###"All the world is happy when Santa Claus comes."
### — Maud McKnight Lindsay
この記事は MicroAd Advent Calendar 2021 の 24 日目の記事です. (※ 記事内で実験などをしていますが, 公開日に間に合わせるためにかなり雑な実装になってしまい, 十分な検証や追試ができていないため正確でない恐れがあります.)
まえがき
今年もこの日がやってきました. そうです. サンタさんが世界中をトナカイと駆け巡り, 子どもたちに幸せとプレゼントを届ける最も幸福で, 最も大変な一日です.
サンタクロースの起源や由来などは諸説ありますが, 今のひげを生やして大きな袋を持ち赤い格好をしたサンタクロースの姿が文化として定着したのはどうやら 1800 年前半あたりのようです1.
また, サンタクロースのプレゼント配りと関連があり, 数学的にも計算機的にも有名な組合せ問題の一つとして巡回セールスマン問題 (Traveling Salesman Problem; TSP) がありますが, なんとこちらの問題も 1800 年前半あたりから解かれだした問題のようです2.
つまり我々はサンタクロースを助けるために日々計算機やアルゴリズムの改良を行っていたと言っても過言ではないわけですね.
巡回セールスマン問題はすごくシンプルな問題で与えられたすべての都市を訪れ, スタート地点に戻ってくるような経路を探す問題になります.
クリスマスのキセキ3によると日本全国の小学校を夜から朝の間に巡るためにはジェット機より速く(マッハ5以上)で日本中をトナカイと共に駆け巡る必要があるそうです.
我々は今まで数百年の歴史を紡ぎ, ありとあらゆる手段を用いてサンタクロースを救うべく巡回セールスマン問題に取り組んで来たわけですが, 現在この問題に対して有効的なアプローチとしては以下の 2 つの手法が知られています.
どちらも非常に優れたアルゴリズムで, ものすごくざっくりとしたところだけ述べると LKH は新たな経路を生成するための変換が上手く, EAX は良い部分経路を保持するのが優秀な印象があります.
また, 近年__深層強化学習とかいうので学習すれば何でもいい感じに解いてくれる世界になってほしい__という願望が巷で渦巻いており, この深層強化学習を用いてこの問題を解こうとしているものもいくつかあります. 自身は機械学習などを今まで扱ってきていないので, あまり最新のことなどはわかりませんが, 基本的にこのような問題とは非常に相性が悪そうであるため大規模な問題に対して良い性能を出すのはまだまだ難しそうに思えます.
この問題に対する機械学習を用いた無難なアプローチとしては複数の都市の中からより探索すべき部分都市の集合を推定し, その辺りなどをヒューリスティックなアルゴリズムを用いて解いていくというのが直感的には良さそうに思えなくもないのですが, 個人的にはシンプルに強化学習のみでアプローチした場合にどのような特徴を良しとして学習しようとするのかに興味があります.
学習した際の結果からどのようなことを学習しているのかを分析できるのかどうか, それとも人間の解釈に頼るしかないのかは知らないのですが, ひとまず__深層強化学習で巡回セールスマン問題を解いてみる__ということを目標にしようと思います.
検証
今回は TSP に対する深層強化学習のオーソドックスな手法かはわかりませんが, 以下の論文を元に TSP へ適用しています.
Neural Combinatorial Optimization with Reinforcement Learning
なお, 正確な実装ができているかなどの追試はできておらず, 色々間に合わなかったのでやりたかった検証もかなりできていません.
まずは 10 都市での学習結果からです.
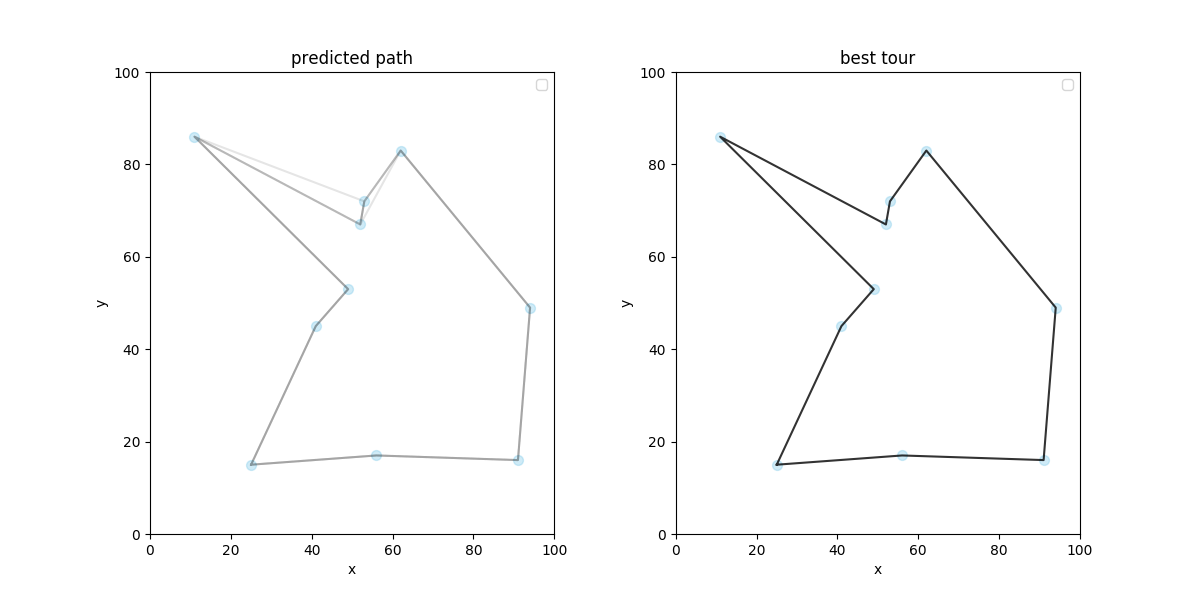
案外いい感じに学んでくれていますね. 次に 20 都市での学習結果です.
