みなさんはuniqというコマンドやメソッドをご存じでしょうか?
LinuxやmacOSのシェルのコマンドとして使えるuniqは、与えられた入力の中で(連続する)同じ値を重複と見なして除外するというコマンドです。例えばこんな風に使います。
$ cat /var/log/apache2/access.log | cut -d ' ' -f 1
192.168.0.12
192.168.0.10
192.168.0.12
192.168.0.12
192.168.0.11
192.168.0.10
192.168.0.11
192.168.0.11
$ cat /var/log/apache2/access.log | cut -d ' ' -f 1 | sort | uniq
192.168.0.10
192.168.0.11
192.168.0.12
プログラミング言語でも似たような機能を持っている物があります。例えばRubyでは、Arrayクラスのuniqメソッドを使うと配列の要素から重複を簡単に取り除くことができます。
[0,3,2,1,4,2,3,1,1,2,3,5,2,3,1,2,3,1,1,3,3,1,2].uniq
# => [0, 3, 2, 1, 4, 5]
ここで標題のJavaScriptの話をすると、JavaScript自体の言語仕様はES6やES2015、ES2017などを経て強化されてきているのですが、残念ながら上記のようなことを一発でやる機能は仕様化されていません。やりたければ、既存の機能を組み合わせて実現するほかありません。
uniqのやり方色々
やり方を紹介した記事は、配列の重複をはじく、もしくは重複を取り出す - Qiitaなど既にいくつも例がありますが、ここでは改めてなるべく多くのパターンを挙げてみる事にします。
Objectのキーを使う方法
古典的なやり方としては、Objectのプロパティ名を使う方法があります。JavaScriptではObjectのインスタンスは一種のハッシュ(連想配列)として機能し、プロパティ名(=ハッシュのキー)に重複はあり得ないため、配列の要素が登場済みかどうかの判定をするのに使うことができます。
function uniq(array) {
const knownElements = {};
const uniquedArray = [];
for (let i = 0, maxi = array.length; i < maxi; i++) {
if (array[i] in knownElements)
continue;
uniquedArray.push(array[i]);
knownElements[array[i]] = true;
}
return uniquedArray;
};
const array = [0,3,2,1,4,2,3,1,1,2,3,5,2,3,1,2,3,1,1,3,3,1,2];
console.log(uniq(array));
// => [0, 3, 2, 1, 4, 5]
for文の箇所を今風の書き方に改めると、以下のようになるでしょうか。
function uniq(array) {
const knownElements = {};
const uniquedArray = [];
for (const elem of array) {
if (elem in knownElements)
continue;
uniquedArray.push(elem);
knownElements[elem] = true;
}
return uniquedArray;
}
ただ、この方法には一つ致命的な欠陥があります。それは、Objectのプロパティ名は必ず文字列として扱われるため、文字列化できない要素や、文字列化した時に区別がつかない要素を含む配列に対しては使えないという点です。JavaScriptではDOMのノードや何らかのクラスのインスタンスなどのオブジェクトを格納した配列を使うことが多いので、これでは使える場面が非常に限定されてしまいます。
Arrayの便利メソッドを使う
ArrayのインスタンスのindexOfメソッドを使うと、任意の形式のオブジェクトについて、配列に含まれているかどうかを容易に識別することができます。これを使うと、先の例は以下のように書き直せます。
function uniq(array) {
const uniquedArray = [];
for (const elem of array) {
if (uniquedArray.indexOf(elem) < 0)
uniquedArray.push(elem);
}
return uniquedArray;
}
ES2016で追加されたArrayのincludesメソッドは、渡されたオブジェクトが配列に含まれているかどうかを真偽値で返すという物です。これを使うと、indexOfの戻り値の特性(配列に含まれていなければ-1を返す)を知らない人でも読みやすいコードになります。
