botterのぴぴです。
https://qiita.com/advent-calendar/2021/botter
仮想通貨botter Advent Calender 2021のシリーズ2の23日目の記事です。
アドカレというせっかくのいい機会なので直近で取り組んでいたことをここに残そうと思い記事を書きました。
この記事に関して質問、誤りのご指摘等ありましたらぜひコメントお願いします!
価格帯別出来高(VPR:volume price range)
Twitterで裁量トレーダーの方が「VPVRがhogehoge〜(出来高バーが横についているチャートの画像が添えられている)」と呟いているのをよく見かけます。
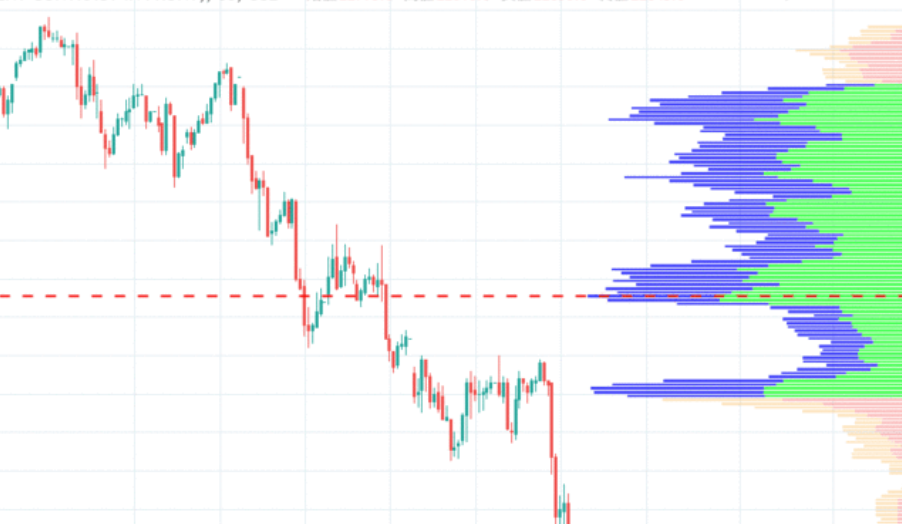
横向き出来高バーみたいなのが価格帯別出来高(VPR:volume price range)といい、似たようなものがいろいろあります。
・チャート全体のVPRを計算するもの(可視範囲出来高,VPVR:volume profile visible range)。
・1日ごとにVPRを計算するもの(VPVS)。
・ユーザーが指定した期間で計算するもの。
詳しい説明は以下を参照ください。
最も出来高の多い価格帯はPOC(point of controll)と呼ばれ、反発線/支持線として意識されます。
さらにPOC周辺の出来高の多い価格帯で全体の70%をカバーする価格領域はVA(value area)と呼ばれ、これも同様です。
なかなか良さそうですね。ぜひmlの特徴量に加えたい。
特徴量に加えたい! でも面倒なことも、、
VPRを使った特徴量としては、「現在価格/移動平均とPOC/VA high/VA lowの距離」「現在価格がVA内なのか外なのか」などが考えられるでしょうか。
しかし、mlの特徴量に入れるとなると全期間通じて値幅固定にするとうまくいかなそうです。
BTCが50万円のころの5万円値幅と500万円のころの5万円値幅では意味がぜんぜん違います。
500万円のころは5万円で価格帯を取って、100万円のころは1万円で価格帯を取って、、、というふうにその時点における大体の価格を元に値幅を変えなくてはいけないでしょう。
これについては後でもう一度触れることにして、
とりあえず固定値幅で実装を作ってみました。
固定値幅で価格帯を決めた実装
実装においては、上記のトレビューの定義を参考にしています。
ローソク足のDataFrameと値幅groupbyと集計期間window、VAの閾値を指定してVPRを得る関数です。
def calc_vpr(df,groupby,window=0,value_area=0.7):
"""
OHLCVから価格帯別出来高を計算して返す。
:param df:OHLCVデータ。timestamp,open,high,low,close,volumeをカラムに持つ。
:param groupby:価格帯の値幅。
:param window:集計するローソク足の本数。0のとき無限。
:param value_area:VA計算のための閾値。0.7(=70%)が一般的。
"""
df["price_range"]=df["close"]//groupby
ts=df["timestamp"].values
cl=df["close"].values
pr=df["price_range"].values
vl=df["volume"].values
d={} # 集計用変数
ary=[] # 集計値保存用配列
d["timestamp"]=None
d["close"]=None
d["groupby"]=None
d["poc"]=None
d["va_high"]=None
d["va_low"]=None
d["profile_high"]=None
d["profile_low"]=None
time_span=min([y-x for x,y in zip(ts,ts[1:])]) # ローソク足の時間幅
idx_start=0 # 集計期間開始idx
pr_set=set()# 価格帯リスト
for idx_end in range(len(df)):
"""
時刻ts[idx_end]時点のデータをts[idx_start]~ts[idx_end]で計算
"""
d["timestamp"]=ts[idx_end]
d["close"]=cl[idx_end]
# indexの調整、VPRの計算
while window>0 and ts[idx_end]-ts[idx_start]>=window*time_span:
d[pr[idx_start]]-=vl[idx_start]
if d[pr[idx_start]]<1e-6:# 出来高0の価格帯は削除。誤差を考慮し1e-6未満を削除
d.pop(pr[idx_start])
pr_set.discard(pr[idx_start])
idx_start+=1
if pr[idx_end] in d:
d[pr[idx_end]]+=vl[idx_end]
else:
d[pr[idx_end]]=vl[idx_end]
pr_set.add(pr[idx_end])
# POCの計算
poc_vol=0
poc=0
sum_vol=0
for k in pr_set:
v=d[k]
sum_vol+=v