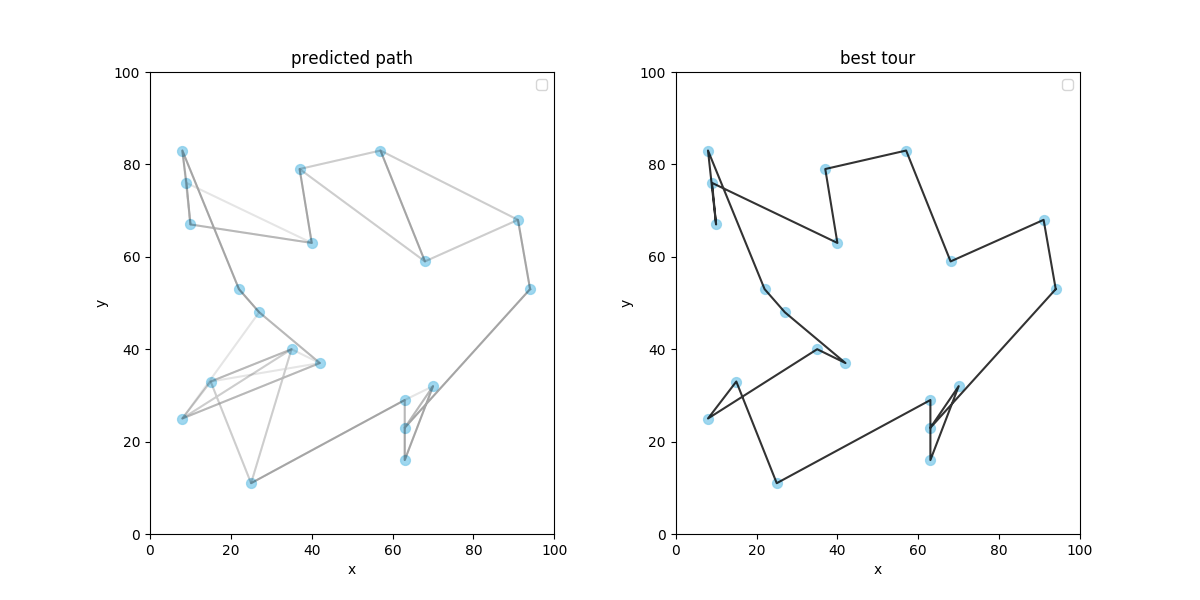
20 都市では経路が交差したりして苦しい解が出ていますね...
続いて, 20 都市で学習した成果を用いて 100 都市を解いてみます.
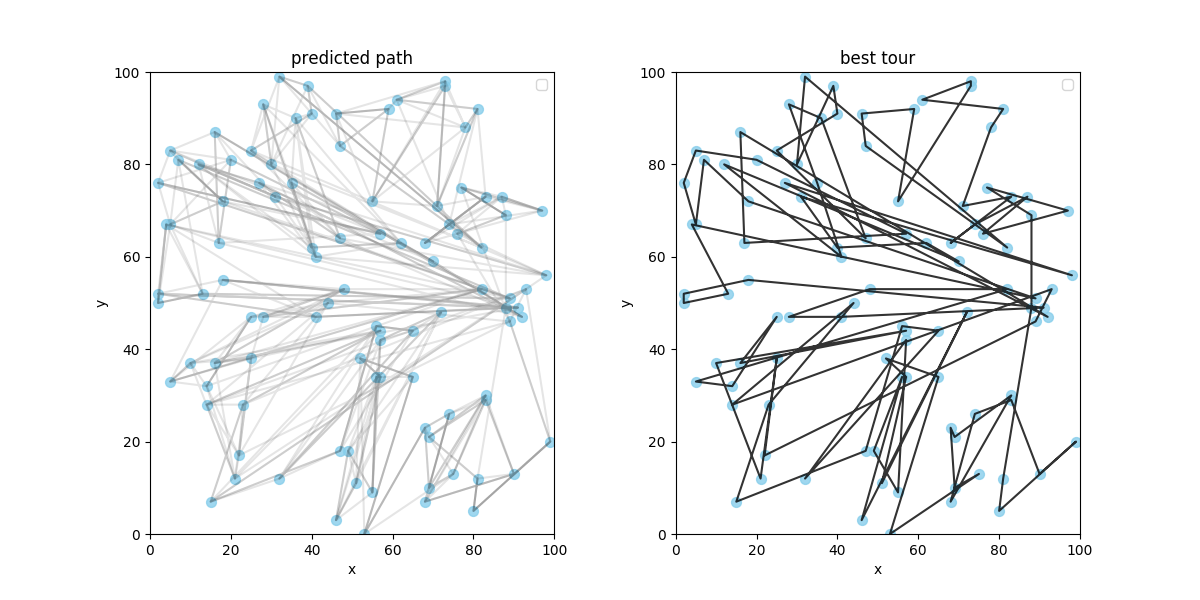
案の定, 目も当てられないような結果になりましたが, 別の環境で学んだことを新たな環境でも試せるのはすばらしいですね.
