こんにちは。Droonga開発チームの結城(Piro)です。
Groonga Advent Calendar 9日目は、7日目に引き続き、Droongaを肴にした分散処理の初歩の初歩の解説です。
最初に、分散には以下の3つのメリットがあると述べました。
- 負荷の分散により、1台のマシンの性能の限界を超えた処理が可能になる。
- リスクの分散により、可用性が高まる。
- データの分散により、今までは扱いきれなかった量のデータを扱えるようになる。
1つ目のメリットについては6日目の記事、2つ目のメリットについては7日目の記事で解説しました。
この記事では最後の3つ目のデータの分散について解説したいと思います。
データの分散が必要になる場面
前の記事で、Groongaには一定時間内に処理できるリクエスト数(スループット)に上限があるという話をしましたが、実はもう1つの上限があります。
それは、扱えるデータ量の上限です。
- Groongaは設計上、最大でディスク上に作成されたデータベースのファイルサイズと同じだけのメモリを使用します。
データベースの大きさがコンピュータの搭載メモリ量よりも大きくなると、スラッシング(スワップが頻発して他の処理が全く進まなくなること)が発生してまともに動作しません。 - Groongaのドキュメントに詳しく記載されていますが、データベースのサイズが搭載メモリ量より小さくても、レコード数やキーの総サイズなどの制限により、それ以上レコードを追加できなくなる事もあります。
- データサイズやレコード数などが上限に収まっている場合でも、データベースサイズが大きくなればなるほど、検索には時間がかかるようになります。現実的な時間内に検索が終了しないようでは、事実上、検索できないのと同じです。
扱えるデータ量の上限に達してしまった場合、Groongaではそれ以上何も手の打ちようがありません。
データの格納方法など様々な工夫を凝らすことでデータ量はある程度削減できますが、それにもいずれ限界がやってきます。
この限界を突破するための手段が、データの分散です。
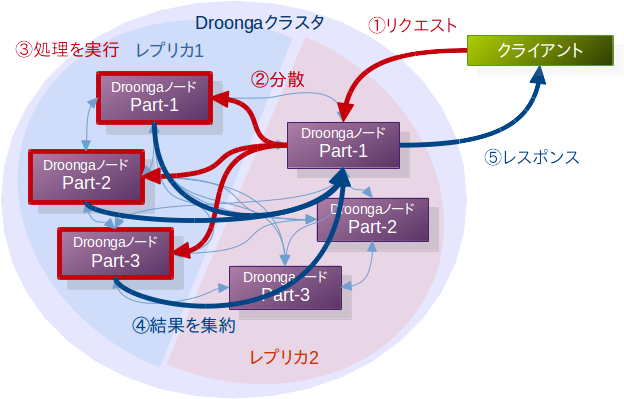
これは、分散されたデータを検索する際の動作を単純化して示した図です。
図中の左側の3つのノードはそれぞれが異なるデータを格納していて、同じ検索リクエストに対してそれぞれ異なる結果を返します。
クライアントから投じられた1つの検索リクエストを、これら3つのノードに並行して転送し、出てきた検索結果を1つにまとめてクライアントに返せば、1つの巨大なデータベースを検索したのと同じ結果を得られます。
これなら、1ノードで扱えないような大量のデータでも検索の対象にできますし、1ノードあたりの検索処理も軽くなって、検索結果をより素早く返せる事が期待できます。
この図の3つのノードのように、1つの巨大なデータベースを複数の小さなデータベースに分割することを、パーティショニング(あるいはシャーディング)と呼びます。
また、分割された後の小さなデータベースのことを、パーティション(あるいはシャード)と呼びます。Droongaではスライスという用語を使っていますが、この記事では一般的な表現に合わせてパーティショニングという用語を使うことにします。
データの分散
パーティション単位でのデータの格納
レプリケーションが行われているクラスタ(前の記事で解説したような構成)では、更新リクエストはすべてのノードに転送されていました。
一方、パーティショニングが行われているクラスタでは、更新リクエストは適切なパーティションにだけ転送されます。
以下は、Droongaにおける、パーティショニングが行われているクラスタでの更新リクエストの取り扱いの概略図です。
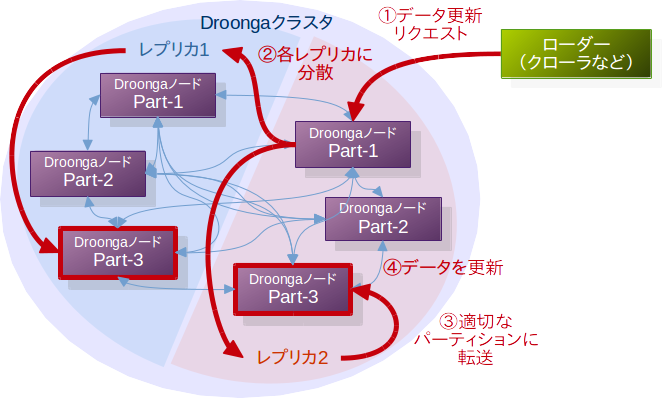
クラスタ外から送られてきた、レコードの追加などを伴う更新リクエストは、まずすべてのレプリカ(レプリケーションを構成する個々のノード)に分散されます。
前の記事の解説で示した構成では1ノードが1つのレプリカでしたが、パーティショニングが行われているクラスタでは、「1つのグループを構成しているパーティション群」=「1つの論理的なレプリカ」となります。
その後、一定の基準に則ってリクエストの転送先パーティションとなるノードが決定されて、当該ノードにメッセージが転送され、メッセージを受け取ったノードが自分の持つデータベースを更新します。
なお、この図ではメッセージの転送が繰り返されているかのように描かれていますが、実際には転送先の決定は更新リクエストを最初に受け付けたノードが行います。
パーティションの分け方
データを分散させる時は、何を基準に分散先のパーティションを決めるか(何を基準にパーティションを分けるか)がポイントとなります。
他のデータベース製品では、パーティションごとに同じデータ群の違うフィールドを格納するやり方(人物情報のテーブルなら、あるパーティションには氏名のフィールド、次のパーティションには住所のフィールド、といった具合)や、データ群そのものを分けるやり方(あるパーティションには人物情報、次のパーティションには商品情報、といった具合)を取る事ができる物もあります。
Droongaの場合は、すべてのパーティションで同じスキーマ構成を持ち、レコード単位でデータが分散している、というパーティションの分け方を行います。

その上で、具体的には以下のような分散のさせ方があります。
- キーのハッシュで分散させる。
