こんにちは。Droonga開発チームの結城(Piro)です。
Groonga Advent Calendar 13日目は、9日目に引き続き、Droongaを肴にした分散処理の初歩の初歩の解説です。
ここまで、分散の3つのメリットを解説してきました。
- 負荷の分散により、1台のマシンの性能の限界を超えた処理が可能になる。
- リスクの分散により、可用性が高まる。
- データの分散により、今までは扱いきれなかった量のデータを扱えるようになる。
1つ目のメリットについては6日目の記事、2つ目のメリットについては7日目の記事で解説しました。
最後の3つ目のデータの分散については、9日目の記事で大まかな概念を解説しました。
この記事ではその後半として、検索クエリの分散と結果の集約について解説したいと思います。
検索結果の集約
前回の記事では、Droongaではデータを分散して格納しているパーティション群を対象とした検索リクエストに対して、各パーティションに検索リクエストを分散転送し、それぞれで検索処理を行うという事を述べました。
そして、そのパーティション群が返した検索結果を集約すれば、1つの巨大なデータベースを対象に検索したのと同じ結果を得られるという事も述べました。
しかし、バラバラの検索結果を1つに集約するとは一体どういう事なのでしょうか?
様々な集約の方法
単純な連結
最も単純な集約の仕方は、それぞれのパーティションの検索結果を単に連結するという物です。
以下に、果物の情報を格納した3つのパーティションでの検索結果を集約する例を図示します。
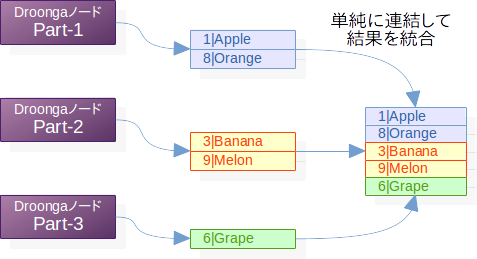
見ての通り、異なるレコードからなる2件・2件・1件の3つの検索結果から、5件のレコードを持つ1つの検索結果ができあがりました。
ソート順が指定されていないのであれば、このままクライアントに検索結果を返して大丈夫です。簡単ですね。
Droongaでは、こういった処理はReducerやCollectorと呼ばれるモジュールが担当しています。
Reducerは、すべてのパーティションが検索結果を返すのを待ちながら、出てきた物から順に検索結果を集約していきます。
すべての結果が出揃ってReducerが処理を終えたら、Collectorが結果を最終的な形にまとめ上げて返却します。
ソート順を保った集約
ソート順が指定されている検索クエリの場合は、先のような単純な連結ではまずいです。
検索クエリでソート順が指定されている場合、個々のパーティションから返される検索結果はそれぞれ既にソートされた状態になっています。
これをソート順を保ちながら集約する方法はいくつかありますが、Droongaではマージソートを使っています。
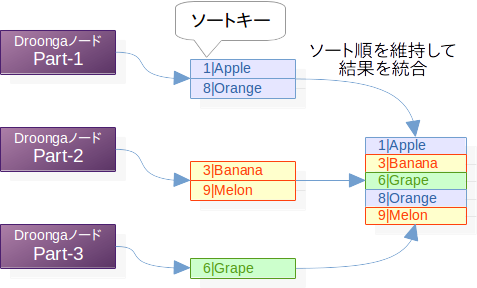
マージソートはバラバラのデータを効率よくソートするためのアルゴリズムの一種ですが、その中で、「2つのソート済み配列を、ソート順を保ったまま1つにまとめる」という処理が行われます。
この性質を利用すれば、ソート済みの複数の検索結果を効率よくまとめられるというわけです。
データの内容も含めた集約
これで一安心と言いたいところですが、ドリルダウンが絡むと話はさらにややこしくなります。
ドリルダウン結果の場合、それぞれのパーティションが返した結果の中には意味が重複している物が出てくることがあります。
その場合、それらについてはきちんと意味を把握して、内容のレベルで1つにまとめなくてはなりません。
_nsubrecsの値も、それぞれの結果の値を集計する必要があります。
以下は、果物の情報を検索して産地でドリルダウンした結果を集約する例です。
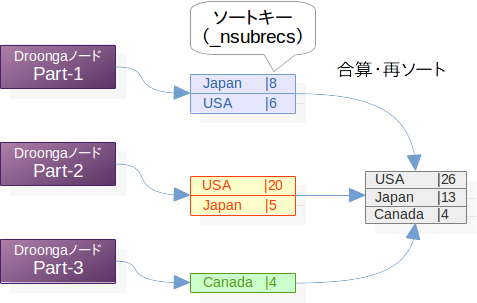
見ての通り、重複する同じ産地のレコードは1つにまとまっており、_nsubrecsの値はすべての結果の合計になっています。
また、値を合計したことでレコードのソート順が変わるため、もう一度ソートし直されています。
それ以外の集約方法
このように、Droongaでは必要に応じていくつかの集約の手法が使い分けられています。
