Yolov8のハイパーパラメータ調整
人間の動作モードを解析するのにYolov8を使っている。微妙な違いなので、アノテーションデータをそのまま学習させてもイマイチ成績が伸びない、そこでハイパーパラメータの最適化をやってみた。
まず、学習データを用意して、yamlファイルに記録。utf-8で保存するのが吉。パス文字列にスペースや日本語文字は避けた方が良い。
train: C:/yolov8/data/train/images
val: C:/yolov8/data/valid/images
nc: 4
names: ['stand','walk','work','etc']
ハイパーパラメータ最適化は、yoloのCLIでもできるが、Pythonの方が細かい指示ができる。Pyhtonコードを記述して保存。下記の記述だと、カレントディレクトリの直下にhyper_01というフォルダが出来てその中に最適化に伴う一時ファイルや結果の保存領域になる。nameは指定しなくてもいいみたい。
from ultralytics import YOLO
def tune_model():
# Initialize the YOLO model
model = YOLO("yolov8x.pt")
model.tune(
data="data.yaml",
project='hyper_01',
# name='tune,
batch=0.75, # 割合、バッチ数、-1(自動)のいずれかを指定。
cache='disk',
epochs=30,
workers=12,
imgsz=640,
iterations=1000, # epochs*iterations回の学習をする。
optimizer="AdamW", #
plots=False,
save=False,
val=False
)
if __name__ == '__main__':
tune_model()
activate yolov8
