はじめに
以前、ログギングの収集や保管についていろいろと記事を載せてきました。
上記記事では、アプリケーションのログについては今まであまり触れてこず、あっさりな感じだったので今回はAzure利用者向けのアプリケーション監視にスポットを当てて触れていこうと思います。ここでは、アプリケーションをAzureプラットフォームに構成する際に、「何を監視すればよいのか」と「どのように実装できるのか」に焦点を当てて考えていきます。
一般的なCPUやメモリ、SNMPTrap監視などのインフラの監視は本記事に含んでいません。
【前提】モノリスとマイクロサービス
Azure上にアプリケーションを構築する際、モノリスとマイクロサービスという2パターンの設計があります。その上で、アプリケーションの監視における観点も変わってきます。それを踏まえたうえで本記事の続きを読むことをお勧めします。
- モノリス:一つの物理的なサーバー上に仮想化やプロセスを分けることで構成されるシステム構成のこと。インフラやネットワークは基本的に共有することとなる。
- マイクロサービス:アプリケーションを小さなサービス群に分割したシステム構成のこと。各サービスのインフラやネットワークも独立して存在する構成をとれる。
以下記事がマイクロサービスの解説としてとてもわかりやすかったです。
マイクロサービスをもう少し深く理解したい方は以下Udemyの講座がおすすめです。
アプリケーションにおけるログの種類
アプリケーションを監視する上で、私は以下ログの監視ができれば十分である考えています。
(データベースの監視はまた今度書きます)
■障害の検知
■障害の解析
分散トレーシングはリリース時のEtoEテストにおいてのみ使えればよいという考え方もありますが、Azureにおいては簡単に実現できるのでピックアップしています。では、ここからひとつづつ見ていきましょう。
HealthEndpointの監視
HealthEndpointとは、アプリケーションの正常性を伝える重要な指標です。WEBアプリケーション開発において最も重要な監視はこのHealthEndpointの監視であると私は信じています。
実装方法と詳細
いかにこのHealthEndpointが重要であるかと構成パターンについては、Microsoftが公式のドキュメントでしっかりと解説した記事を作成してくれています。以下記事は、これからAzureでWebアプリケーションと監視の設計する上で必読と考えてください。
上記ドキュメントを読み進めていくと、Azureで完結する場合は以下サービスを構成することになるかと思います。
- TrafficManager:HTTPステータスを利用した外部視点での監視
- AzureMonitor(ApplicationInsights):開発者向けのサービス内部のより詳細な監視
HTTPリクエストとレスポンスの監視
WEBアプリケーションを運用している環境であれば、HTTPステータスコードは先ほどのHealthEndpointの監視とは別に取得しておくことを私はお勧めします。できれば、リクエスト数やリクエスト時間も集計をして記録する仕組みがあると便利です。
■ WEBアプリケーションの監視に必要な項目
- HTTPステータスコード
- リクエスト数
- リクエスト時間
なぜHTTPリクエストとレスポンスの監視が必要か
この問いに対しては「エンドユーザー目線でのシステム監視が最も重要」だからです。SLOとしてレイテンシなどを指標として挙げているチームであれば理解しやすいかと思います。WEBアプリケーションにおいて、ユーザー視点でシステムを見た際に最も注目する点は、そのWEBアプリケーションの応答にかかった時間や応答の内容ではないでしょうか。極論を言えば、メモリ使用率が90%を超えていても、WEBアプリケーションがステータスコード200を応答していれば、緊急での対応は必要ないことが大半かと思います。一方で、逆のパターンは直ちに対応が必要になることは必須でしょう。
実装方法
こちらについては、構成によって変わってきますが多くは以下のパターンでの構成で取得することになると思います。
- 仮想マシンにインストールされたWEBコンポーネント(Apatcheなど)のログをロギングで取得(WebAppsの場合は「ログの記録」を有効化)
- LoadBalancerやApplicationGWなどの応答を診断設定で取得する
基本的には、上記はどちらも実施するようにしましょう。それぞれ、確認できる粒度が変わってくるので見方が少しづつ違ってくるはずです。
パイプラインの監視
マイクロサービスを構成することが近年一般的になってきました。一方で、モノリス構成でもCI/CDパイプラインを組んでリリースしているユーザーもあるかもしれません。つまり、どのような状況においても、パイプラインの監視は極めて重要になってきます。ここでは、Azureを使用したパイプライン構成(特にここではPipelines)における監視についてピックアップして触れていきます。