Groonga Advent Calendar 7日目の記事「Droongaで理解する、分散処理の基本のキ:リスクの分散」では、Handlerプラグインを実装することで任意の処理を分散実行できると述べましたが、その際にはHandlerの処理結果をどのように集約するかがポイントとなります。
ReducerやCollectorでの集約の仕方を工夫する事によって、検索のみならず、様々な処理の結果を1つにまとめ上げることができるわけです。
ちなみに、ここまでの説明では省略していましたが、更新リクエストの場合でも処理結果の集約は行われています。
例えばGroonga互換のスキーマ定義コマンドtable_createは、成功時にはtrueを、失敗時にはfalseを返します。
これは実際には、データベースの更新対象となったすべてのレプリカで成功した場合にtrueとなり、1つでもエラーがあった場合にはfalseとなります。
すべての結果の論理積を取る形で結果を集約しているという事ですね。
また、Groonga互換のloadコマンドは更新されたレコードの件数を返しますが、この件数は、各投入レコードについて、1レコードにつき全レプリカで更新に成功したら1、1つでも更新できなかったレプリカがあれば0、と見なした上での合計となっています。
なので、「投入されたデータのレコード数×レプリカ数」にはなりません。
Groonga互換のコマンド群は、模倣の対象であるGroongaが単一サーバで動作するソフトウェアである事から、このようにざっくりと集約された結果しか返さないようになっています。
Droongaネイティブの更新コマンドであれば、このレプリカでこのような理由で更新に失敗した、といった詳細なエラー情報が返されます。
(ただ、諸々の事情から、現時点ではスキーマ変更操作についてはDroongaネイティブのコマンドは提供していません。)
検索リクエストを分散させるための工夫
ここまで、複数の検索結果を集約すると1つの巨大なデータベースでの検索結果と同じになると述べてきましたが、実は、集約の時点でいくら頑張っても絶対に正しい検索結果を得られないケースがあります。
offsetとlimitが指定された検索はその代表例です。
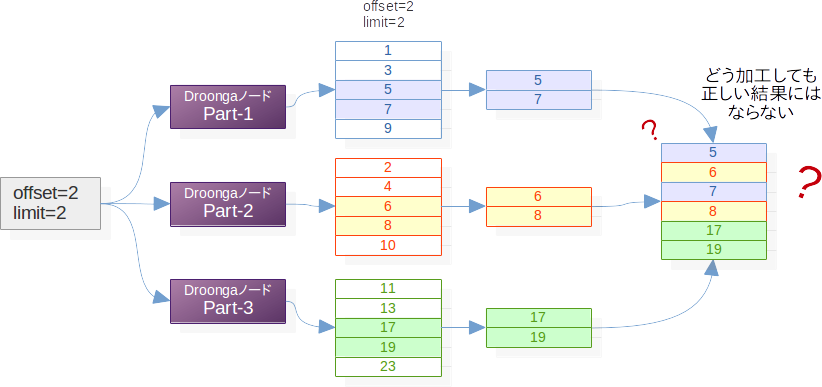
個々のパーティションでの検索時にoffsetとlimitをそのまま適用してしまうと、この図の例のように、本来必要だった検索結果が失われてしまう事があります。
こういった事が起こらないように、パーティショニングされているクラスタを対象にした検索では、単純に同じ検索クエリを分散転送するのではなく、検索クエリを適切に変換してから転送する必要があります。
検索クエリの変換
先程のようなoffsetとlimitが指定された検索クエリは、それぞれのパラメータを一旦書き換えてから分散すれば、正しい結果を得られます。
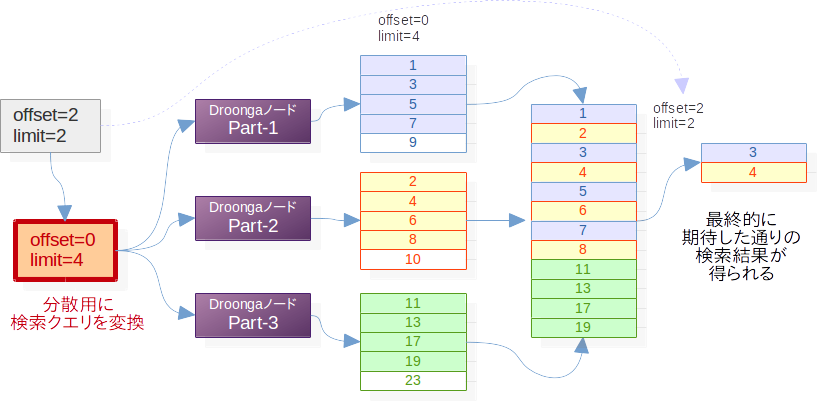
必要な結果が含まれている可能性があるレコードをすべて取り出した上で、集約の時点で元の検索クエリのoffsetとlimitの示す範囲だけを取り出すことで、正しい検索結果になるという具合です。
ただ、この図にも現れている通り、分散処理の途中の検索結果には無駄が多く含まれます。
そのため、パーティショニングを行った場合の検索はどうしてもオーバーヘッドが大きくなりがちです。
(最近のバージョンまでDroongaでの検索処理がGroongaに比べて非常に低速だったのは、このようなパーティショニング用の処理が常に行われてしまっていたためです。現在のバージョンでは、必要ない場合にはこの処理をスキップするようになっているため、パーティショニング無しの場合であればGroongaと比べて同程度のスループット性能を達成できています。)
なお、Droongaでは、このような処理はPlannerやDistributorと呼ばれるモジュールが担当しています。
ReducerやCollectorと同様に、ここを工夫することで、Droongaでは検索以外にも様々な処理を分散実行させることができます。