if v>poc_vol:
poc_vol=v
poc=k
pr_high=max(pr_set)
pr_low=min(pr_set)
# VAの計算
va_high_price=poc
va_low_price=poc
va_vol=poc_vol
while va_vol<sum_vol*value_area:
# 現在のVAの高値側の外のVPRと安値側の外のVPRを2行ずつ比較し、出来高の多いほうをVAに入れる。
high_vol=0
if va_high_price+1 in pr_set:
high_vol+=d[va_high_price+1]
va_high_price_=va_high_price+1
if va_high_price+2 in pr_set:
high_vol+=d[va_high_price+2]
va_high_price_=va_high_price+2
low_vol=0
if va_low_price-1 in pr_set:
low_vol+=d[va_low_price-1]
va_low_price_=va_low_price-1
if va_low_price-2 in pr_set:
low_vol+=d[va_low_price-2]
va_low_price_=va_low_price-2
if low_vol==high_vol==0:
va_low_price=max(pr_low,va_low_price-1)
va_high_price=min(pr_high,va_high_price+1)
elif high_vol>low_vol:
va_vol+=high_vol
va_high_price=va_high_price_
else:
va_vol+=low_vol
va_low_price=va_low_price_
d["poc"]=poc*groupby
d["va_high"]=va_high_price*groupby
d["va_low"]=va_low_price*groupby
d["profile_high"]=pr_high*groupby
d["profile_low"]=pr_low*groupby
ary.append(d.copy())
vpr=to_df_with_datetime(pd.DataFrame(ary).fillna(0))
ren=[x for x in vpr.columns if type(x) is not str]
ren={x:int(x*groupby) for x in ren}
vpr=vpr.rename(columns=ren)
vpr["groupby"]=groupby
return vpr
"""
Liquid BTCJPY 2021/1/1~2021/12/1 1時間足 window=0 groupby=50000で実行した結果
timestamp close groupby poc va_high va_low profile_high profile_low 2950000 2900000 ... 7250000 7500000 7600000 7550000 7400000 7450000 7150000 7650000 7700000 7750000
datetime
2021-01-01 00:00:00+09:00 1609426800 2958610.0 50000 2950000.0 2950000.0 2950000.0 2950000.0 2950000.0 671.864150 0.000000 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2021-01-01 01:00:00+09:00 1609430400 2919118.0 50000 2950000.0 2950000.0 2900000.0 2950000.0 2900000.0 671.864150 375.206489 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2021-01-01 02:00:00+09:00 1609434000 2937665.0 50000 2950000.0 2950000.0 2900000.0 2950000.0 2900000.0 671.864150 638.380051 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2021-01-01 03:00:00+09:00 1609437600 2963493.0 50000 2950000.0 2950000.0 2900000.0 2950000.0 2900000.0 979.462875 638.380051 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2021-01-01 04:00:00+09:00 1609441200 2968099.0 50000 2950000.0 2950000.0 2900000.0 2950000.0 2900000.0 1243.421583 638.380051 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.