python hyper.py
最適化結果
最適化した結果はhyper_01の下のtuneというフォルダの中に、best_hyperparameters.yamlというファイル名で保存される。
# 1000/1000 iterations complete ✅ (500934.59s)
# Results saved to TUNE\tune
# Best fitness=0.23686 observed at iteration 187
# Best fitness metrics are {'metrics/precision(B)': 0.36849, 'metrics/recall(B)': 0.45872, 'metrics/mAP50(B)': 0.38033, 'metrics/mAP50-95(B)': 0.22092, 'val/box_loss': 0.31801, 'val/cls_loss': 1.05524, 'val/dfl_loss': 0.87819, 'fitness': 0.23686}
# Best fitness model is TUNE\hyper_01
# Best fitness hyperparameters are printed below.
lr0: 0.0017
lrf: 0.01026
momentum: 0.89186
weight_decay: 0.001
warmup_epochs: 2.12453
warmup_momentum: 0.75848
box: 1.59112
cls: 0.32274
dfl: 1.01908
hsv_h: 0.02442
hsv_s: 0.68524
hsv_v: 0.31812
degrees: 0.0
translate: 0.14107
scale: 0.23884
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.20507
bgr: 0.0
mosaic: 1.0
mixup: 0.0
copy_paste: 0.0
最適化ハイパーパラメータの使って学習
yolov5の時は、ハイパーパラメータのyamlファイルを指示すればOKだったが、yolov8の場合はCLIでもpythonでもファイルを取りこむオプションが見つけられなかった。公式にも記載が無いみたい。下記のようにpythonのコードを書いて実行する。
from ultralytics import YOLO
def train_model():
model = YOLO('yolov8x.pt') # YOLOv8のモデルをロード
model.train(
data="data.yaml",
name='HOGE1',
batch=0.75,
workers=12,
imgsz=640,
epochs=2000,
cache='disk',
# ↓↓いろいろ試したがこういう指示はできなかった
# hyp='best_hyperparameters.yaml'
lr0=0.0017,
lrf=0.01026,
momentum=0.89186,
weight_decay=0.001,
warmup_epochs=2.12453,
warmup_momentum=0.75848,
box=1.59112,
cls=0.32274,
dfl=1.01908,
hsv_h=0.02442,
hsv_s=0.68524,
hsv_v=0.31812,
degrees=0.0,
translate=0.14107,
scale=0.23884,
shear=0.0,
perspective=0.0,
flipud=0.0,
fliplr=0.20507,
bgr=0.0,
mosaic=1.0,
mixup=0.0,
copy_paste=0.0
)
if __name__ == '__main__':
train_model()