パーティショニングによる検索処理の最適化
前項で、データを分散させると検索の性能がどうしても落ちてしまう、ということを述べました。
このようなオーバーヘッドは、実はデータの分散のさせ方の工夫によって軽減する事ができます。
ハッシュのキーでデータを分散させた場合、各パーティションには均等にデータがばらまかれるため、検索時には検索クエリの変換と検索結果の集約が必須となります。
しかし、頻繁に行われる検索のパターンがあらかじめ予想できているのであれば、クエリの変換と結果の集約が必要ないような形にデータを分散させることができます。
例えば、データが日付の情報を持っていて、特定の年を対象にした検索が頻繁に行われるという前提がある時には、年単位でのパーティションが有効と考えられます(※データの量によっては、月単位などもっと細かい単位にせざるを得ない事もあります)。
年単位などのように恣意的な基準でデータを分散させると、大抵の場合、各パーティションが持つデータの量にはばらつきが生じます。
これはディスク効率という点では非効率的なのですが、検索する時には大きなメリットになります。
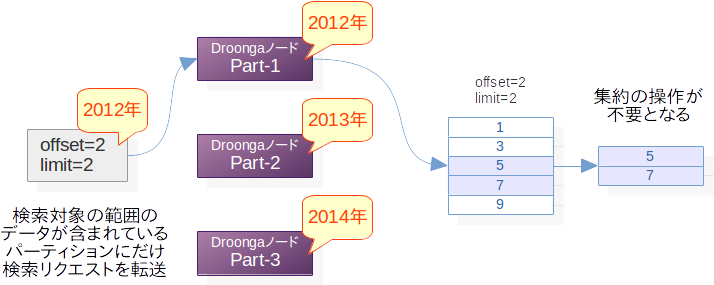
Groongaのselectコマンドでは、queryやfilterで検索の条件を指定できますが、検索条件として年が指定されている場合、パーティションによっては検索処理が全くの無駄足になります。
そのパーティションで検索しても何の結果も得られないことが明らかなのであれば、そもそも、そのパーティションには検索リクエストを転送する必要はありませんよね。
これを突き詰めると、場合によっては、その検索クエリに対する検索処理は1つのパーティションでだけ行えば十分である(そのパーティションだけでの検索結果が、パーティション群全体の検索結果と等しくなる)、という場面すら出てきます。
ここまで来てしまえば、クエリの変換も結果の集約も不要です。
これが、パーティショニングによる検索処理の最適化です。
言ってみれば、あらかじめ簡単な検索を済ませた状態のデータベースを作っておく、といったところでしょうか。
ディスク効率と検索性能のトレードオフ
先に述べた通り、データの分散のさせ方を恣意的に決めると、ディスク効率という点では無駄が大きくなります。
また、「その分散のさせ方と相性のいい検索クエリ(年ごとの分散に対する、年ごとの検索、といった具合に)」以外に対しては、相変わらずクエリの分散と結果の集約が必要です。
リソースが無尽蔵にあって、検索性能を何よりも大事にしたいのであれば、想定される検索のパターンに合わせて「年ごとにパーティショニングしたノード群」「産地ごとにパーティショニングしたノード群」のようにパーティショニングの仕方を変えたノード群を何セットも用意しておくということも、理論的には可能です。
が、そんなことは現実的には不可能ですよね。
パーティショニングにはメリットとデメリットの両方がはっきりとあり、要件を十分に見極めてから行わないと、投じたコストに比して十分な見返りを得られないという残念な結果になってしまいます。
コストパフォーマンスの高いクラスタを構成するためには、事前の要件定義と、日々のログの分析が重要になるというわけです。
なお、先に述べた通り、現在Droongaはキーのハッシュによるパーティショニングのみ内部的に対応しています。
それ以外のパーティショニング方式については、現状では構想のみの段階となっていますので、あしからずご了承ください。
データの分散による可用性の低下を防ぐ
データの分散はリスクを増大させる
ここまで、データを分散させるとディスク効率や検索性能が犠牲になる場合があるという事を述べました。
しかしデータの分散にはもう1つ、可用性が下がるというデメリットもあります。
ここまでにも何度か述べた通り、データを分散させると、個々のノードには異なった内容のデータが格納されるようになります。
そんな状態で一部のパーティションが故障などにより停止してしまうと、何が起こるでしょうか?
