「リアクティブプログラミング」「Observable」などのキーワードを聞いたことはあるけど何なのかまでは知らない、という人向けに、リアクティブプログラミングが何なのか・どうやって使うのか・使うと何が嬉しいのか、などを分かりやすく解説した記事があったらよかったなと思い、書いてみました。
「Observable」で調べてみると、「“時間とともに変化する”値を表すデータ型」、「非同期データソース(ストリーム)を表すクラス」などといった小難しい説明が出てきます。
これだけだと何のことか分からないと思うので(私が初学者のときにそうだったので)、まずは「どういうときに(何に困ったときに)使うと嬉しいものか?」「簡単に始めるにはどうすればいいのか?」が分かるところまでを説明したいと思います。
なるべく初心者向けに書いてみたつもりですが、 HTML, JavaScript の基本的な構文などは解説していませんので、ご了承ください。
また、直感的な動作や基本的な使い方の説明を重視したため、厳密な動作原理などは説明していませんのでご注意ください。
導入
本記事は、リアクティブプログラミングを知らない人向けに、代表的なライブラリの一つである RxJS について、そのメリットを実例を通して具体的に紹介することが目的です。
RxJS はリアクティブプログラミングをするための JavaScript のライブラリです。
(Reactive Extension for JavaScript の略)
どういうときに役に立つかというと、「データ取得やテキストボックス・ボタン入力などの多数のイベントが発生する複雑な GUI アプリケーションを実装するとき」「非同期処理をより間違いの起きにくいプログラミングスタイルで実装したいとき」に嬉しいライブラリと言えます。
RxJS は一言で言うと、データフロープログラミングを可能にするライブラリです。
RxJS を利用すると、具体的には
- 変数の値を更新するときに、その値に依存している他の変数の値を芋づる式に自動的に更新させる
- 変数の値の変更を監視し実行する処理を登録しておく
- 時間変化するデータ全体の加工を直感的に行う
などが可能になります。
これにより、
- グローバル変数の書き換えを減らせる
- プログラムが宣言的になるので可読性が上がる
といったメリットがあります(これらのメリットに関しては他の状態管理ライブラリや React のようなフロントエンドフレームワークを使っても解決できると思うのですが、その比較は本記事の本題ではないので一旦省きます)。
これらの利点を理解して使えるようになるために、次節で説明するようなデータテーブルアプリケーションを実装してみます。RxJS を使わない実装と RxJS を使った実装を比較することで、具体的に RxJS を使うメリットを確認していきます。
キーワード:
RxJS, Observable, JavaScript, リアクティブプログラミング
リアクティブプログラミングとは?
リアクティブプログラミングとはどういうものかを説明するのに、よく表計算ソフト(Excel など)の例が用いられます。
例えば、
- セル A に「1」
- セル B に「= A + 3」
- セル C に「= B * 2」
と入力したとします。すると、C の値は (1 + 3) * 2 で 8 となります。
ここで、セル A の値を「2」に変えると、即座にセル B の値は 5、セル C の値は 10 になります。
このように、セル B、C は、それぞれが依存しているセルの値の変更に応じて自身の値を自動的に更新するので、リアクティブであると言えます。
一方、
let a = 1;
let b = a + 3;
let c = b * 2;
a = 2;
console.log(b, c); // 4, 8
のようなプログラムはリアクティブとは言えません。(aの値を更新してもb、cの値は更新されないので)
これら二つの例の大きな違いは、変数の定義部分が関係を表しているか、ただの代入文であるかという点です。
