが使う、他のサイトはどのようなロジックになっているのでしょうか。
流石に日本にも進出しているような大手サイトは、OneTravelのようにJSソースからロジックを確認できそうにありませんので、統計的に確認しようと思います。
本記事では、ぱっとみで同様のUIが見つかった、
に言及します。
なかなか興味深い傾向が見えました。
検証方法
データの収集
サイトを1時間程度、なるべく等間隔でSeleniumによってスクレイピングし、閲覧数カウンタ部分を取得する。
データの確認
- その値の時系列変化を確認して、不自然さを確認する
- その値の分布を確認して、不自然さを確認する
食べログの件もそうですが、統計データだけではロジックを断定はできません。
解釈は皆さんにおまかせします。
対象宿泊
各サイト毎に、下記2つの施設についてデータを収集しました。
本来はもっと網羅的に確認したほうが良さそうですが、時間の関係です。
なお、宿泊施設は、筆者がなんとなく泊まりたいところを選びました。
ホテル ニッコー サンフランシスコ / プチ クイーン (Petite Queen) / 11/2~3
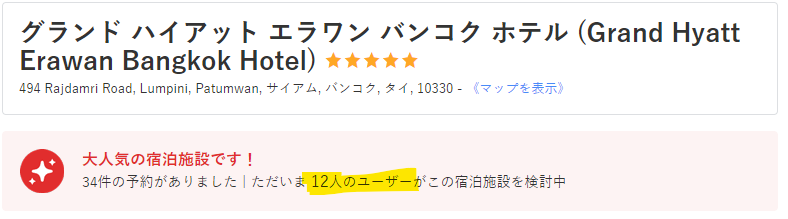
グランド ハイアット エラワン バンコク ホテル / ルーム シングルベッド 2 台 / 11/25~26
タイもまた行きたい国です。寺院はもういいや。
Expedia
Agoda
ソースコード
読み込み速度に依存するので、厳密には一定間隔でありません。
また、10トライアルに1度程度失敗します。
クッキーは、browser.delete_all_cookies()で削除しているはずですが、うまくいってなければご指摘ください。
Expedia
import sys
import urllib.request, urllib.error
import bs4
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import Select
import time
import re
import datetime
import csv
def write_in_csv(file_name, material):
with open(file_name, 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(material)
def collect_data(browser, url):
browser.delete_all_cookies()
browser.get(url)
time.sleep(1)
html = browser.page_source
soup = bs4.BeautifulSoup(html, "lxml")
raw_string = soup.find('span', {'class': 'plural'}).find('strong').string
PATTERN = '.*?(\d+)'
num_of_watcher = int(re.match(PATTERN, raw_string).group(1))
now = datetime.datetime.now()
print(str(num_of_watcher) + " :" + str(now))
return [num_of_watcher, now]
def execute(num_of_trials, url):
browser = webdriver.Chrome(executable_path=[YOUR DRIVER PATH])
options = Options()