基本的な考え方は、他のパイプラインの構成につながる部分もあるかもしれませんので、Azure DevOpsを使用していない方にも参考になる部分はあるかと思います。
なぜパイプラインの監視をするのか
基本的に安定したアプリケーションを運用しているチームにおける障害発生はこのデプロイ時に発生します。つまり、デプロイに関する情報を取得することで直接的な原因はわからないかもしませんが、デプロイが原因になったかどうかは分かるはずです。ここでのパイプラインの監視は本番またはテスト環境への「デプロイ」を監視するということになります。
必要な情報と収集方法
デプロイを監視するにあたって最低限必要な情報は以下なります。
- デプロイの開始日時と終了日時
- 実施されたデプロイの内容
- デプロイの実行ユーザー
収集方法は極めて簡単です。というかAzure DevOpsを利用しているのであれば特に何もしなくてよいです。確認方法や確認できる項目については、以下Docsをご覧ください。
アプリケーションのロギング監視
モノリスで構築されたアプリケーションであれば、ローカルディスクへテキストファイルでログを出力するかと思います。マイクロサービスであれば、診断設定に乗せてログを送信することもできるはずです。ログの内容は、アプリケーションの設計や開発段階で各アプリケーションに沿った内容のログが出力されることでしょう。ここではそう言ったログをどうやって集約していくかについて触れていきます。
テキストログの収集
仮想マシンまたは物理サーバー上にテキストファイルで出力されたファイルを取得するには、AzureMonitorAgentを使用しましょう。物理サーバーならAzureArcを導入することで、仮想マシンと同様にログの収集を行うことが可能です。実は過去に何度もブログに乗せた構成イメージですが、構成イメージはこんな感じです。
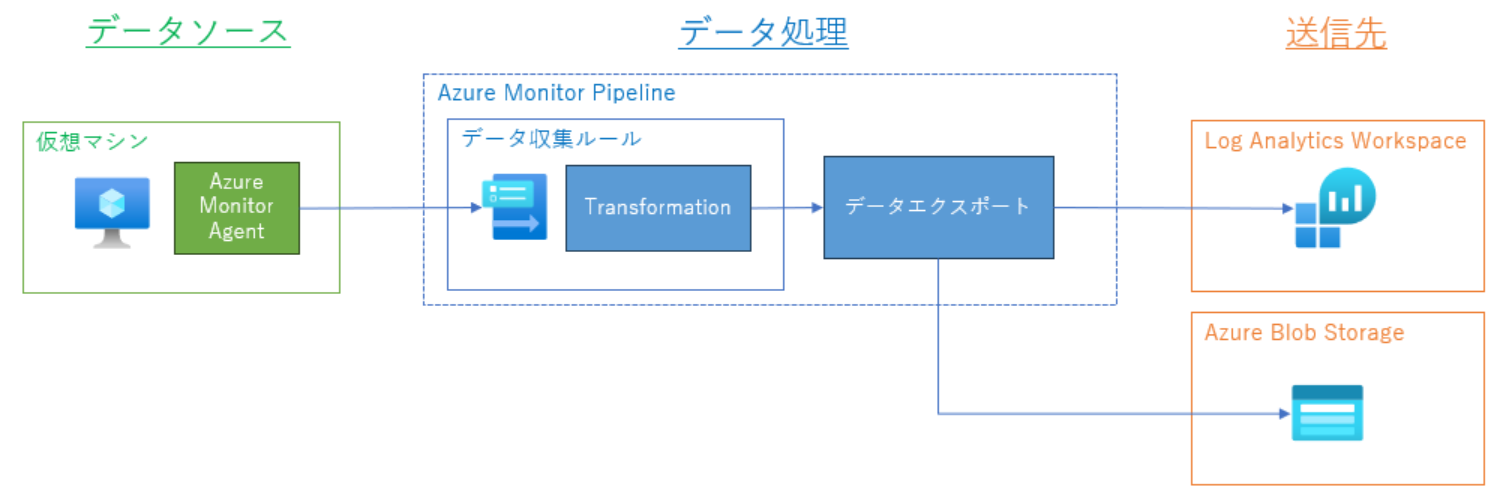
テキストログの収集については、上図の構成こそがベストプラクティスだと信じています。簡単に解説しておくと流れはこんな感じです。
- 物理サーバーにはAzureArcを適用しておきます(以降、仮想マシンと同じ)
- 仮想マシンへAzureMonitorAgentを構成し、カスタムテキストログ収集という機能で収集します
- TransformKQLを使用してテキストログを構造化し、LogAnalyticsWorkSpaceへ送ります
- 同時にデータエクスポート機能で監査用にAzureBlobStorageへ転送します
ここでの構成として重要な点は以下2点です。
- テキストログは構造化して保管すること
- 不変ストレージにも保管すること
監視で使用するテキストログは基本的にいつでも分析できるようにしておく必要があります。そのため、原則として構造化したデータを保管して何時でも確認できるようにしておきましょう。
不変ストレージに保管する理由としては、誤操作やセキュリティの観点から必要であるのと長期で保管した場合にLogAnalyticsWorkspaceでは料金が高額になってしまう可能性があるためです。
PaaSリソースのログ収集
Azureでアプリケーションを構成するときのPaaSで代表的なAppsServiceについてここではフォーカスして考えていきます。AppServiceにおける運用では「ログ記録」を有効にすることで簡単に様々な必要なログを取得し、診断設定を使用してLogAnalyticsWorkspaceへ送信できます。
確認できるログの内容と実装方法については以下Docsをご参照ください。
分散トレーシング
マイクロサービスの開発において、ここまで上げてきた監視では不十分なケースが多くあると思います。その際によく利用を考えるのが分散トレーシングという手法です。こちらは、簡単に言えば、システムに入ってくるリクエストに識別IDを付与して、そのリクエストが各サービス内でどのように過ごしたかをトレースする方法です。特にEtoEテストにおいて使用するケースが多いかと思います。
実装方法
実はプラットフォームでAzureを選択している場合において、ApplicationInsightsを使用することで非常に簡単に実現が可能です。この点については、以下記事が非常によくまとまっており参考になります。
また、MSのApplicationInsightsのDocsもしっかりとみておきましょう。
ApplicationInsightsは実に奥が深いのでまた別記事で深く記載していこうと思います。今回はこちらの参照先で許してください。