前者のようなリアクティブな変数定義により、値が変化する変数を宣言的に定義することのメリットは、小さな例では分かりにくいかもしれません。
そのため、今回は少々複雑な例を元に説明しようと思います。
DataTableApp
例として、
フィルタリングとページネーションの機能を持つ次のようなデータテーブルを実装することを考えます。
この DataTableApp のデータの流れを図にすると、以下のようになります。
グラフ中の濃い色のノードはイベント(データの取得、テキストボックス入力)が発生する起点を表しています。
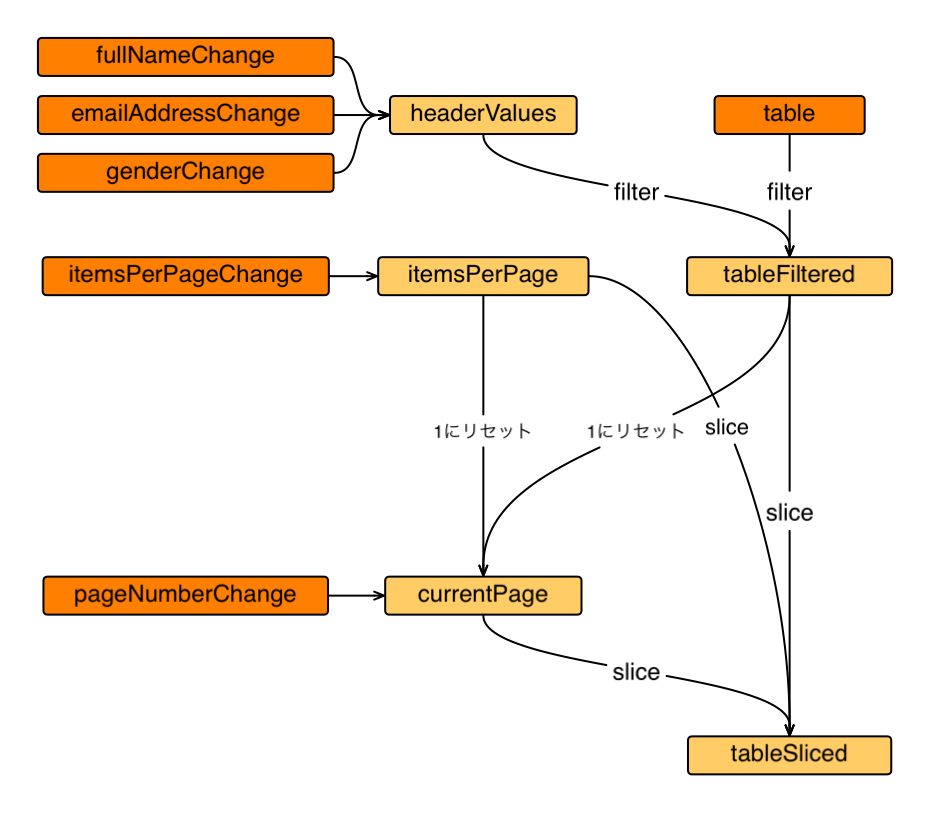
fullNameChange, emailAddressChange, genderChange はテーブルの名前・E-mail・性別の列のフィルタ文字列の変更イベント、 itemsPerPageChange は 1 ページあたりの表示行数の変更イベント、 pageNumber はページの変更イベントを表します。 table は最初のデータ取得時に一度発火するイベントです。
slice は table から現在のページ範囲の行を切り出す処理です。
よくあるフィルタリングとページネーションを行うテーブルですが、少し工夫している部分としては、
- フィルタはテキストボックスの入力が一定時間止むのを待ってから行う(入力途中に何度もフィルタ処理が走って重くなるのを防ぐため)
- フィルタ実行後に表示ページを 1 ページ目にリセット(ページ数が減ったときに存在しないページを表示しないように)
などがあります。
以降は、これをただの JavaScript のみで実装した場合と RxJS を併せて使った場合を説明し、比較していきます。
なお、本記事では RxJS を使う場合と使わない場合の違いを調べることが主な目的であるため、 React などのリアクティビティを実現する他の手段はあえて使わずに実装します。
DataTableApp の実装(非 RxJS 版)
DataTableApp を実装する上で基本的な処理として、ページを変えたとき・テキストボックスに文字が入力されたとき・最初にデータ取得が完了したときなどのイベント発生(発火)時に行う処理を登録する必要があります。
オーソドックスな方法は各イベントの発火に対応する処理を一つずつコールバック関数として記述する方法でしょう。
イベントの発生時処理は、addEventListenerというメソッドで登録することができます。(jQuery における on メソッドのようなもの)
たとえば、
<input type="text" id="full-name" /> <label for="full-name">FullName</label>
というテキストボックスに文字が入力されたときに行う処理は、
document
.getElementById('full-name') // <input type='text' id='full-name'>を指す
.addEventListener('input', (event) => {
/* ここに処理を書く */
});
のように登録できます。(addEventListenerの一つ目の引数は監視するイベントの種類で、'input'ならば文字が入力されるたびに登録した処理を行います。)
event => { /* 処理 */ }という部分はコールバック関数と呼ばれます。(ある関数の引数として渡してその中で実行させる関数のことをコールバック関数と言います。)
名前の列のフィルタリング用テキストボックスに入力があったときに必要な処理を例として記述してみます。
例えば以下のようになります。
document.getElementById('full-name').addEventListener('input', (event) => {
fullName = event.target.value ?? ''; // 名前の列のヘッダのテキストボックスの値
updateTableFiltered(); // テーブルからヘッダ文字列を含む行のみフィルタリング
updateTableSliced(); // 現在ページ部分を切り出し