あんまり良くならないなあ
最適化ハイパーパラメータを使って、学習をやってみたのだが、あまり改善しなかった。mAP50-95値は0.22止まり。最適化前と変わらない、というか悪くなっている。それでどんな最適化をしているのか、経過を見てみると下図のようになっていた。(図はmAP50-95ではなくてfitness値)
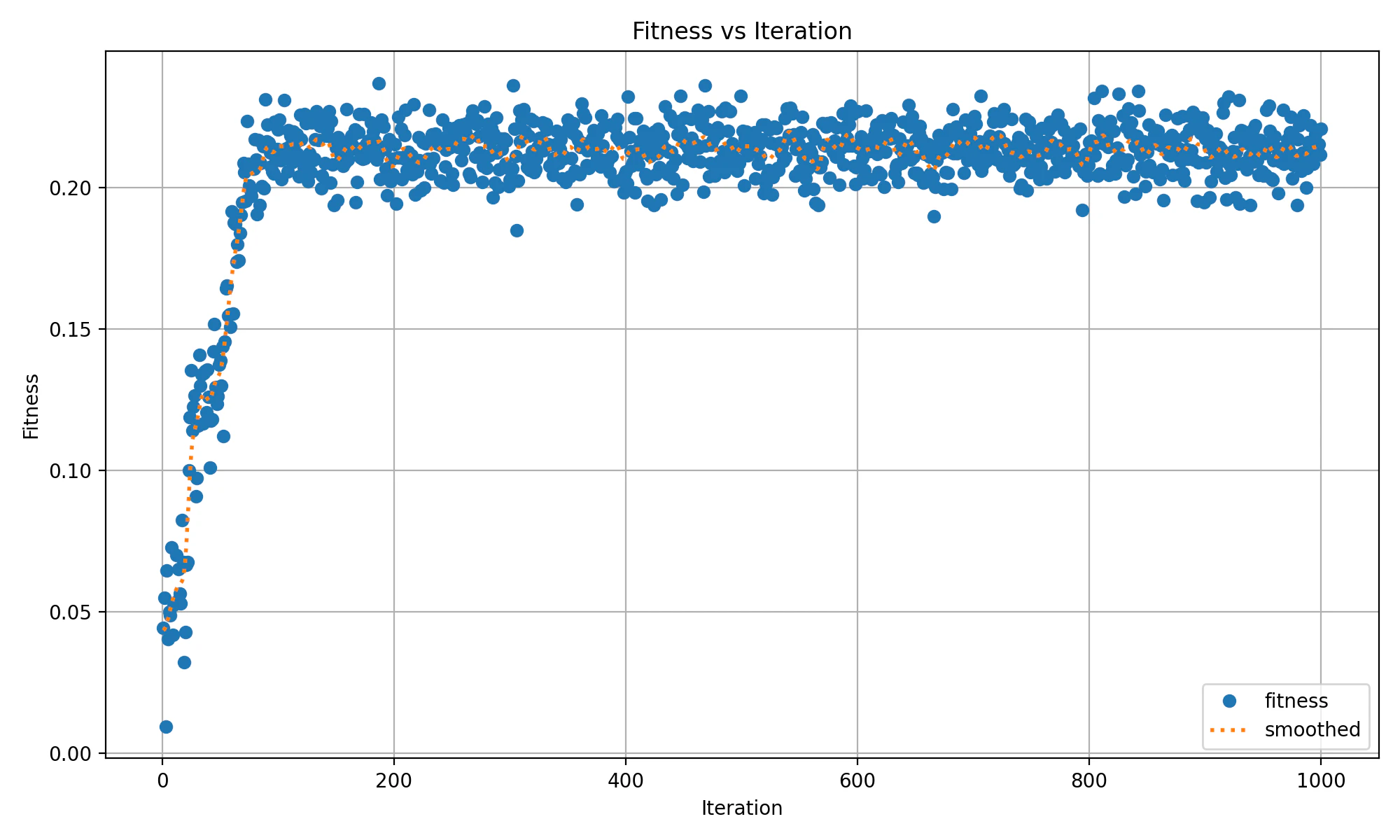
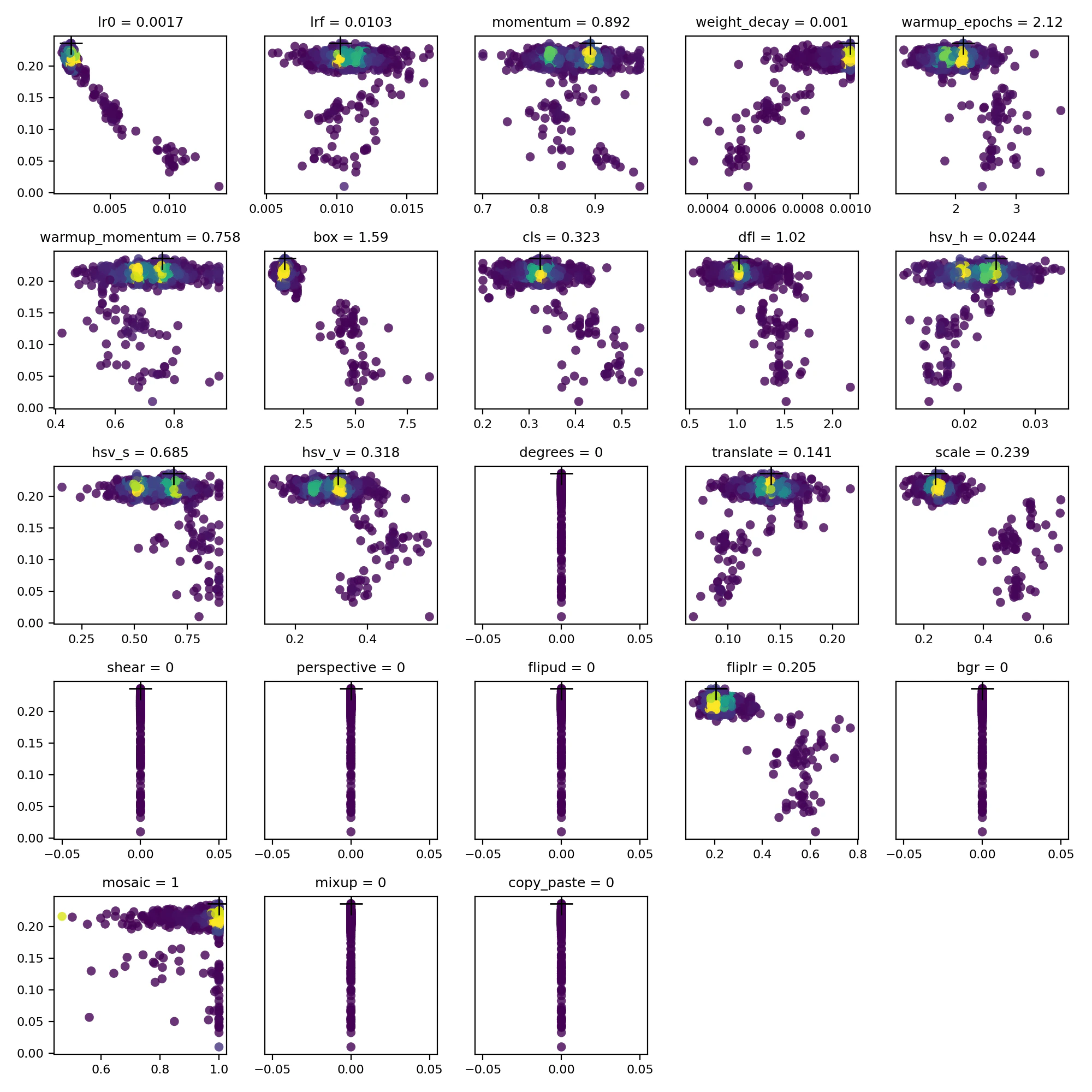
で、気になったのはハイパーパラメータのscaleの値と、収束の様子。最終的に約0.23という値になっている。scaleは画像を縮小して学習するという事ではないのか。公式は下記の記述である。

scaleは、画像を縮小するときの倍率なのか、縮小する画像の数の割合なのか? 素直に読むと縮小倍率のようだが、念のためChatGPTに聞いてみる。
この説明を見る限り、scaleは「画像全体のスケール変化の範囲」を指定するものです。
具体的には、画像を縮小または拡大する際の「倍率」を指定するハイパーパラメータです。
ポイント
縮小/拡大の倍率: scaleは「画像全体のランダムスケーリングの倍率」を意味します。
値が 0.0 に近い場合: 極端に縮小されます。
値が 0.9 の場合: 拡大される割合が少ない(ほぼ元のサイズに近い)。
ランダムに指定された範囲内で倍率が適用されます(例えば 0.0~0.9)。
画像の数の割合ではない: これは、特定の画像が拡縮される「割合」ではなく、
拡大または縮小される「スケール値」の範囲を指します。
やはりscaleは画像を縮小または拡大する際の「倍率」とのこと。とすると、認識したい人物は比較的小さい映像が多いので、0.23倍とかに縮小すると検出率が下がるような気がする。PowerBIでさらに学習経過を見てみる。
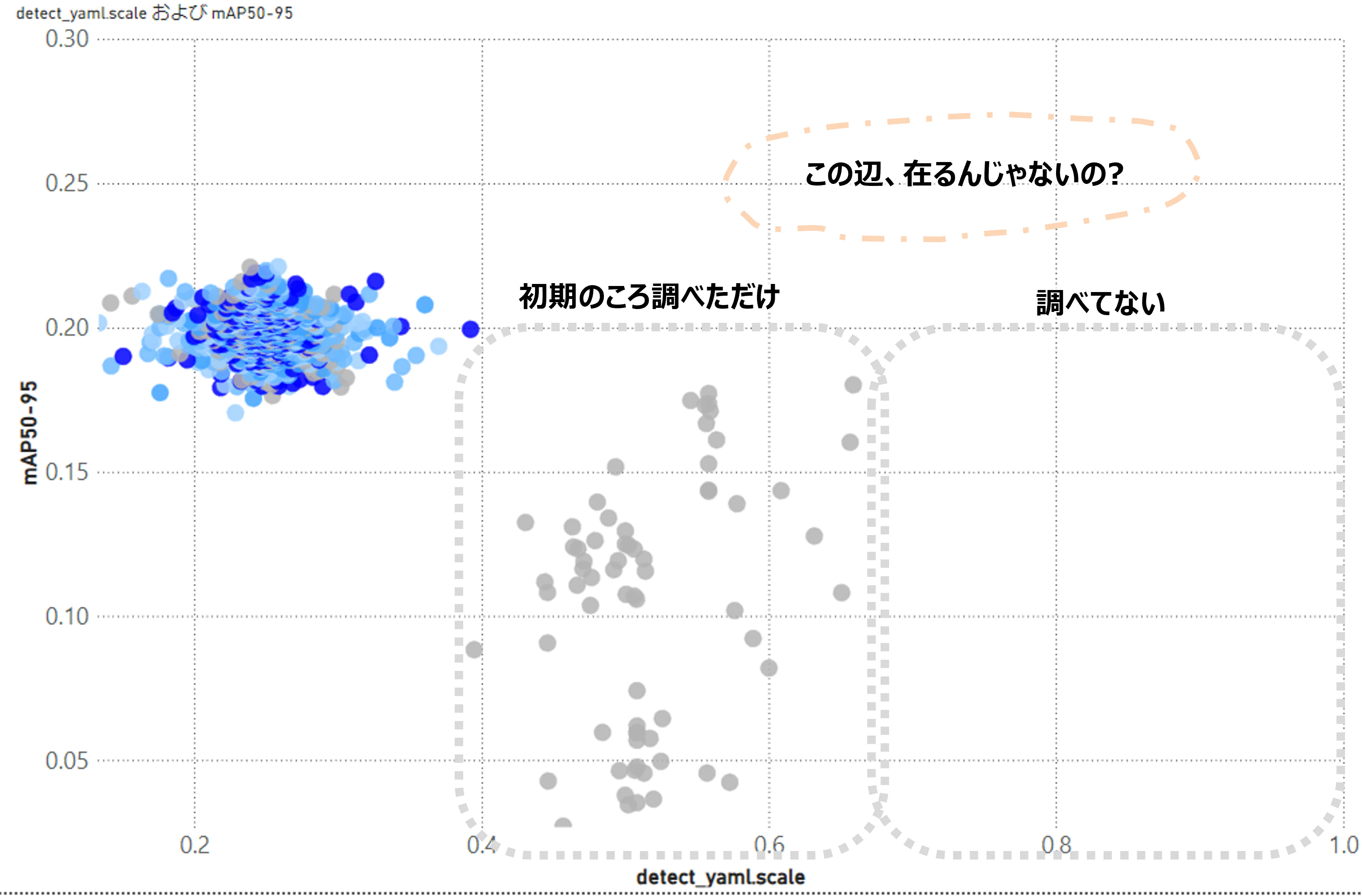