"""
上の実装で出てくる自作関数
def to_df_with_datetime(data):
"""
データをdatetimeをインデックスとするpandas.DataFrameにして返す
:parmas data:dict型を要素に持つ配列またはDataFrame。dictはkeysにtimestampを持つ。DataFrameはカラムにtimestampを持つ。
"""
df=pd.DataFrame(data)
df["datetime"]=pd.to_datetime(df["timestamp"], unit='s')
df=df.set_index("datetime")
df=df.tz_localize('utc').tz_convert('Asia/Tokyo')
return df
計算量はローソク足の本数を$N$、window内の価格帯の数の平均を$d$として$O(dN)$です。
groupbyとwindowの値によりますが、$d$は多く見積もっても100は超えない気がするので、これを定数とみなせば定数倍重めの$0(N)$で計算可能です。
描画してみる
チャートに描画するとどういう処理をしているのかわかりやすいと思います。
def vpr_plot(ax,vpr,groupby=None,y_min=None,y_max=None):
"""
matplotlibのAxisオブジェクトに価格帯別出来高をプロットする
:param ax:matplotlibのAxisオブジェクト
:param vpr:価格帯別出来高データ。カラムに価格帯、データに出来高。
:param groupby:価格帯の値幅
:param y_min,y_max:縦軸の描画範囲を指定する。
"""
pr=[x for x in list(vpr.columns.values) if type(x) is not str]
if groupby is None:
pr.sort()
groupby=min([y-x for x,y in zip(pr,pr[1:])])
vl=list(vpr.loc[vpr.index[-1],pr].values)
ax.barh(pr,vl,height=groupby,alpha=0.5)
if y_max is None:y_max=max(pr)+groupby
if y_min is None:y_min=min(pr)-groupby
ax.set_ylim(y_min,y_max)
ax.grid()
def ohlcv_plot(ax,df):
# 省略。実装は参考のリンクを参照
"""
df_1day:1日足
df_1hour:1時間足
"""
groupby=50000 # 値幅5万でグルーピング
plt.figure()
ax=plt.subplot2grid((1,4),(0,0),colspan=3)
ohlcv_plot(ax,df_1day)
y_min,y_max=ax.get_ylim()
vpr=calc_vpr(df_1hour,groupby=groupby)
ax=plt.subplot2grid((1,4),(0,3))
vpr_plot(ax,vpr,groupby=groupby,y_min=y_min,y_max=y_max)
ax.tick_params(labelbottom=False,labelleft=False,labelright=False,labeltop=False)
plt.show()
こんな感じです。
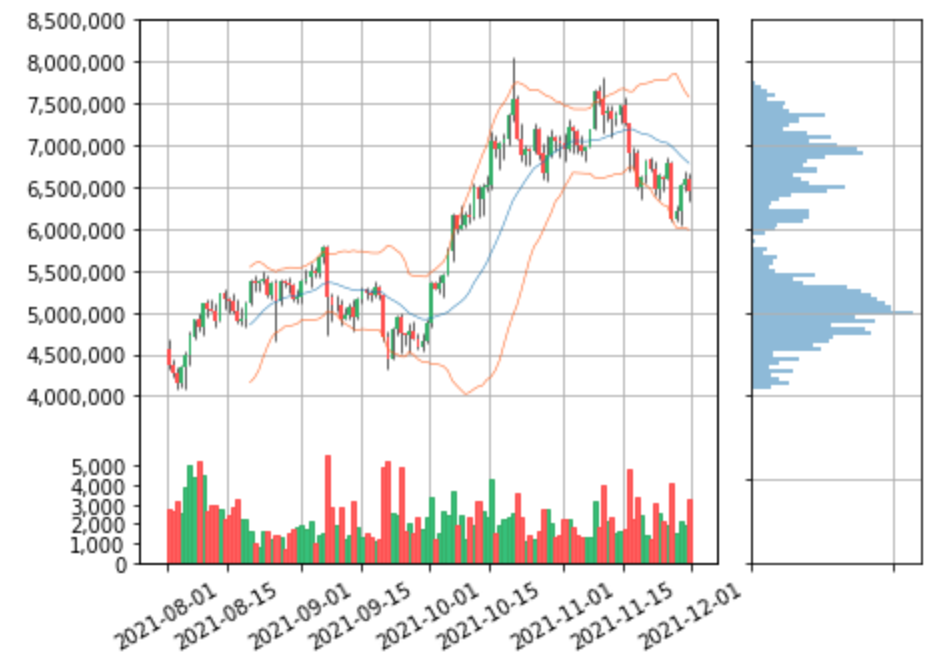
よくみるチャートっぽい!
わたしの実装したcalc_vprでは出来高にbuy/sellの区別をしていませんが、陽線のローソク足の出来高をbuy、陰線の出来高をsellとして区別すればトレビューのチャートっぽいのが出来上がると思います。