options.add_argument('--headless')
results = []
for i in range(num_of_trials):
try:
results.append(collect_data(browser, url))
except:
pass
# 以下書き込み処理
now_date = datetime.datetime.now()
file_name = 'expedia_' + now_date.strftime('%Y-%m-%d_%H%M%S') + '.csv'
write_in_csv(file_name, results)
if __name__ == "__main__":
args = sys.argv
execute(int(args[1]), int(args[2]))
Agoda
import sys
import urllib.request, urllib.error
import bs4
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import Select
import time
import re
import datetime
import csv
def write_in_csv(file_name, material):
with open(file_name, 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(material)
def collect_data(browser, url):
browser.delete_all_cookies()
browser.get(url)
time.sleep(1)
html = browser.page_source
soup = bs4.BeautifulSoup(html, "lxml")
raw_string = soup.find('span', {'class': 'UserEngagement__Count'}).string
PATTERN = '.*?(\d+)'
num_of_watcher = int(re.match(PATTERN, raw_string).group(1))
now = datetime.datetime.now()
print(str(num_of_watcher) + " :" + str(now))
return [num_of_watcher, now]
def execute(num_of_trials, url):
browser = webdriver.Chrome(executable_path=[YOUR DRIVER PATH])
options = Options()
options.add_argument('--headless')
results = []
for i in range(num_of_trials):
try:
results.append(collect_data(browser, url))
except:
pass
# 以下書き込み処理
now_date = datetime.datetime.now()
file_name = 'agoda_' + now_date.strftime('%Y-%m-%d_%H%M%S') + '.csv'
write_in_csv(file_name, results)
if __name__ == "__main__":
args = sys.argv
execute(int(args[1]), int(args[1]))
実行結果
Expedia