ドットの色は最適化回数の値を表している。濃いほど後に行われた最適化になる。scaleの値が大きい(0.5以上)辺りは、初期のころちょこっと調べただけのようだ。なぜかすぐにscaleは小さい値に収束してしまっている。コレハナンダカオカシイ。
というわけで、scaleが大きい辺りを強制的に指定して再度最適化を行ってみる。
探索範囲指定でハイパーパラメータ最適化
パラメータを探索範囲指定して最適化するには、spaceオプションを指定する。下記の例ではscaleの探索範囲を0.8-1.0に指定している。
from ultralytics import YOLO
# Define search space
# ここで指定した値しか変化しない
# 各行のコメントの数値は前回最適化の時の値
search_space = {
"lr0": (1e-5, 1e-1), #lr0=0.00249
"lrf": (0.01, 1.0), #lrf=0.00922
"momentum": (0.6, 0.98), #momentum=0.80828
"weight_decay": (0.0, 0.001), #0.001
"warmup_epochs": (0.0, 5.0), #2.12453
"warmup_momentum": (0.0, 0.95), #0.75848
"box": (0.02, 0.2), #1.59112
"cls": (0.2, 4.0), #0.32274
"dfl": (0.5, 2.5), #1.01908
"hsv_h": (0.0, 0.1), #0.02442
"hsv_s": (0.0, 0.9), #0.68524
"hsv_v": (0.0, 0.9), #0.31812
"translate": (0.0, 0.9), #0.14107
"shear": (0.0, 0.0), #0.0
"perspective": (0.0, 0.0), #0.0