VPRって本当に効くのか?
BTCの値動きをgifにしてみました。データはbybit BTCUSDインバース。
qiitaに貼ろうとしたら永遠に[Something went wrong]で貼れなかったのでわたしのtweetのリンクを貼ります。
出来高の山がある価格帯で反発したり、支持したり、反対に出来高がない価格帯では価格が走ったりしているように見えなくもない〜??、のかな〜???という感じです。
価格帯の値幅を動的に設定する
はじめの方でも触れましたが、特徴量を作る際、全期間渡って価格帯の値幅を固定にすると学習に失敗すると思います。
そこで価格帯の値幅をそのときの価格で決定するような実装を作ってみました。
具体的には与えられたローソク足で期間12移動平均の1%の値幅をその時点のgroupbyします。
ローソク足1本追加するごとにgroupbyとVPRを計算しなおします。ただしgroupbyが変わらない間は前の計算結果を引き継ぎます。
最悪計算量はローソク足の本数を$N$として$O(N*window)$ですが、実際はこれより早く処理できます。
実験してみると上で実装した固定値幅のものに比べ僅かに時間がかかるぐらいで、ほぼ$O(N)$です。
def calc_vpr_dynamic_groupby(df,groupby_step,window=0,value_area=0.7):
"""
OHLCVから価格帯別出来高を計算して返す。
価格帯の値幅を動的に設定する。期間12移動平均の1%の値幅をその時点のgroupbyとする。
:param df:OHLCVデータ。timestamp,open,high,low,close,volumeをカラムに持つ。
:param groupby_step:groupbyの刻み値。
:param window:集計するローソク足の本数。0のとき無限。
:param value_area:VA計算のための閾値。0.7(=70%)が一般的。
"""
df["sma"]=df["close"].rolling(window=12,min_periods=1).mean()
df["groupby"]=df["sma"]//100
df["groupby"]=np.where(df["groupby"]>groupby_step,df["groupby"]-df["groupby"]%groupby_step,df["groupby"]-df["groupby"]%(groupby_step//10))
ts=df["timestamp"].values
cl=df["close"].values
sma=df["sma"].values
vl=df["volume"].values
gb=df["groupby"].values
ary=[] # 集計値保存用配列
time_span=min([y-x for x,y in zip(ts,ts[1:])]) # ローソク足の時間幅
idx_start=0 # 集計期間開始idx
pr_set=set()# 価格帯リスト
d={} # 集計用変数
pre_d={} # 集計用変数
pre_groupby=-1
for idx_end in range(len(df)):
"""
時刻ts[idx_end]時点のデータをts[idx_start]~ts[idx_end]で計算
"""
d={} # 集計用変数
d["timestamp"]=ts[idx_end]
d["close"]=cl[idx_end]
d["sma"]=sma[idx_end]
d["groupby"]=gb[idx_end]
d["poc"]=None
d["va_high"]=None
d["va_low"]=None
d["profile_high"]=None
d["profile_low"]=None
# index調整
idx_del=[]