printTable(); // 表示(htmlの書き換え)
});
ここで、fullName, table, tableFiltered, tableSliced... などの変数は書き換え可能なグローバル変数としてあらかじめ定義してあるとします。(update**ではそれらを更新している)
文字が入力されるたびに毎回フィルタリングを行うと負荷が大きくなってしまうので、間引き処理もします。
先ほどのプログラムに、一定時間(ここでは 100 ミリ秒)内に 2 回以上発火しないように(コールバック関数が呼ばれないように)間引き処理を加えます。かなり読みにくいですが以下のような実装になります。
let timerId;
document
.getElementById('full-name') // idが'full-name'の要素を指す
.addEventListener('input', (event) => {
clearTimeout(timerId); // 前回の予約をキャンセル
timerId = setTimeout(() => {
// 処理を予約し予約番号をtimerIdに控える
headerValues.fullName = event.target.value ?? '';
updateTableFiltered();
updateTableSliced();
printTable();
}, 100); // 100ミリ秒後に処理を予約
});
元の処理をsetTimeoutで処理を 100 ミリ秒後に予約し、それから 100 ミリ秒以内に'input'イベントが発生したらclearTimeoutにより前回の予約をキャンセルし再予約するという仕組みです。
非 RxJS 版の実装の欠点
前節の非 RxJS 版実装にはいくつかの難点があります。
① データの依存関係に忠実に実装するのが簡単でない
非 RxJS 版実装は、冒頭に図示したような依存関係を、データフロー全体から以下の図のように抜き出したものになっています(灰色のノードはイベント発火時に更新はせず値のみを参照している変数を表しています)。
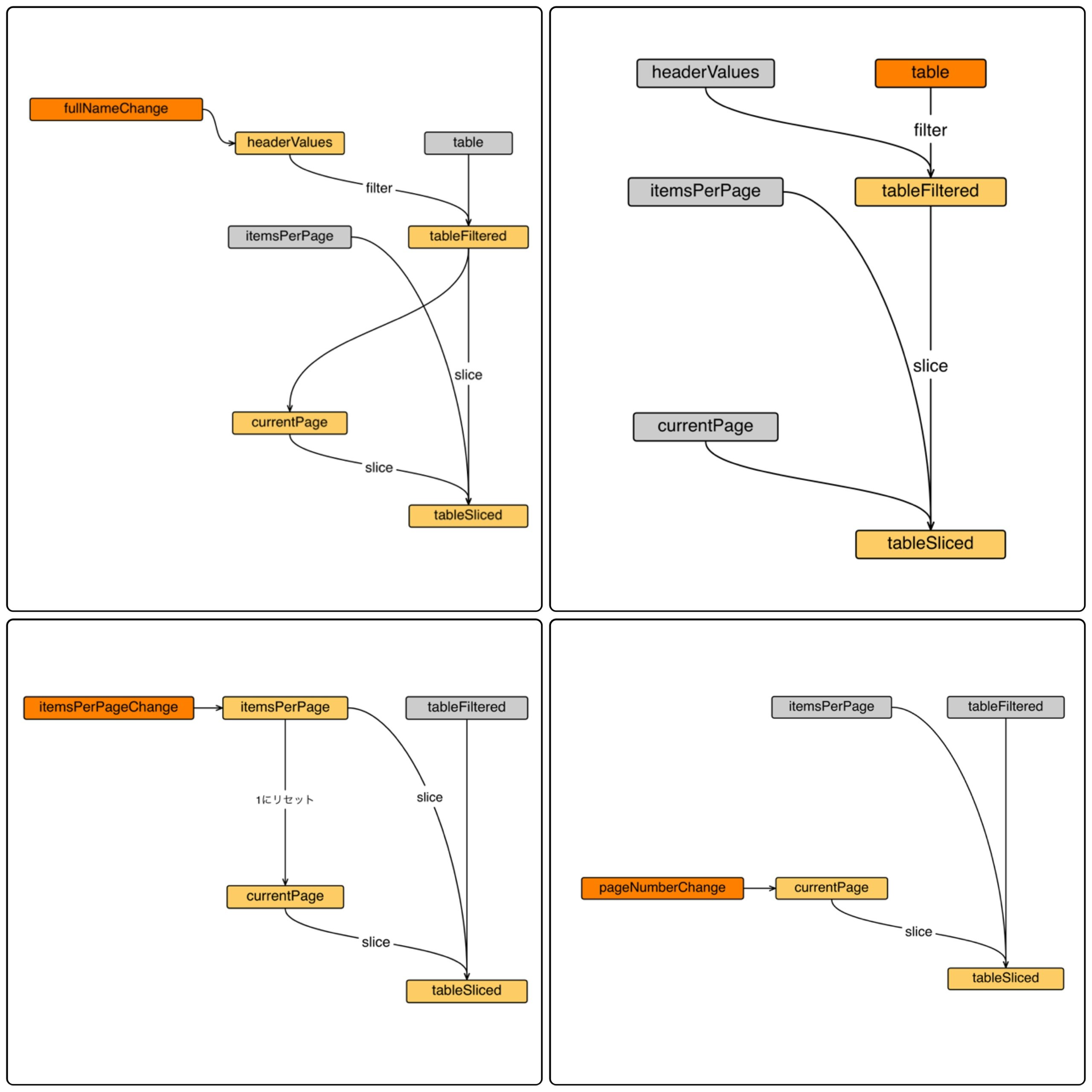
この実装方法は当然のように思われるかもしれませんが、イベント発火時に更新すべき変数全体を見渡せる必要があるため、規模が大きくなってくると把握が難しくなってしまいます。
また、今回のアプリケーションではほぼ無視できますが、複数のイベントがほぼ同時に発火した場合の挙動を制御しづらいという欠点もあります(イベントごとに独立に処理を記述しているため)。
② input イベントに対して行っていた間引き処理の実装が(可能ではあるものの)難しい
前述のsetTimeout/clearTimeoutによる実装は、一見して何をやっているのかわかりづらく、可読性を損なう原因です。
③ グローバル変数の書き換え・参照が多い
イベントごとにコールバック関数に処理を記述する場合、コールバック関数の返り値がなく副作用により状態を変化させるという性質上、必然的に書き換え可能なグローバル変数が必要になります。結果として、各グローバル変数の挙動はプログラム全体を見渡さないと予測できなくなるため、可読性の低いプログラムになってしまいます。
DataTableApp の実装(RxJS 版)
RxJS を用いると、非 RxJS 版実装の欠点をきれいに解決することができます。
RxJS 版実装では、依存関係グラフを以下の図のように分解して実装します。
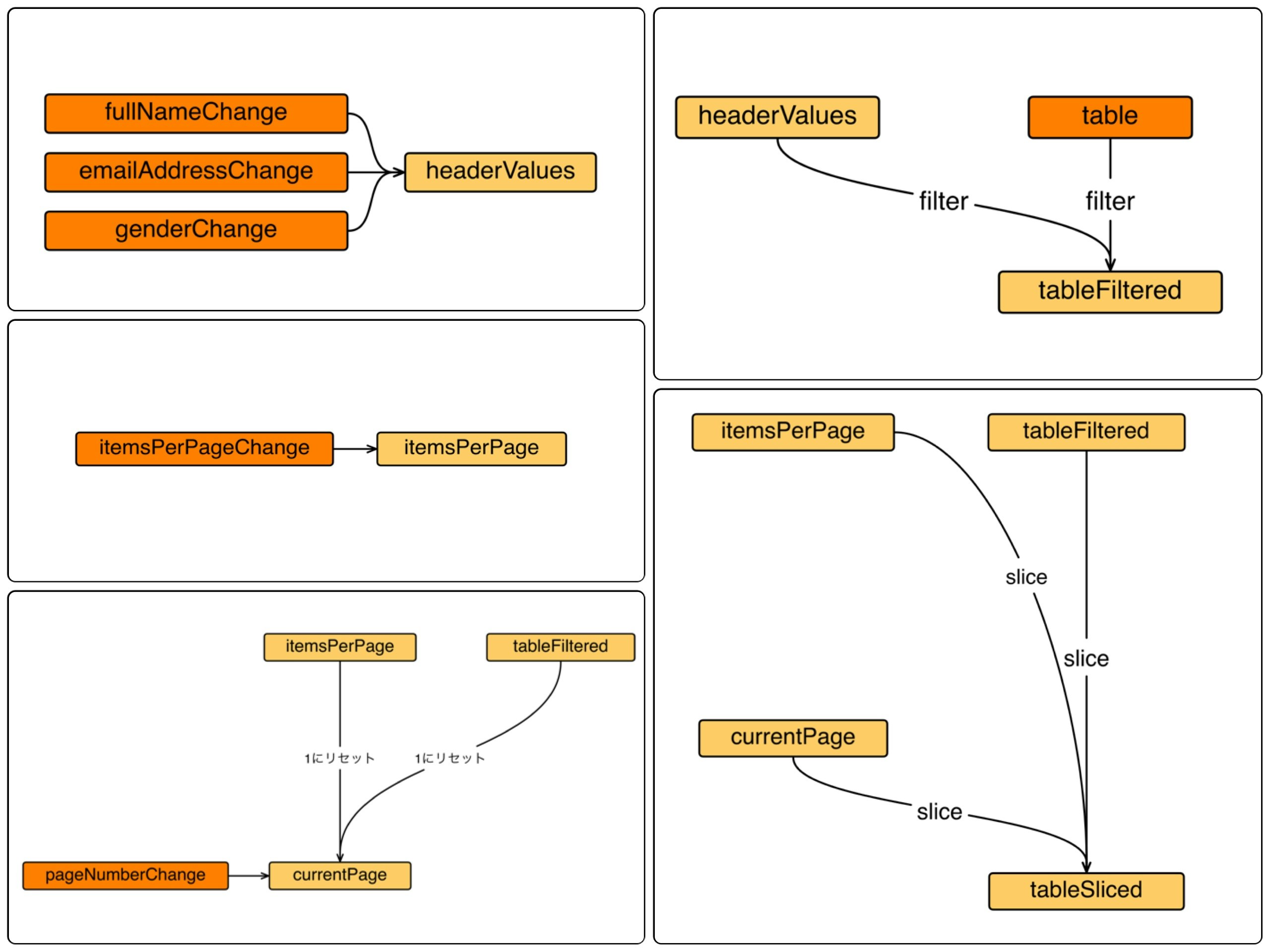
変数ごとに、それが直接依存する別の変数やイベントを一つのまとまりとして実装します。
重要なのは、非 RxJS 版実装では関係のある子孫をすべてたどる必要があったのに対して、RxJS 版では 2 段以上祖先を遡る必要はなく、直接の親(イベント・変数)のみを列挙すればよいということです。
これは、各データ(変数)を RxJS のObservableに替えることで実現できます。
