こんにちは。Droonga開発チームの結城(Piro)です。
Groonga Advent Calendar 18日目は、16日目に引き続きDroongaの解説です。
Droongaを題材にした過去4回の記事(6日目、7日目、9日目、13日目)では、分散処理の初歩の初歩を解説しました。
それに続くDroongaの基盤部分を紹介するシリーズとして、16日目はノード間の通信プロトコルについて紹介しました。
今回はその続きとして、ノード間でのメッセージ転送における転送先の決定方法と、そのために必要となるクラスタ構成の情報をDroongaではどのように扱っているのかを紹介します。
転送先を決めるのは誰か?
「検索リクエストをレプリケーション内でランダムに転送する」や「更新リクエストを適切なパーティションに転送する」といった動作を行う時、Droongaノードはどのようにして転送先を決定しているのでしょうか。
マスターがあるシステムの場合
マスター・スレーブと呼ばれる構成を取るシステムでは、そのような判断はマスターが行います。
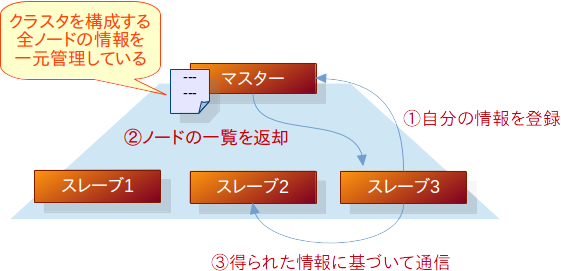
マスターとは即ち主人で、スレーブとはそれに隷属する存在です。
マスターはクラスタ情報の原本を持っています。(必要に応じてコピーをスレーブが持つこともありますが、あくまで大元の情報はマスターが持っている物です。)
マスターの配下にスレーブが属する形になるため、「このノード群が1つのレプリケーションを構成しているんだな」といった事が見えやすいですし、責任の分担も非常に明確です。
しかし、このような構成には、マスターが停止した途端にシステムが動作しなくなるという難点があります。
ホスト名の解決を行うDNSもマスター・スレーブ型のシステムと言えますが、DNSの障害によって名前解決できないためにサービスを利用できなくなってしまった、というトラブルに遭遇したことのある人は少なくないでしょう。
このような、他の箇所が無事であるにもかかわらずその1点だけがダメージを受けるとシステム全体に致命的な影響が及んでしまう箇所を、*単一障害点(SPOF:Single Point Of Failure)*と言います。
マスターが無いDroongaの場合
Droongaクラスタには、マスターと呼べるような存在がいません。
なぜマスター無しでレプリケーションやパーティショニングを行えるのでしょうか?
Droongaでその鍵となっているのが、カタログです。
droonga-engineをインストールしたコンピュータの ~droonga-engine/droonga/catalog.json の位置にあるファイルが、その実体です。
例えば、前の記事でこのようなクラスタの構成例を示しました。
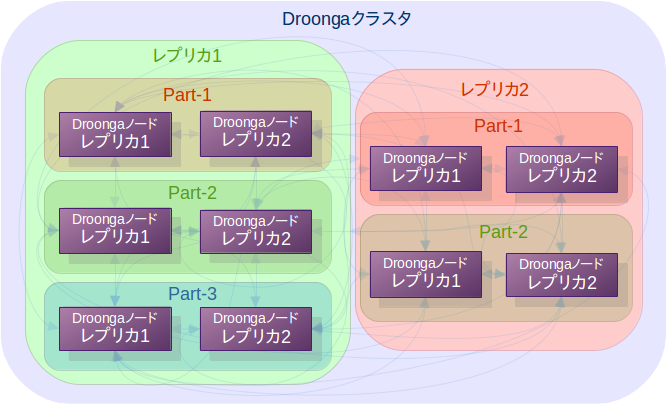
この構成のクラスタに属するノードは、全員が以下のような内容のカタログを持っていることになります。
図の内容との対応関係が見て取れるのではないでしょうか?