while window>0 and ts[idx_end]-ts[idx_start]>=window*time_span:
idx_del.append(idx_start)
idx_start+=1
# VPRの計算
if pre_groupby!=gb[idx_end]:
pr_set=set()
for j in range(idx_start,idx_end+1):
k=int(cl[j]//gb[idx_end])
if k not in d:
d[k]=vl[j]
pr_set.add(k)
else:
d[k]+=vl[j]
else:
# 前回とgroupbyが同じ場合、前回の計算結果を利用する
for k in pr_set:
d[k]=pre_d[k]
for j in idx_del:
k=int(cl[j]//gb[idx_end])
d[k]-=vl[j]
k=int(cl[idx_end]//gb[idx_end])
if k not in d:
d[k]=vl[idx_end]
pr_set.add(k)
else:
d[k]+=vl[idx_end]
pre_d=d
pre_groupby=gb[idx_end]
# POCの計算
poc_vol=0
poc=0
sum_vol=0
for k in pr_set:
v=d[k]
sum_vol+=v
if v>poc_vol:
poc_vol=v
poc=k
pr_high=max(pr_set)
pr_low=min(pr_set)
# VAの計算
va_high_price=poc
va_low_price=poc
va_vol=poc_vol
while va_vol<sum_vol*value_area:
# 現在のVAの高値側の外のVPRと安値側の外のVPRを2行ずつ比較し、出来高の多いほうをVPRに入れる。
high_vol=0
if va_high_price+1 in pr_set:
high_vol+=d[va_high_price+1]
va_high_price_=va_high_price+1
if va_high_price+2 in pr_set:
high_vol+=d[va_high_price+2]
va_high_price_=va_high_price+2
low_vol=0
if va_low_price-1 in pr_set:
low_vol+=d[va_low_price-1]
va_low_price_=va_low_price-1
if va_low_price-2 in pr_set:
low_vol+=d[va_low_price-2]
va_low_price_=va_low_price-2
if low_vol==high_vol==0:
va_low_price=max(pr_low,va_low_price-1)
va_high_price=min(pr_high,va_high_price+1)
elif high_vol>low_vol:
va_vol+=high_vol
va_high_price=va_high_price_
else:
va_vol+=low_vol
va_low_price=va_low_price_
d["poc"]=poc
d["va_high"]=va_high_price
d["va_low"]=va_low_price
d["profile_high"]=pr_high
d["profile_low"]=pr_low
ary.append(d)
vpr=to_df_with_datetime(pd.DataFrame(ary).fillna(0))
return vpr
参考
VPRのプロット、ローソク足のプロットは以下を参考にしました。
https://qiita.com/persimmon-persimmon/items/48a5ced6998cc3a79636