例えば右上のtableFilteredの定義部分は Observable を使って以下のように書くことができます。
(Observable を普通の変数と区別するためによく末尾に$を付けます)。
const tableFiltered$ = combineLatest(table$, headerValues$).pipe(
map((table, headerValues) =>
table.filter((line) => filterFn(line, headerValues))
)
);
上のような構文の意味は次節以降で順を追って説明していきます。
Observable
RxJS を使う実装では、普通の変数の代わりにObservableというものを使ってデータを表します。これは、冒頭に説明した表計算ソフトの例におけるセルのような働きをするものです。
Observable は、普通の変数に
- 上流の変数の値(依存している値)が変わったときに、自身の値を更新する
- 自身の値が変わったときに
- 下流の変数に通知する
- あらかじめ登録した処理を行う(
subscribeというメソッドにより、Observable の値が変化したときに行う処理を登録できる。イベントに対するaddEventListenerと似たことができる)
などの機能が付け加えられたようなものです。
「値が変わったときに発火する変数」というイメージが個人的には分かりやすいと思っています。
Observable の作り方には
- source となる Observable をゼロから作る(
fromEventなど) - 他の Observable を合成または加工して作る(
combineLatest、mapなど)
という二つがあります。
【例 1】 fromEvent
fromEventを使うと、以下のように、ボタンをクリックすると発火する Observable を作ることができます。
発火時の処理alert('Hello, world!')を subscribe により登録しています。
例
<button id="hello">Hello</button>
hello$ = fromEvent(document.getElementById('hello'), 'click');
hello$.subscribe((_) => {
alert('Hello, world!');
});
テキストボックスの入力時に発火する Observable も同様です。
例
<input type="text" id="str" />
str$ = fromEvent(document.getElementById('str'), 'input').pipe(
(event) => event.target.value
);
str$.subscribe((str) => {
console.log('input: ', str);
});
【例 2】pipe
Observable はpipeメソッドを持ち、様々なオペレータを渡すことで Observable を加工することができます。
mapは頻繁に用いられるオペレータの一つです。
mapの働きを図にすると以下のようになります。
図の横軸は時刻で、上の Observable をオペレータで変換した結果が下の Observable になるという意味です。
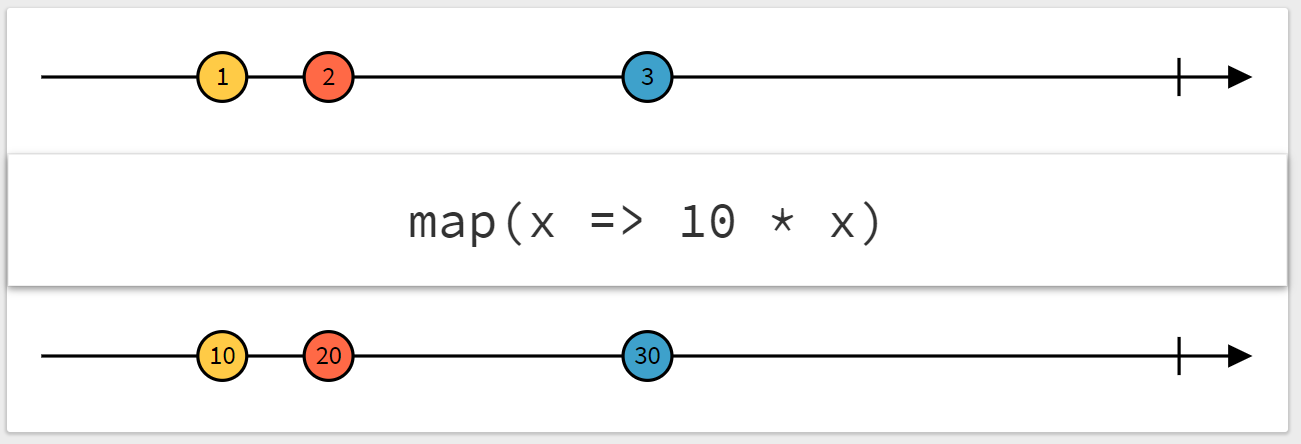
以下の例では、mapオペレーターにより、入力のアルファベット文字列を大文字に変換したものを出力する Observable を作っています。
alphabets$ = fromEvent(document.getElementById('alphabets'), 'input').pipe(
(event) => event.target.value
);
ALPHABETS$ = alphabets$.pipe(map((str) => str.toUpperCase()));
ALPHABETS$.subscribe((ALPHABETS) => {