"flipud": (0.0, 0.0), #0.0
"fliplr": (0.0, 1.0), #0.20507
"bgr": (0.0, 0.0), #0.0
"mosaic": (1.0, 1.0), #1.0
"mixup": (0.5, 0.5), #0.0
"copy_paste": (0.0, 0.0), #0.0
"scale": (0.8, 1.0), #0.23884 ここの範囲を絞る
}
def tune_model():
# Initialize the YOLO model
model = YOLO("yolov8x.pt")
model.tune(
data="data.yaml",
project='hyper_02',
batch=0.75,
cache='disk',
epochs=30,
workers=12,
imgsz=640,
iterations=1000,
optimizer="AdamW",
space=search_space,
plots=False,
save=False,
val=False,
#mosaic=1.0,
#mixup=0.5,
)
if __name__ == '__main__':
tune_model()
まだまだ最適化の最中だが、350回目の最適化でmAP50-95値が0.25ほどに達している。まだ右肩上がりなので、まだ伸びそうだ。前回は100回目の最適化でmAP50-95値が0.22くらいで頭打ちになったので、けっこう改善しているのではなかろうか。mAP50-95値とscale値の関係を見てみるとやはりscale=0.8以上でも上の方に最適値があるようだ。
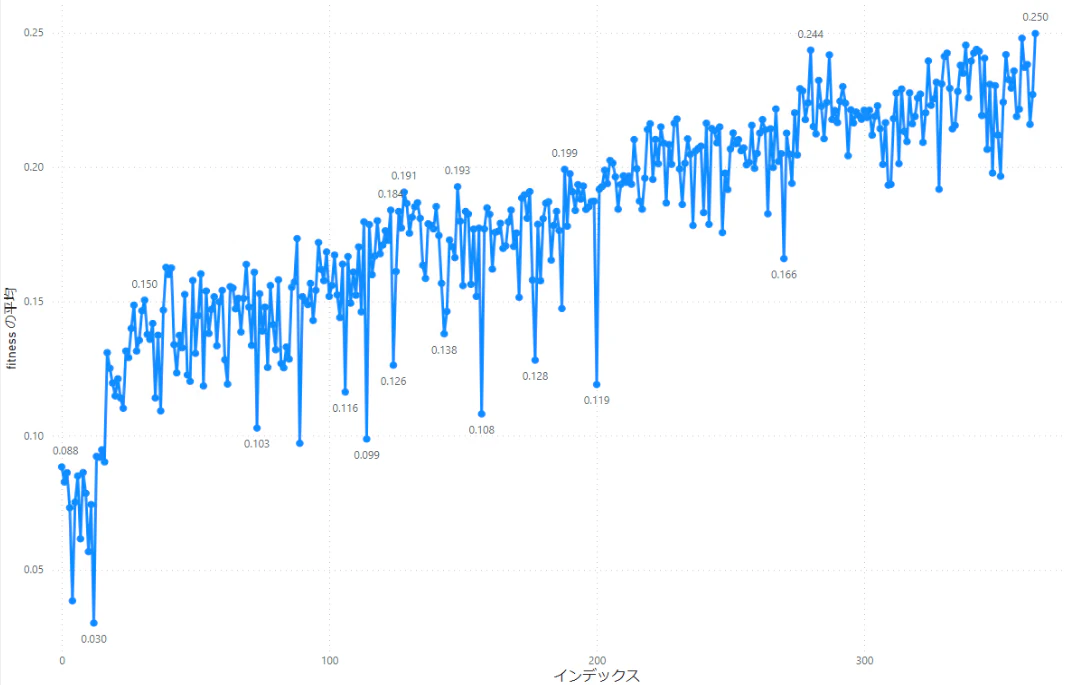
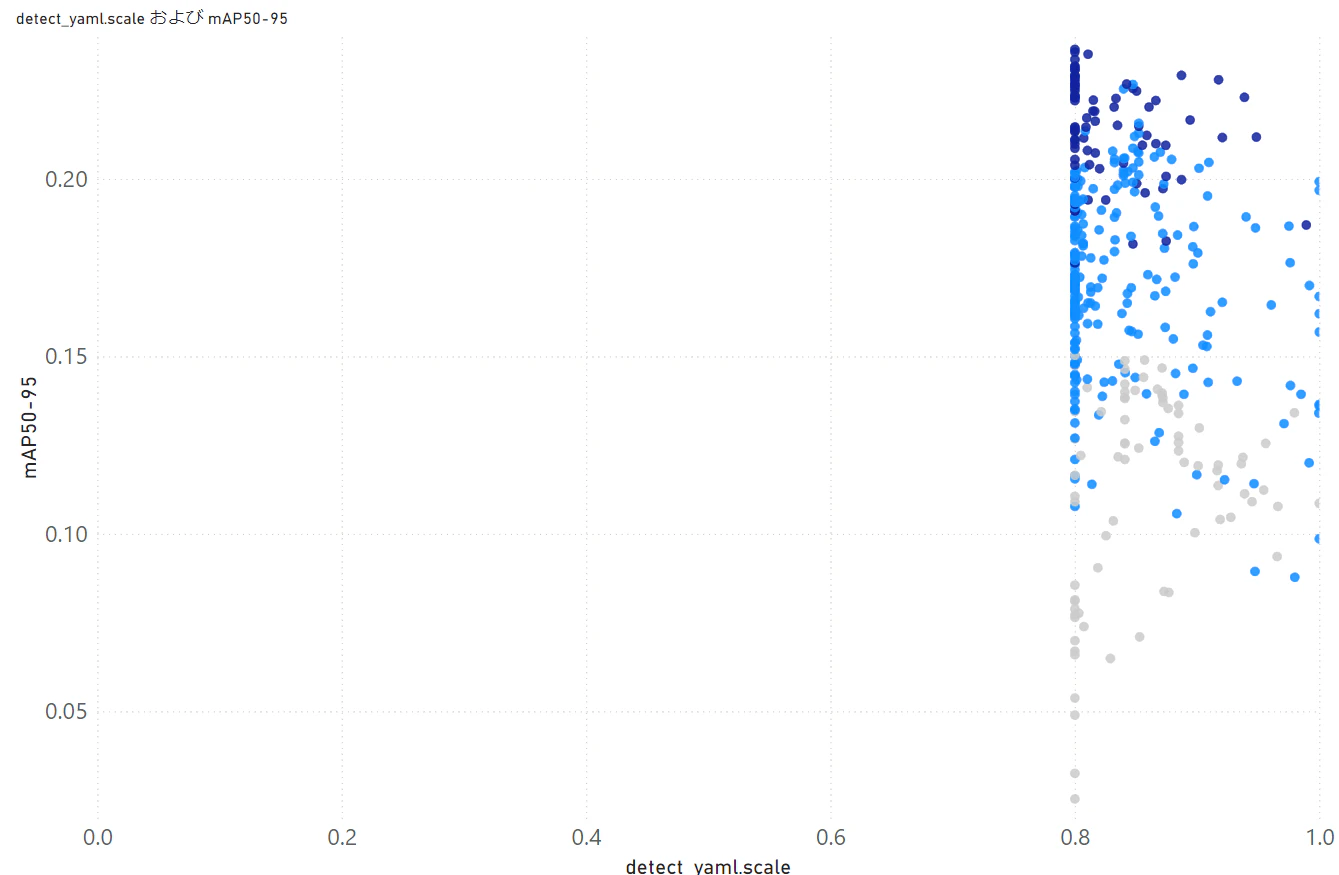
2日で350回なので、1000回まわすのにあと3,4日くらいはかかりそうだ。
[追記予定]