例えば、1から3までのパーティションを用意し、レコードの主キーとなるようなそのデータ固有の識別子(キー)をハッシュ関数(同じ入力に対しては必ず決まった入力を返す関数)にかけて、得られた値に応じて1から3までの各パーティションにデータを均等または特定の割合で割り振る、といった要領。 - データの範囲で分散させる。
例えば、「2014年」「2015年」「2016年」といった「年」ごとにパーティションを用意し、各パーティションには作成年月日が当てはまるデータだけを転送する、といった要領。 - データの種類で分散させる。
例えば、「Japan」「USA」「China」「India」といった「国名」ごとにパーティションを用意し、各パーティションには、countryというフィールドの値がその国名と一致するデータだけを転送する、といった要領。
(※データを格納する、という表現にしていないのがポイントです。Droongaノードは基本的に、自身を最終的な宛先として転送されてきた更新リクエストをすべて処理するようになっており、どのノードにどんなデータを格納するかは、データの転送元ノードの側が決定します。これについては後の記事で解説します。)
データをランダムに分散させる、という分け方はありません。
データをどのパーティションに転送するかを完全にランダムに決めてしまうと、既存のデータを更新しようとした場合に、複数のパーティションに同じキーのデータが格納されてしまう、あるいは、更新対象のデータが見つからない、といった問題が起こってしまいます。
そのような問題を回避するためにも、同じデータは必ず同じパーティションに転送されなくてはなりません。
(ランダムな分散に一番近いのは、この中では、キーのハッシュによる分散でしょうか。)
単純に「検索対象にする、保存するデータ量の限界を超えるため」のパーティショニングであれば、キーのハッシュによるパーティショニングが最も効率がいいと言えます。
この基準でデータを分散させると、各パーティションが持つデータの量はほぼ均等になるため、限られたディスク容量を有効に活用できます。
これを「ディスク効率が良い」と言います。
反対に、他の基準、例えば人物の情報のデータを国籍名でパーティショニングすると、ChinaやIndiaのレコードが他よりも多い偏った分散のされ方になりますので、特定のノードだけ早くディスクがいっぱいになるといった事が起こり得ます。
しかし、検索の要件によっては、データの範囲や種類でパーティショニングを行った方がよい場合もあります。
これについては後の記事で説明しましょう。
Droongaは現在、内部的にはキーのハッシュによるパーティショニングにのみ対応しています。
しかし、クラスタ管理コマンドなどでパーティショニングをどのように指定するのがよいかといった点の検討が進んでいないため、現状では事実上封印された機能となっています。
ですので、この記事は、Droongaの将来のバージョンで可能になる事柄についての解説となっています。あしからずご了承ください。
分散されたデータの検索
以下は、Droongaにおける、パーティショニングが行われているクラスタでの検索リクエストの取り扱いの概略図です。
この記事の最初の方で示した図ですが、もう一度見てみましょう。
前の記事で解説した通り、クラスタに流入してきた検索リクエストは、いずれか1つのレプリカに転送されます。
キーのハッシュによるパーティショニングが行われているクラスタでは、リクエストの転送先は、1つの論理的レプリカとなっているパーティション群全体となります。
この図では左の3つのノード群と右の3つのノード群がそれぞれ論理的レプリカとなっており、検索リクエストが左の論理的レプリカ=3つのパーティションに転送されています。
レプリケーションのみが行われている状態では、1つのレプリカノードが検索処理を行い、返した検索結果をそのままクライアントに返すことができました。
しかし今回は、1つの検索リクエストを、異なる内容のデータベースを持つ3つのパーティションがそれぞれ処理するため、3つの異なる検索結果ができてきます。
このまま検索結果をクライアントに返すと、3つのうち1つの検索結果(=一部の検索結果)しか受け取れなかったり、1つのリクエストでレスポンスが3回も返されたりという具合に、クライアントから見ると不自然なことになります。
そこでDroongaは、検索結果の集約を行います。
集約された検索結果は、データが分散されていない1つの巨大なデータベースでの検索結果と同等の物になります。
まとめ
話が盛り上がってきたところですが、長くなってきたので、一旦ここらでまとめに入りましょう。
- データを分散すると、1ノードで処理しきれない量のデータを対象として検索できるようになります。
- データの分散のさせ方にはいくつかの種類があります。
そのうちの1つの「キーのハッシュによる分散」には、ディスク効率に優れているという特徴があります。 - Droongaは内部的にはキーのハッシュによる分散に対応していますが、現在のところは事実上封印された機能となっています。
次回予告
この記事では、データを複数のパーティションに分散する事により、大量のデータを対象にした検索を行えるという事を解説しました。
では、各パーティションが返したバラバラの検索結果を1つにまとめる「集約」とはどのような処理なのでしょうか?
日が飛びますが、Groonga Advent Calendar 13日目の記事では、分散処理の利点の3つ目「データの分散」の後半として、分散された検索結果の集約について解説します。
乞う御期待!