console.log(ALPHABETS);
});
【例 3】merge
mergeという関数により複数の Observable を合流させることができます。
mergeはいくつかの Observable a$, b$, ... z$を受け取り、
そのいずれかの Observablex$が発火したときにその(最新の)値xを発火する Observable を作ります。
図にすると以下のようになります。
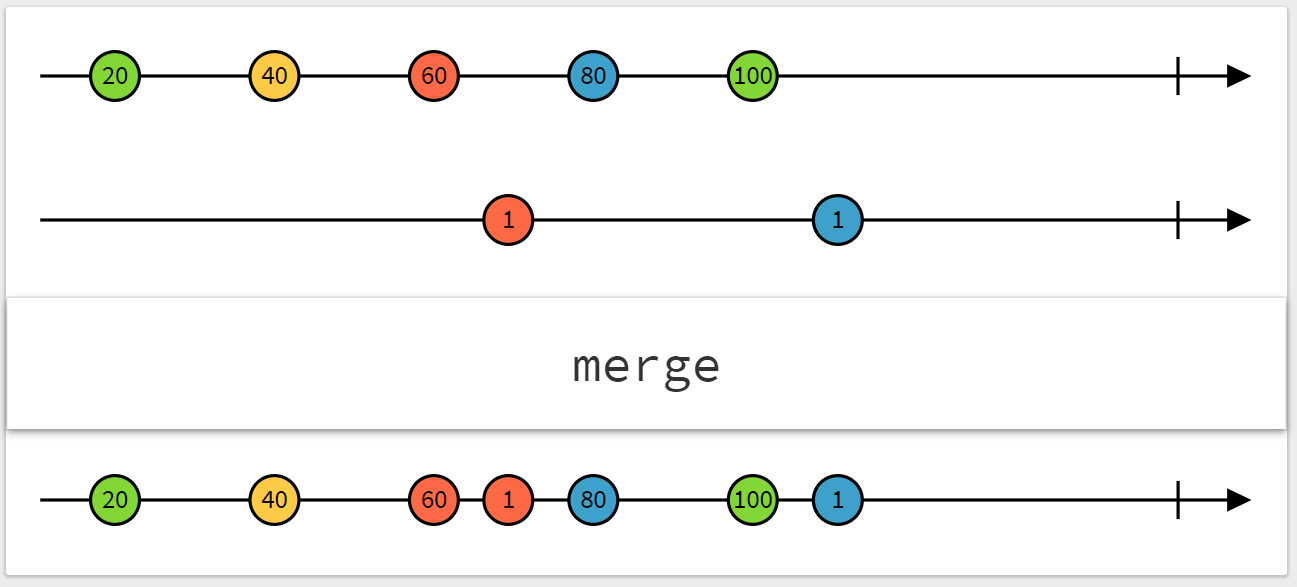
例
buttonA$ = fromEvent(document.getElementById('buttonA'), 'click');
buttonB$ = fromEvent(document.getElementById('buttonB'), 'click');
buttons$ = merge(buttonA$, buttonB$);
buttons$.subscribe(() => {
alert('buttonA or buttonB clicked!');
});
【例 4】combineLatest
combineLatestという関数により、複数の Observable の最新の値を組み合わせた Observable を作ることができます。
combineLatestは、0 個以上の Observable a$, b$, ... z$ を受け取り、
そのいずれかの Observable が発火したときに a$, b$, ... z$の最新の値からなるタプル [a, b, ..., z]を発火する Observable を作ります。
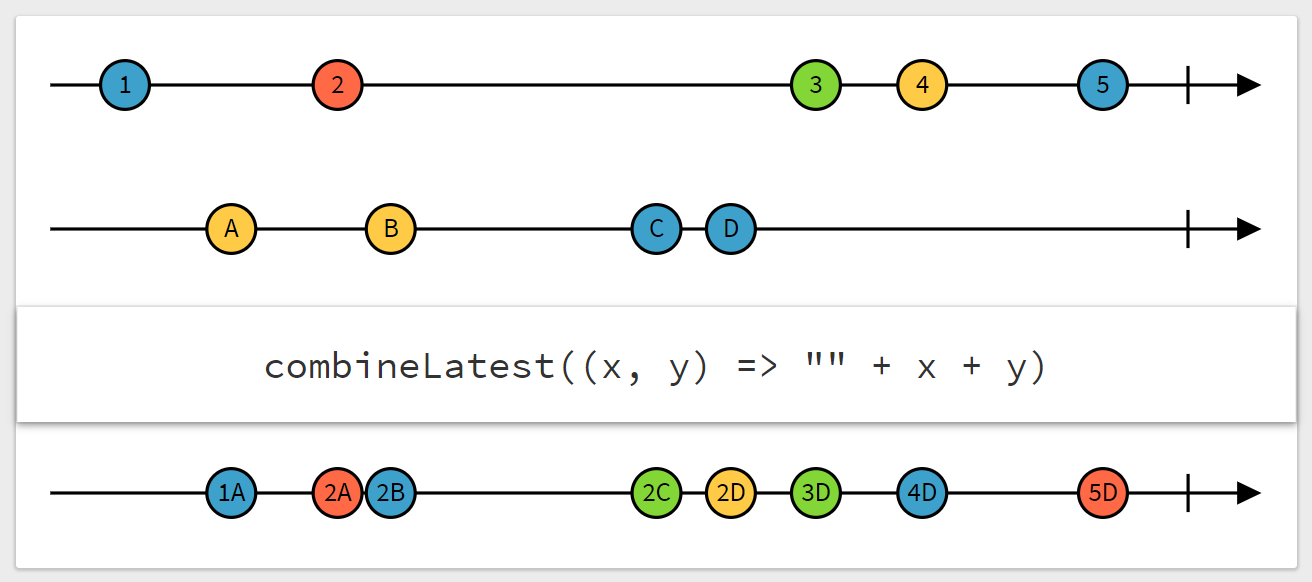
例
str1$ = fromEvent(document.getElementById('str1'), 'input').pipe(
(event) => event.target.value
);
str2$ = fromEvent(document.getElementById('str2'), 'input').pipe(
(event) => event.target.value
);
str12$ = combineLatest(str1$, str2$).pipe(map((str1, str2) => str1 + str2));
以上のメソッドを用いて DataTableApp の実装を改良していきます。
準備(RxJS の import)
RxJS は以下の手順で簡単に導入できます。
(1) インストール
npm install rxjs
(2) 使用するソースコードでインポート(ES6 モジュールが使える場合)
import { of } from 'rxjs';
import { map } from 'rxjs/operators';
あるいは以下のようにしてもよいです。
(1) index.html に以下の 1 行を追加
<script src="https://unpkg.com/rxjs/bundles/rxjs.umd.min.js"></script>
(2) JavaScript のソースコードの最初に必要なものを import する
const { fromEvent, combineLatest, merge } = rxjs;
const { map, startWith, debounceTime } = rxjs.operators;
実装
fullName 取得部分の非 RxJS 版の実装を再掲します。
let timerId;
document
.getElementById('full-name') // idが'full-name'の要素を指す
.addEventListener('input', (event) => {
clearTimeout(timerId); // 前回の予約をキャンセル
timerId = setTimeout(() => {
// 処理を予約し予約番号をtimerIdに控える