{ "version": 3,
"datasets": {
"Default": {
"volume": { "replicas": [
{ "slices": [
{ "volume": { "replicas": [
{ "address": "node0:10031/droonga.000" },
{ "address": "node1:10031/droonga.000" }
] } },
{ "volume": { "replicas": [
{ "address": "node2:10031/droonga.000" },
{ "address": "node3:10031/droonga.000" }
] } },
{ "volume": { "replicas": [
{ "address": "node4:10031/droonga.000" },
{ "address": "node5:10031/droonga.000" }
] } }
] },
{ "slices": [
{ "volume": { "replicas": [
{ "address": "node6:10031/droonga.000" },
{ "address": "node7:10031/droonga.000" }
] } },
{ "volume": { "replicas": [
{ "address": "node8:10031/droonga.000" },
{ "address": "node9:10031/droonga.000" }
] } }
] }
] }
}
}
}
(※ここで例示しているカタログの書式は、次期バージョンのDroongaで利用可能になる予定の「バージョン3」仕様案に基づいています。また、分かりやすいようにいくつかの情報を省いています。現在のバージョンのDroongaで実際に使われているカタログとは若干異なる部分がありますので、ご注意下さい)
すべてのDroongaノードはカタログの情報に基づいて、クラスタにはどんなノードがいるのか・どのノードがどういう役割なのかを把握しています。
これにより、すべてのノードがマスターと同じような判断をこなせるため、DroongaクラスタにはSPOFが無いということになります。
(※ただし、ノードの名前解決にDNSを使っている場合にはそこがSPOFになるなど、Droongaの枠組みの外側の障害の影響は受けます。)
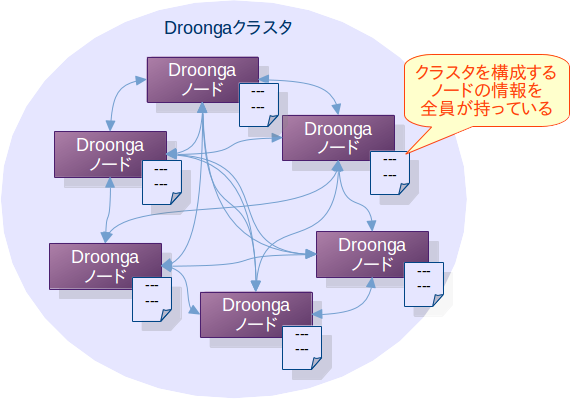
また、メッセージを最終的に誰に送ればよいのかはカタログから導出できるため、ノード間でバケツリレー式に転送を重ねなくても、Droongaノード同士は最短ルートでメッセージを送り合う事ができます。
では、実際にはDroongaノードはメッセージの転送先についてどのような判断をしているのでしょうか?
データ更新を伴うリクエストの転送先
クラスタ外から流入してきたメッセージは、データ更新リクエストかそうでないかによって、レプリカ群とパーティション群のそれぞれにどのように転送するかが少し変わります。