function uniq(array) {
const uniquedArray = [];
for (const elem of array) {
if (!uniquedArray.includes(elem))
uniquedArray.push(elem);
}
return uniquedArray;
}
ES5.1で追加されたArrayのfilterメソッドは、条件に当てはまる要素だけを含んだ配列を生成するという物です。これを組み合わせると、forループを書かずに同様のことができます。
function uniq(array) {
return array.filter(function(elem, index, self) {
return self.indexOf(elem) === index;
});
}
元の配列の中で2回目以降に登場した(同じ要素が既に登場済みの)要素は、indexOfの結果=先頭からその要素を探した時の位置が、index=要素自身の位置と一致しません。そういった要素を除外すれば、各要素が1回ずつしか出現しない配列を取り出せる、という訳です。一時的な配列を作らないで済ませるために、2つ前の例とは異なるindexOfの使い方をしています(先の例では一時的な配列に対するindexOfなのに対し、こちらは元の配列に対するindexOfです)。
アロー関数を使うと、もう少しすっきり書けます。
function uniq(array) {
return array.filter((elem, index, self) => self.indexOf(elem) === index);
}
Mapを使う
ES2015で追加されたMapは、それまでのObjectを使った擬似的な連想配列(ハッシュ)とは異なり、任意のオブジェクトをキーとして使うことができる本物の連想配列です。これを使うと、先のObjectを使った例をより完全な物にすることができます。
function uniq(array) {
const knownElements = new Map();
const uniquedArray = [];
for (const elem of array) {
if (knownElements.has(elem))
continue;
uniquedArray.push(elem);
knownElements.set(elem, true);
}
return uniquedArray;
}
この例では配列を先に用意していますが、実はその必要はありません。というのも、Mapはkeysメソッドを使うとキーだけの集合を得ることができるからです。keysメソッドの戻り値はイテレータなので、ES2015で追加されたArray.fromを使って配列に変換することができます。
function uniq(array) {
const knownElements = new Map();
for (const elem of array) {
knownElements.set(elem, true); // 同じキーに何度も値を設定しても問題ない
}
return Array.from(knownElements.keys());
}
Setを使う
Mapに比べるとややマイナーですが、ES2015で追加されたSetという機能もあります。Mapがキーと値のペアを取り扱うのに対して、SetはMapでいう所のキーだけ、つまり、一意な値を格納する集合です。要素の重複があり得ないArrayのような物、とも言えます。これを使うと、先の例はこう書き直せます。
function uniq(array) {
const knownElements = new Set();
for (const elem of array) {
knownElements.add(elem); // 同じ値を何度追加しても問題ない
}
return Array.from(knownElements);
}
しかし、これはもっと簡潔に書き直すことができます。Setはコンストラクタの引数としてイテレータや配列を受け付けるため、new Set(array)とすれば、渡した配列の要素の中から一意な値だけの集合を得ることができます。それをArray.fromで配列に戻せば、即ち「配列から重複を取り除く」のと同じ事になります。
function uniq(array) {
return Array.from(new Set(array));
}
2019年1月5日追記:Array.fromではなくES2015のスプレッド構文を使うと、以下のようにも書けます。
function uniq(array) {
return [...new Set(array)];
}
どの方法が一番おすすめ?