headerValues.fullName = event.target.value ?? '';
updateTableFiltered();
updateTableSliced();
printTable();
}, 100);
});
RxJS 版だと次のようになります。
const fullName$ = fromEvent(document.getElementById('full-name'), 'input').pipe(
map((event) => event.target.value ?? ''),
debounceTime(100),
startWith('')
);
pipeメソッドに渡したオペレーターにより、input イベントからfromEventで作った Observable を順番に加工しています。
map( event => (event.target.value ?? '')はeventオブジェクトからテキストボックス内の文字列を取り出しています。
debounceTime(100)は、元の Observable で 100 ミリ秒以内の間隔で連続している発火を最後の 1 回だけにまとめるオペレーターです。
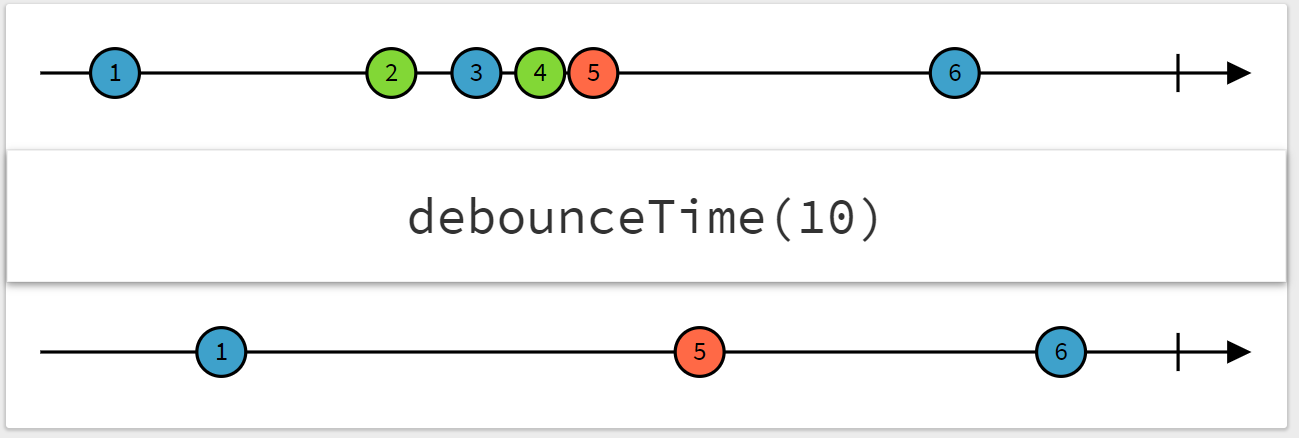
startWith('')は普通の変数における初期化の代わりのようなもので、input イベントの発火前に初期値''で 1 度発火するようにしています。
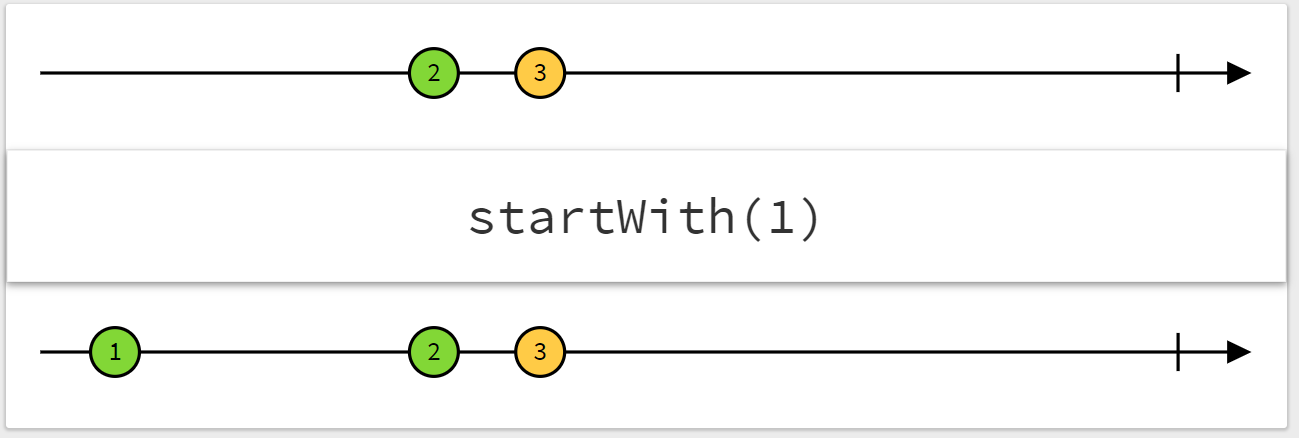
emailAddress$とgender$も同様に作り、
headerValues$を以下のように定義しておきます。
const headerValues$ = combineLatest(fullName$, emailAddress$, gender$).pipe(
map((fullName, emailAddress, gender) => ({
fullName: fullName,
emailAddress: emailAddress,
gender: gender,
}))
);
updateTableFiltered()やupdateTableSliced()に対応する処理は、
tableFiltered$やtableSliced$という Observable を作る際に行います。
tableFiltered$は以下のように作ります。
const tableFiltered$ = combineLatest(table$, headerValues$).pipe(
map((table, headerValues) =>
table.filter((line) => filterFn(line, headerValues))
)
);
テーブル全体を表す Observabletable$の発火する値を
テキストボックスの値に対応する ObservableheaderValues$によりフィルタする、
という処理の内容は非 RxJS 版と同じです。
itemsPerPage$はfullName$と同様です。
const itemsPerPage$ = fromEvent(
document.getElementById('items-per-page'),
'input'
).pipe(
map(
(event) => event.target.valueAsNumber ?? 50,
debounceTime(100),
startWith(50)
)
);
currentPage$は以下のようになります。
const currentPage$ = merge(
fromEvent(document.getElementById('current-page'), 'input').pipe(
map((event) => event.target.valueAsNumber ?? 1),
debounceTime(100)
),
itemsPerPage$.pipe(map((_) => 1)),
tableFiltered$.pipe(map((_) => 1))