データ更新リクエストでは、以下のような判断が行われます。
- データ更新リクエストは、同階層のすべてのレプリカに行き渡る必要があります。
レプリケーションでは、すべてのレプリカが同じデータを持っていなくてはならないからです。 - その一方で、パーティションについては一部のパーティションにだけリクエストを転送すればよいです。
どのパーティション宛にメッセージを転送するかは、カタログに記載されたパーティショニングの指定(※上記の例では省略)に基づいて判断します。
外部からのリクエストを受け付けたDroongaノードはこれらの判断基準に基づいて、カタログ内のクラスタ構成情報からメッセージの最終的な転送ルートを決定します。
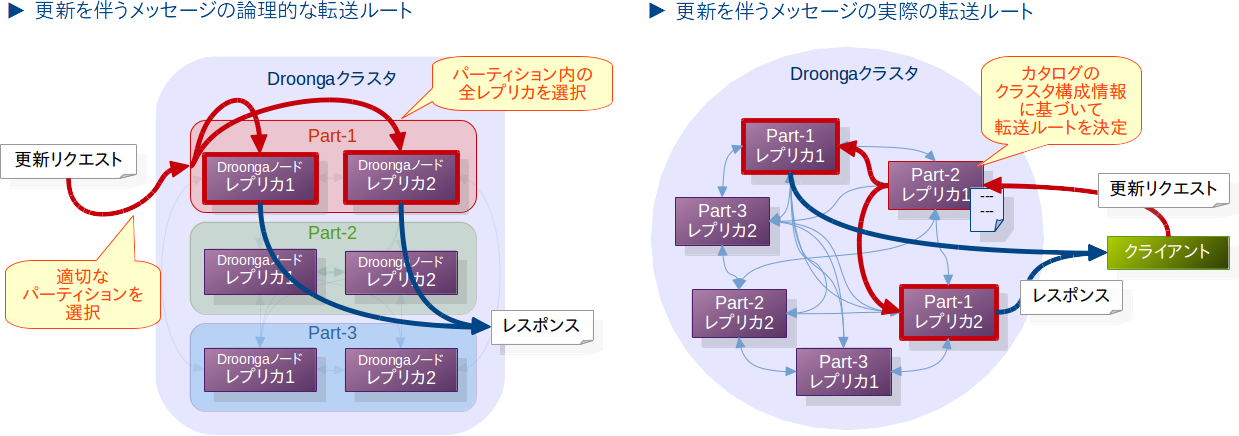
実際の転送ルートだけを見るといまいち要領を得ませんが、論理的な転送ルートを見ると、その意味は一目瞭然ですね。
データ更新を伴わないリクエストの転送先
他方、検索リクエストなどのデータ更新を伴わないリクエストでは、以下のような判断が行われます。
- データ更新を伴わないリクエストは、同階層のレプリカの中では1つだけに転送すればいいです。
レプリケーションではすべてのレプリカが同等なので、いずれか1つにリクエストを送るという形で負荷を分散できます。 - その一方で、パーティションについては、リクエストの内容(例えば検索クエリ)次第では複数のパーティションにメッセージを転送しなくてはならない場合があります。
リクエストを受け付けたDroognaノードはやはりこれらの基準に則って、カタログの情報を元にメッセージの転送ルートを決定します。
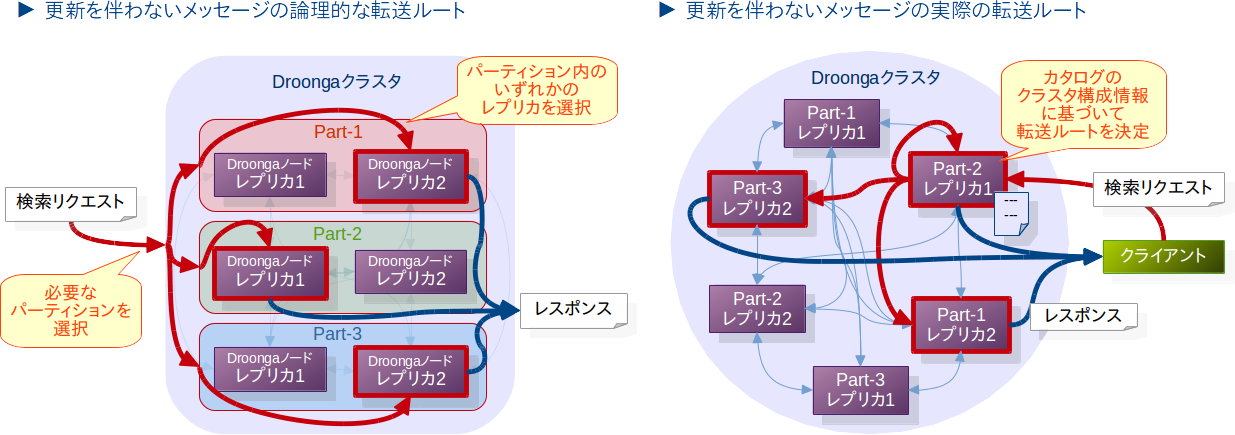
こちらも、論理的な転送ルートを見ると、どういう理由でメッセージがそのルートを通ることになったのかがよく分かるでしょう。
このように、カタログに記載された情報に基づいてメッセージの転送先を制御することによって、Droongaではレプリケーションやパーティショニングを論理的に実現しているというわけです。
まとめ
話をまとめましょう。
- Droongaでは、すべてのノードがクラスタの構成情報をカタログとして持っています。
- Droongaノードはカタログの内容に基づいてメッセージの転送先を決定します。
- Droongaのレプリケーションやパーティショニングは、メッセージの転送先をどこにするかという判断だけで論理的に実現しています。
次回予告
Droongaではクラスタの構成情報を全ノードが保持していて、それに基づくメッセージの転送によってレプリケーションやパーティショニングが実現されていることを紹介しました。
しかし、これだけでは不意のトラブルには対応できません。停止したノードがあってもクラスタとしてサービスを提供し続けるには、ノードの状態が変わるのに合わせてメッセージの転送ルートも変える必要があります。
Groonga Advent Calendar 19日目の記事では、クラスタ内の各ノードがお互いの「今」の状態をどのように把握しているのかを解説します。
乞う御期待!