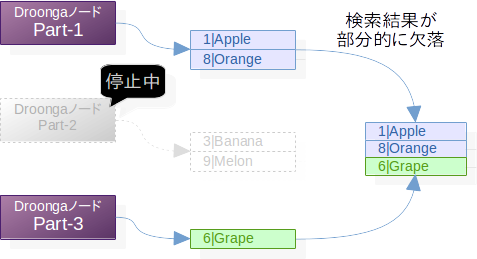
そう、そのパーティションが担当していた部分のデータが検索できなくなってしまいます。
実際のDroongaにおいては、検索リクエストの転送時に転送先が見つからなかったり、集約処理の部分でいつまで経っても一部の結果が返ってこなくてReducerが処理を完了できなかったりと、あちこちで不整合が発生してしまいます。
HTTP経由で検索リクエストを行ったのであれば、タイムアウトしたり、あるいは500系のエラーが返されたりといった結果になるでしょう。
リスクの増大を、リスクの分散で相殺する
このようなトラブルの発生を避けるため、パーティショニングを行う際にはレプリケーションも併用する事が強く推奨されます。
以下は現段階で想定している、パーティショニング導入後の典型的なクラスタ構成のパターンを図示した物です。
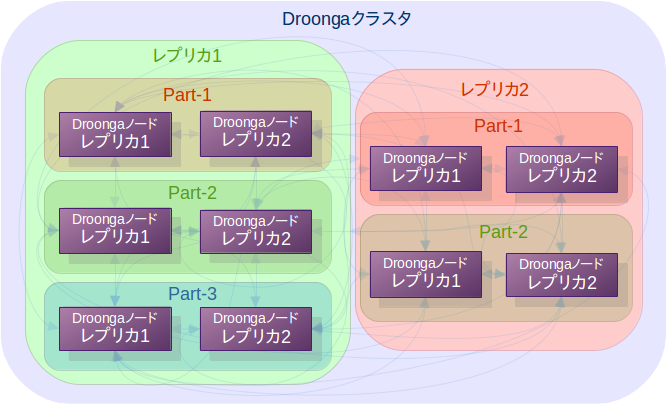
典型的構成では、パーティショニングの有無に関わらず、最上位ではレプリケーションが構成されます。
これは、既存の論理レプリカからのコピーという形で全体のデータを複製できるようにするためです。
(図中では最上位に2つの論理レプリカが存在していますが、これは、「新しいパーティショニング方法に切り替えるためにデータを移行している最中」や、「パーティショニング方法を変えた状態でのA/Bテストを実施している最中」などの場面でのみ見られる一時的な構成という事になります。)
その上で、パーティショニングはその次の階層で行い、冗長化のためのレプリケーションは、各パーティションの階層で行う事を想定しています。
この構成はRAID 1+0によく似ています。
それに対し、各パーティションの階層で冗長化せず最上位の階層で冗長化を図るのはRAID 0+1に相当します。
各パーティションの階層での冗長化が最上位の階層での冗長化よりも推奨される理由については、RAID 1+0とRAID 0+1の違いの解説
を参照すると分かりやすいでしょう。
まとめ
最後に、この記事の要点をまとめておきます。
- 検索結果の集約には色々な方法があります。
- データを分散させると、検索性能は低下します。
- データの分散のさせ方にはいくつか種類があり、適切な分散のさせ方を選べば、検索性能の低下を防ぐことができます。
- データを分散させると、可用性が低下します。
データの分散は冗長化との併用が強く推奨されます。
以上、4回に渡って、Droongaを題材にしながら分散処理の初歩の初歩を解説してみました。
Droongaや分散処理を今までより少しでも身近に感じられるようになっていただけていれば、幸いです。
次回予告
ここまでで解説してきたような分散処理をつつがなく実行するためには、様々な基盤技術が必要となります。
Groonga Advent Calendar 16日目の記事では、Droongaにおける分散処理を支えている、分散データ処理エンジンの基盤としての部分について解説します。
乞う御期待!