ということで、JavaScriptで配列をuniqする方法を色々と列挙してみましたが、どの方法が一番おすすめと言えるでしょうか。
判断の優先順位
その答えを考える前に、何を以て「良い」と判断するかをまずは明らかにする必要があります。具体的には、以下の各観点に優先順位を付けなくてはなりません。
- コードの量が短い事
- 古い実行環境でも使える事
- 処理対象の配列が巨大でも高速である事
- 処理対象の配列が多数でも高速である事
というのも、上記の例のそれぞれには一長一短あり、すべての条件を同時に満たす事は困難だからです。
コードの量については、見ての通りです。コードゴルフなどの文脈や、1バイトでもソースの量を減らさなくてはならないようなシビアな状況であれば、多少動作速度が遅くても文字数の短いコードにする必要があるでしょう。そうでない限りは、記述量が多くなっても速度の速いコードを採用する方が良いでしょう。
実行環境(ブラウザやNodeのバージョン)については、想定する環境でサポートされていない機能を使用している方法は、当然ながら採用できません。MapやSetを使う方法は、トランスパイラを使う事で古い環境でも動作させる事はできますが、その場合、変換後のコードがどのパターンになるかによって動作速度が変わってきます。
動作速度については、処理対象の配列の要素数と実行回数によって最適な方法が変わってきます。
まず重要な観点として、計算量の問題があります。アルゴリズムごとに計算量には差があり、配列の要素数や実行回数が多い場面では、なるべく計算量の小さいアルゴリズムの方が望ましいです。
また別の観点として、オーバーヘッドの問題があります。JavaScriptでは関数の呼び出しやオブジェクトの作成、値の型の変換など、純粋な計算量とは別の部分で処理に時間がかかる部分があります。実行回数が少なければオーバーヘッドはほとんど無視できますが、多いとほとんどの処理時間がオーバーヘッドによる物という事になる場合もあります。
各アルゴリズムの処理速度の比較
それぞれのアルゴリズムで同じ配列を条件を変えながら処理するベンチマークをFirefox 64上で実行した場合の結果で、それぞれの優劣を見ていきましょう。まずは、要素数10の配列を10万回から50万回まで処理した結果です。グラフの縦軸は処理に要した時間(ミリ秒)で、グラフの線が上にあるほど処理が遅く、下にあるほど処理が速い事を示しています。
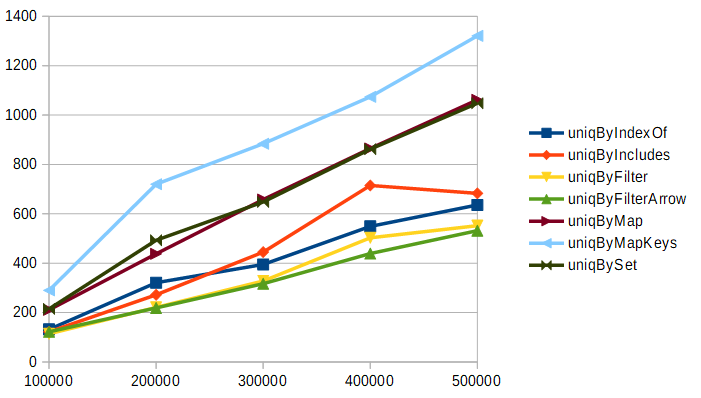
このように要素数の少ない(サイズの小さい)配列を処理する場面では、forループやArrayのメソッドだけを使う方法がおすすめという事がグラフから見て取れます。MapやSetを使う方法は、このくらいの要素数だとオーバーヘッドが非常に大きいようです。