ホテル ニッコー サンフランシスコ / プチ クイーン (Petite Queen) / 11/2~3
2019/10/22 0:07:53 ~ 2019/10/22 1:01:06 の1時間について400回取得。(平均8秒/回)
面白い波形になりました。
なんとなく、数字の動きが同じところを下線でまとめています。
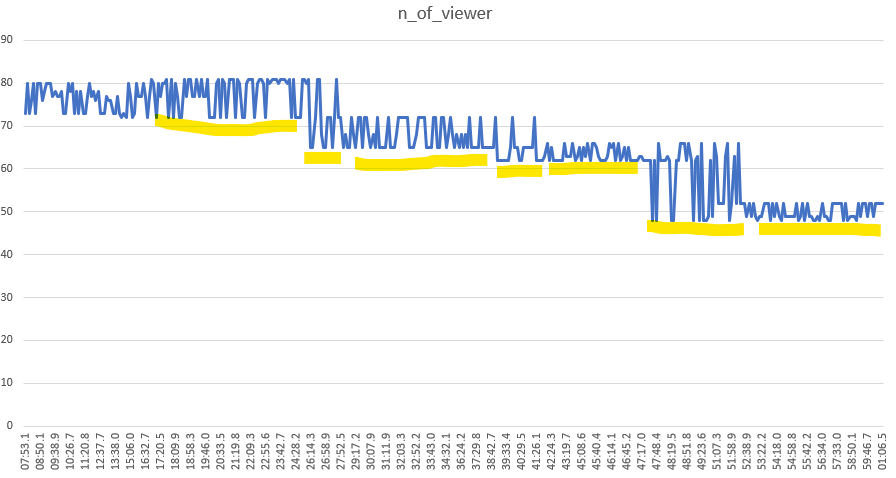
あくまで仮説ですが、一定の期間、同じ上限値と下限値を使いまわしているように見えます。
おそらく、一定の間隔でアクセス人数を測定し、直近2~4回程度をランダムに表示しているのではないでしょうか。
1日スパンで測定するなどすれば、日単位での傾向も見られそうです。
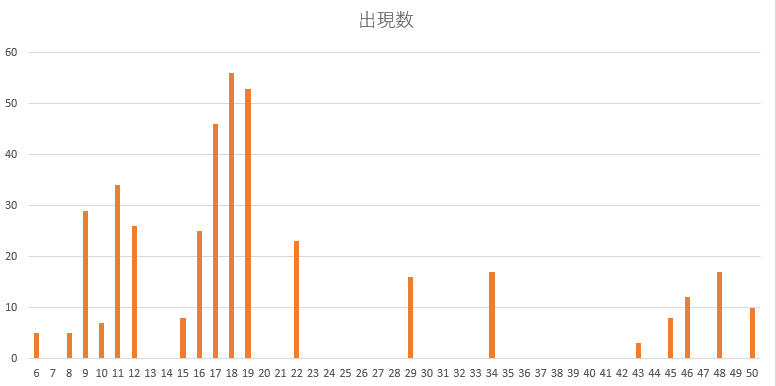
なお、数値ごとの出現回数は下記です(合計400)
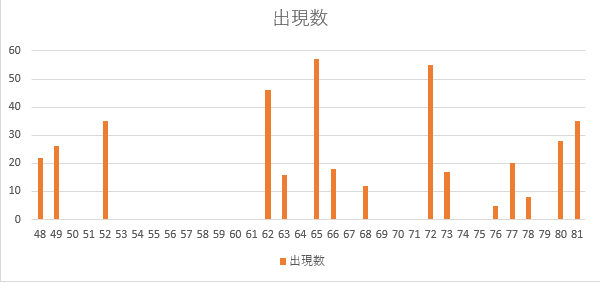
ちょっと解釈に苦しむ分布ですが、時系列折れ線グラフでも示したとおり、連続的というよりかは離散的です。
特に、52~62の間がぽっかりと抜けている点は不自然です。
(2019/10/22 0:47:39~2019/10/22 0:52:17の5分間付近)
グランド ハイアット エラワン バンコク / シングルベッド 2 台 / 11/25~26
2019/10/22 1:04:42 ~ 2019/10/22 2:22:13 (平均11.7秒/回)
解釈のむずかしい波形になりました。
基本的には、ホテルニッコーの結果と変わりません。
取得開始時点では10付近だった閲覧数が、最終的に50に跳ね上がった点は、ちょっと不思議な動きです。
なんとなく、安定期と不安定期を繰り返しているようにも見えますが、背景にどんなロジックがあるのでしょうか。
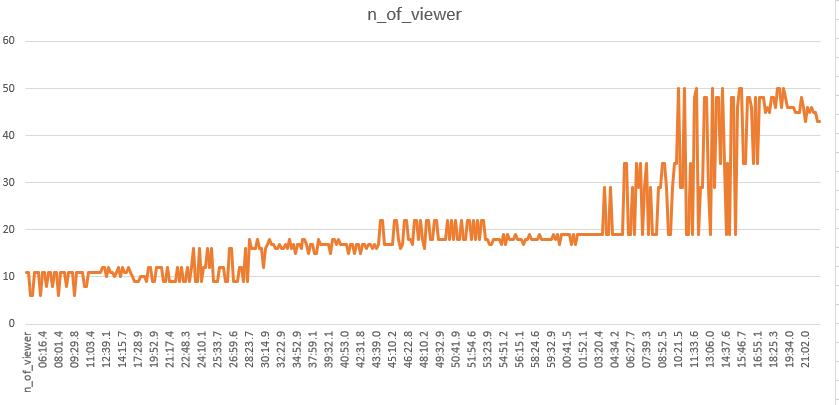
出現数も、いまいちとらえどころがないですね…
離散的である点については、先程の分析も踏まえると、間違い無さそうです。
なお、データは割愛しますが、同時間帯に複数プロセスでスクレイピングした場合、両者の出力結果は時間帯毎にほぼ同じ上限/下限値を取ります。
Agoda
ホテル ニッコー サンフランシスコ
2019/10/21 23:40:49 ~ 2019/10/22 0:44:56 の1時間について867回取得。(平均4.5秒/回)
グラフ描写するまでもなく、ずっと「7」
グランド ハイアット エラワン バンコク
2019/10/22 1:01:22 ~ 2019/10/22 2:32:07 (平均7.3秒/回)
ビジュアライズするまでもなく、ずっと「12」
かとおもいきや、数字が遷移する現象が起きました。
ずっと12だったのですが、20分程度5が混ざる期間が続き、最終的に5に落ち着きました。
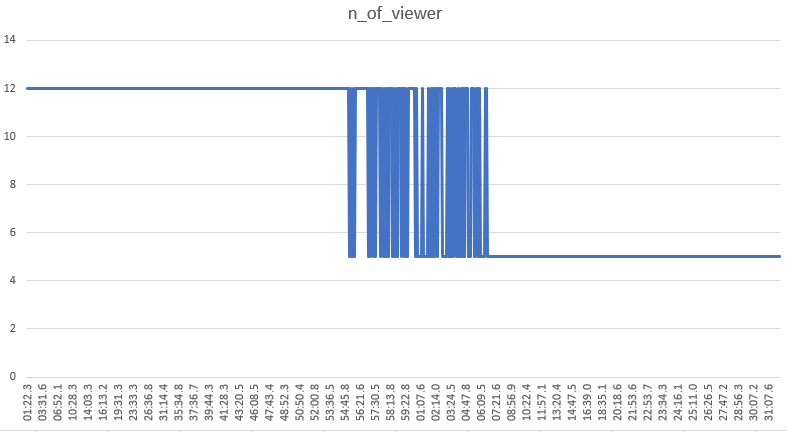
これは解釈が難しいですね…
少なくとも、当該サイトは、閲覧者数のリアルタイム性が高くないということは言い切って良いでしょう。
とはいえ、更新頻度が低いからといって、ランダム/非ランダムを混在させる理由はいまいちピンときません。低い更新頻度を補う演出としてのランダムであれば、Expedia的に常に一定程度のランダム性をもたせるのが良いように感じます。
結論
どのサイトも、真にリアルタイムな閲覧者数を表示しているわけでは無さそうです。
そもそもサイトごとのリアルタイムな閲覧者数を表示するというのは、技術的にも負荷が高そうですし、ある程度の不正確性は仕方のないものなのでしょう。
とりあえず、海外旅行行きたいです。