).pipe(startWith(1));
fromEvent(*).pipe(**)の部分はほぼ同じですが、
総ページ数が変わったときに現在のページを 1 にリセットする処理のために
itemsPerPage$やtableFiltered$の発火時に1を発火するようにしています。
ちなみにmap(_ => 1)の部分はmapTo(1)というオペレータで書き換えることもできます(今回は道具をなるべく減らすためにあえて map を使いました)。
tableSliced$はtableFiltered$, itemsPerPage$, currentPage$の三つを組み合わせて作ります。
// tableの表示するページ部分
const tableSliced$ = combineLatest(
tableFiltered$,
itemsPerPage$,
currentPage$
).pipe(
map((tableFiltered, itemsPerPage, currentPage) =>
tableFiltered.slice(
itemsPerPage * (currentPage - 1),
itemsPerPage * currentPage
)
)
);
最後にtableSliced$の表示処理を記述します。
subscribeメソッドでtableSliced$発火時に関数printTableを呼んでいます。
// テーブルを表示
tableSliced$.subscribe((tableSliced) => {
printTable(tableSliced);
});
RxJS 版実装の主要な部分は以上です。
全体のソースコードと動くサンプルを以下に置いておきます。
RxJS 版実装の利点の分析
前節までで非 RxJS 版と RxJS 版の具体的な実装を説明しましたが、両者は質的に以下のような点で違いがあります。
- プログラミングスタイル
- [非 RxJS 版]イベントごとに必要な処理を命令的に記述する。
- [RxJS 版]データごとに、それがどうふるまうかを宣言的に記述する。
- データの加工
- [非 RxJS 版]間引き処理(
setTimeoutやclearTimeoutを使った部分)がとても読みづらいコードになっていた。 - [RxJS 版]時間変化する一連のデータを、パイプ処理&オペレータで簡単に加工できる。
- [非 RxJS 版]間引き処理(
- グローバル変数の書き換え
- [非 RxJS 版]コールバック関数の性質上、書き換え可能なグローバル変数を使うことは避けられない。値を書き換える処理がソースコード中に散らばり、変数の値が予測しづらくなりやすい。一方で、特定のイベント発火時に実行される処理は 1 か所にまとまっているため把握しやすい。
- [RxJS 版]Observable でデータを表すので、その値がどのように更新されるかは宣言&定義部分で決定される。そのため、値が予測しやすい。一方で、特定のイベント発火時に実行される処理は Observable ごとに記述されているため把握しづらくなりやすい。
- ロジックと表示処理の記述の分離
- [非 RxJS 版]イベント発火に対応する処理をコールバック関数内にすべて書く必要があるので、ロジックと表示処理は分離しづらい。表示処理が JavaScript ソースコード全体に散らばってしまうため、HTML ソースコードを変えたときの修正が大変。
- [RxJS 版]表示処理部分をまとめて記述しやすい。HTML ソースコード変更時の JavaScript ソースコードの修正が楽。
- 依存関係の記述
- [非 RxJS 版]
- イベント発火を root とする部分グラフ単位で記述する。
- イベント発火時に影響する変数全体を適切な更新順序も含めてすべて把握する必要がある。
- [RxJS 版]
- データ(変数)とその直接の親の関係のみ記述する。
- 親子関係のみ記述しておけば、変数の値は芋づる式に自動的に更新されるので、必ずしも依存関係の全体像(グラフ)を把握している必要はない。処理の依存関係・実行順序はほぼ気にしなくても自動的に解決される。(逆に、実行順序の制御を細かく行いたいときには却って難しくなりうる)