それに全体的に見るともちろん悪い結果ですが, 部分的には悪くない経路もちらほら見られるので少し嬉しいです.
最後に 10 都市で学習していたときと, 20 都市で学習していたときの報酬関数などの推移を見てみます.
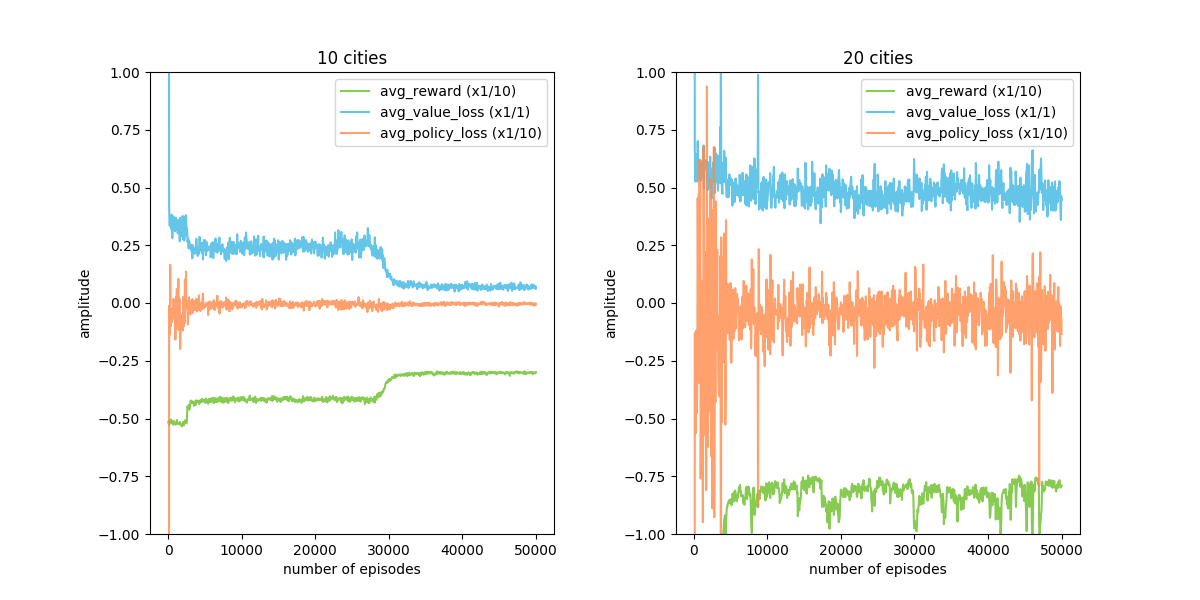
10 都市で学習していた際は reward が episode を経るにつれ増加していますが, 20 都市の場合はなかなか良いものが見つかっていなさそうです. また, 改善が得られた 10 都市の方に関してもかなり学習をさせ続けないと改善が得られていないのでこの辺りが都市の増加によってかなり厳しくなってきそうです.
本当は National TSP に日本地図の問題 (9,847 Cities) が公開されているので, これを解いて見ようかとも思ったのですが, 100 都市で今のような結果ですと1000 都市以上はなんとも言えない結果になりそうです.
最適解は得られずとも, 経路が交差しないような巡路が得られれば嬉しいなと思っていたのですが今回のアプローチでは厳しそうです.
もちろん, 実装が不適切な可能性もあるので追試なども行いつつ見直して見ようと思います.
あとがき
どうやら世界中のサンタさんには今年も頑張っていただくことになりそうです. 最新の論文はまだ漁りきれていないですし, 有名所?だと ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS! などもあるのでしょうか.
今回はかなり簡易な形になってしまったので, 引き続き追試や最新の論文を見ながら早く世界中のサンタクロースが幸せになれる世界を願っています.