次は、要素数300の配列を2500回から12500回まで処理した結果です。グラフの縦軸は処理に要した時間(ミリ秒)です。
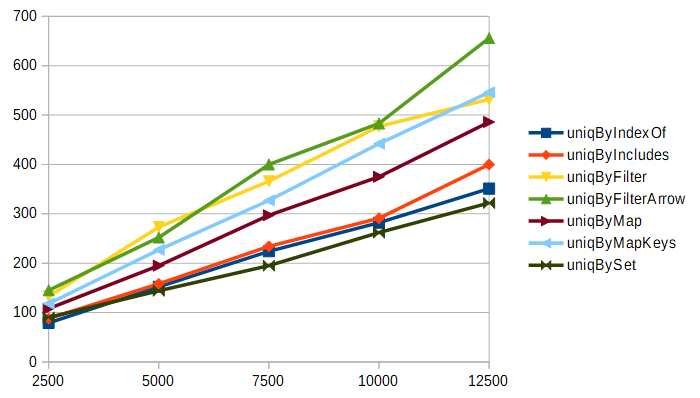
今度は結果が逆転しました。最速なのはSetを使う方法で、最も遅いのはArrayのfilterを使う方法という結果になっています。これは、Arrayのfilterを使うアルゴリズムが本質的に二重ループである(いわゆる、計算量がO(n^2)のアルゴリズム)ことが原因です。この結果からは、要素数が増えてくるとオーバーヘッドよりも計算量の方が支配的になってくるという事が分かります。
次は、要素数10000の配列を100回から500回まで処理した結果です。グラフの縦軸は処理に要した時間(ミリ秒)です。
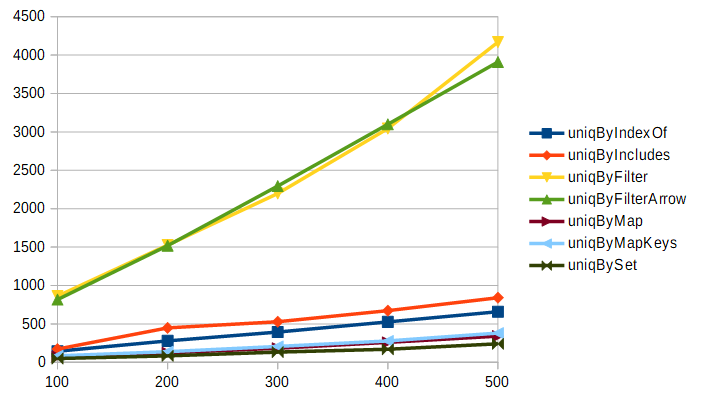
もはやオーバーヘッドは完全に無視できるレベルになり、計算量が少ない物が明白に高速という結果になりました。ArrayのindexOfやincludesを使う方法とfilterを使う方法で、本質的なアルゴリズムそのものは大差ない(どちらも二重ループ)のに、forループとfilterとでパフォーマンスに大きな差が現れているのは何故でしょうか? その答えは後ほど説明しましょう。
今度は指標を変えて、要素数がどの程度になったあたりから計算量とオーバーヘッドの問題が逆転するかを見てみます。以下は、要素数を100から1000まで増やしながら5000回処理した場合の結果です。グラフの縦軸は処理に要した時間(ミリ秒)です。
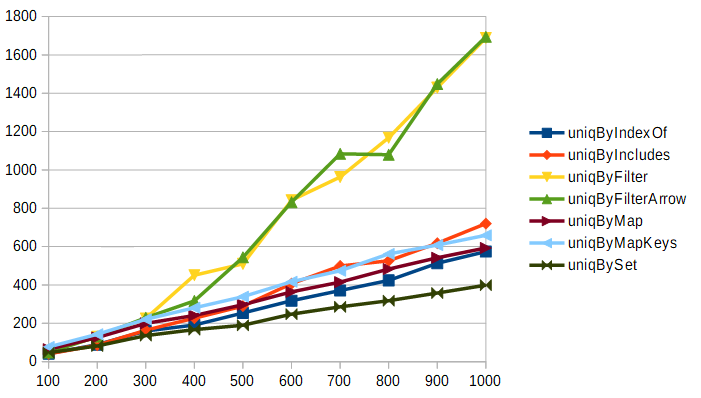
実行環境の性能による部分が大きいと考えられますが、今回の実験環境においては要素数が300を超えたあたりで計算量の増大がオーバーヘッドを追い抜くという結果になりました。しかしやはりアルゴリズム的に差が無い筈のuniqByIndexOfやuniqByIncludesとuniqByFilterやuniqByFilterArrowの間で大きな差がある……というか、filterを使うと指数関数的に処理時間が増大するのにforループでは線形の増加に留まっているように見えます。
この謎を解くために、次はNightly 66.0a1での結果を見てみましょう。JavaScriptエンジンの最適化が進んでいるためか、同じパラメータだと数字が小さくなりすぎてしまったため、今度はパラメータを「要素数を100から200刻みで1900まで増やしながら10000回処理」に変えています。
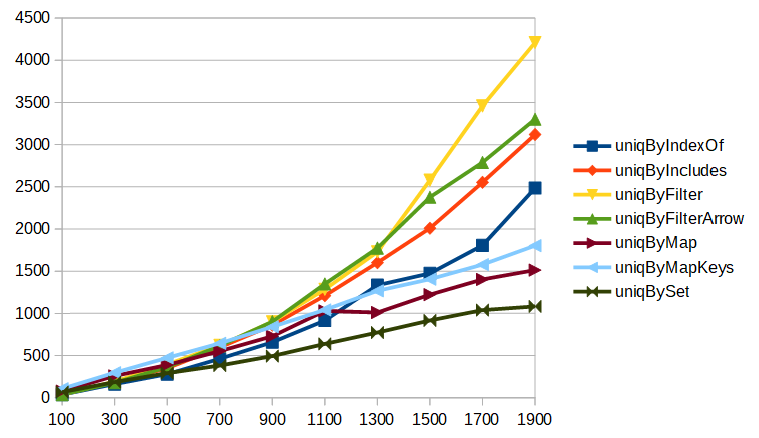