- [非 RxJS 版]
(非 RxJS 版の図)
(RxJS 版の図)
RxJS を利用したリアクティブプログラミングのメリット・デメリットがお分かりいただけたでしょうか。
おわりに
本記事は、RxJS によるリアクティブプログラミングの入り口部分の平易な説明を目指したものであるため、ごく一部の機能しか扱っていません。
より詳しい情報は下記リンクに貼っている公式ドキュメントを参照してください。
また、今回は比較のため一つの例における RxJS を使った実装の利点に絞って説明してみましたが、Observable は非同期処理を含むプログラムにおいて非常に強力な実装パターンであり、ほかにも様々な有効な使い方が可能です。ただ、非同期処理に関して結構なんでもできてしまう反面、適切な場所に用いないとオーバースペックになったり(本記事の例もやや当てはまりますが)、使い方を誤ると複雑で読みづらくなったり予想外のバグを生んだりすることもしやすい、扱いが難しいライブラリでもあると思います。扱い方を十分理解していたとしても普通に命令的に書いた方が分かりやすかったり、他の手段があるようなケースも少なくないと私は思っています。適度な使い方を心得るまでに慣れが必要だと私は思いますが、慣れれば抽象化の幅が広がりますし、他のリアクティビティを実現している技術についても相対的に理解することがしやすくなるので、選択肢の一つとして RxJS は知っておくと役に立つかなと私は思います(大体の他のリアクティブプログラミングライブラリは、用途に応じて RxJS から不要なものを削ぎ落して使いやすくしたような API になっていることが多い印象です)。
間違いや誤植、分かりにくい部分等があればコメントにて教えていただければ幸いです。
補足
- 本記事では状態管理の実装に生の JavaScript と RxJS をあえて使いましたが、例えば React を使えば React hooks などによりリアクティビティが実現できるため、今回のデータテーブルくらいのものであれば RxJS などのライブラリは使わずともシンプルに実装できます。とはいえ、React を使っていても Recoil のような外部ライブラリを使ってリアクティブな状態管理を実装した方がよい場合もあります。
- RxJS の Observable を使ったプログラムでは、実は"glitch"と呼ばれる現象が発生することがあります。これによるバグが発生するケースが存在しますが、残念ながら"glitch"は RxJS の仕様であるため、プログラマーが工夫して避けるしかありません。ほとんどのケースでは顕在化しませんが、本格的に RxJS を使用する場合には理解しておく必要があります。
- RxJS の Observable には、"hot"なものと"cold"なものがあります。本記事では触れませんでしたがそれぞれ動作が異なるため注意が必要です。場合によっては cold Observable を hot 変換した方がよいときがあります。
おまけ
RxJS には cold/hot Observable の違いや、説明は省きますが "glitch" と呼ばれる現象など、いくつか余計な扱いづらさを生んでいる要素があります。これらが気に入らなかったため、glitch の発生しない RxJS のように使うことができるライブラリ「SyncFlow」を以前自作しました。
現状ドキュメントをまったく整備できていませんが、もし興味のある方はソースコードを覗いてみてください。私は自作ウェブアプリの状態管理にほぼ毎回このライブラリを採用しています。
リンク (最終確認:2021/05/25)
-
RxJS
- RxJS の公式ドキュメント
-
RxJS Marbles
- RxJS のオペレータの動作を視覚的に学べるサイト
-
RxJS Github
- RxJS のソースコード
-
mockadoo
- CSV ダミーデータの生成
-
Material Design Lite
- テキストボックスのデザインに使ったライブラリ