グラフの傾向を見ると、計算量が大きいアルゴリズムであるindexOfやincludesを使った物はいずれも指数関数的な増大を見せています。1つ前の結果でuniqByIndexOfやuniqByIncludesが線形の増加に見えたのは、
- Firefox 64時点では
forループは最適化されていたが、filterのループは最適化されていなかった。 - 最適化の結果、
forループを使った物の結果の指数関数的な増大が顕著になり始めるタイミングが右にずれていた(グラフが横に引き延ばされていた)。そのため、グラフの描画範囲では線形の増加に見えていた。 - Nightly 66では
filterも最適化されたため、アルゴリズムが本質的に似ている4つの項目のグラフが再び接近するようになった。
という事だったようです。
また、それでもまだfilterを使った方法の方が遅いのは、indexOfやincludesを使った方法では検索対象の配列がuniq後の配列(=小さい配列)なのに対し、filterを使う方法ではuniq前の配列(=大きい配列)を対象にしているせいで、その分余計な時間がかかったからだと考えられます。
2019年1月5日追記:new Set()とスプレッド構文の組み合わせを加えて再計測した結果も掲載しておきます。
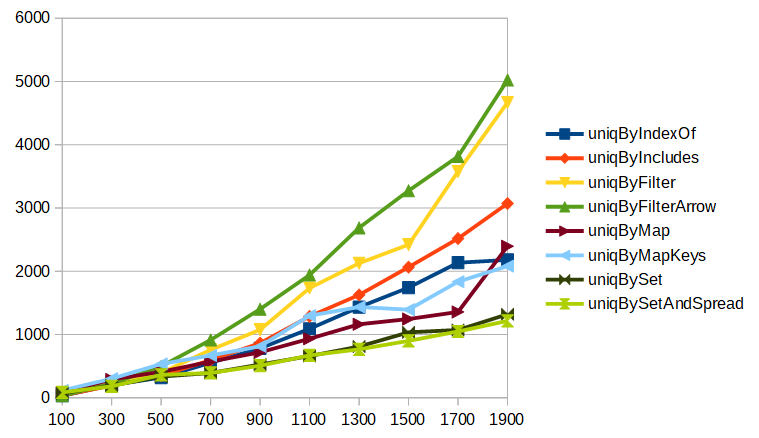
検証環境上では、スプレッド構文を使うとArray.fromより若干速いという結果が得られました。
まとめ
以上、JavaScriptでArrayのuniqを実現する様々な手法をご紹介しました。
Webのフロントエンドの開発では計算量が問題になるような事はそう多くないのではないかと思われますが、Nodeで大量のリクエストを捌くような場面や、どれだけの量のデータが渡されるか事前に予想できないライブラリ開発のような場面では、なるべく計算量が小さいアルゴリズムを採用する事が望ましいです。
また、1つの事を実現するのに複数のやり方がある場合には、何を優先するかを事前にきちんと明らかにし、数値で比較可能な場合は特に、この例のようにベンチマークを取ってそれぞれのやり方の優劣を比較する事が大事です。
性能測定の結果を踏まえると、処理速度的には、少なくとも今回の実験環境においては
-
SetとArray.fromまたはスプレッド構文の組み合わせが最もおすすめ。 - ただし、「要素数が小さい配列を」「頻繁に(多数)処理する」という前提がある場合には、
SetやMapを使わない方法の方がおすすめ。
という事が言えそうです。ベンチマークに使用したスクリプトはGistで公開していますので、皆さんもぜひお手元で試してみて下さい。