先日の技術書典6で「お台場計算尺」というサークル名でいくつか本を頒布した。その際、10分ごとに売れた部数を記録した。そのデータを時系列解析してみる。
まずはデータ。「お台場計算尺」は何百部も売れるようなすごいサークルではない(やっとこ100部程度)。「12:00」は 12:00 までの10分間に売れた数だが、開始直前に見に来てくれた人(サークル参加の人)が結局買ってくれたので、11:00 の開始時刻までに1冊売れたことにした。
11:00,1
11:10,0
11:20,0
11:30,0
11:40,2
11:50,4
12:00,14
12:10,5
12:20,6
12:30,4
12:40,2
12:50,4
13:00,2
13:10,5
13:20,4
13:30,8
13:40,6
13:50,4
14:00,2
14:10,1
14:20,1
14:30,3
14:40,0
14:50,8
15:00,0
15:10,5
15:20,1
15:30,5
15:40,1
15:50,1
16:00,3
16:10,2
16:20,2
16:30,0
16:40,0
16:50,2
17:00,0
データの様子
で、Rに読み込んで解析。まずはいつもの呪文。
> library(tidyverse); # 呪文だから唱えてるけど、今回は不要
> library(ggfortify); # 同上、snippet で自動的に書き込む
> library(latticeExtra); # 移動平均 simpleSmoothTs を使う
> theme_set(theme_bw(base_family = "HiraKakuProN-W3")); # plot で日本語
> dat <- read.csv("total.csv", header=F);
> dat[,1] <- (1:length(dat[,1]) - 1)/6; # hour 単位
> colnames(dat) <- c("hour", "売り上げ");
読み込んだら何はなくともまずプロット。書典では tidyverse をバリバリ使う本を出したが、正直めんどうなので、古式ゆかしく楽ちんプロット。12時ちょうど(開会後1時間)のところに外れ値っぽいのがある。全体的には、上がってから下がっていく感じ(山が一つ)っぽく見えるような気がする。
> total <- dat[,2];
> time <- dat[,1];
> plot(time, total, ylab="10分ごとの売上げ数");
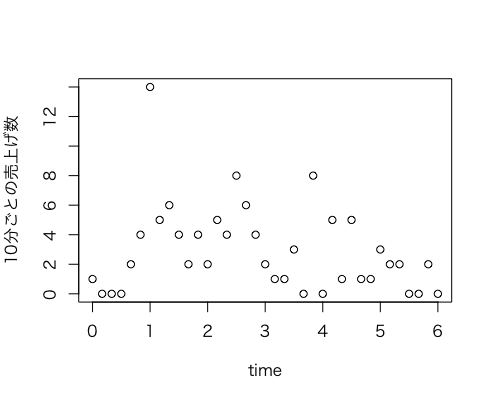
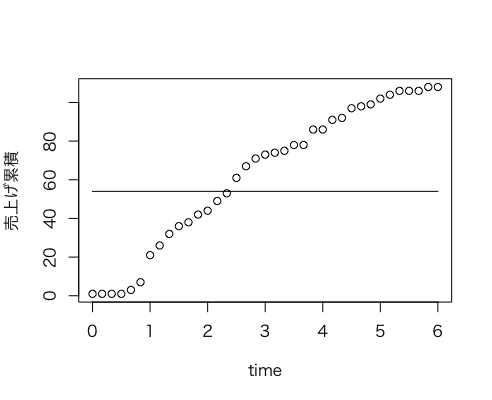
で、累積(開始から各時間までに売れた総数)でもプロット。外れ値のおかげか、全体の売上げの半分くらいは入場が有料だった時間帯(< 2h)に売れている。11:00〜17:00 の最初の1/3である。横線が売り上げ数の1/2のライン。
plot(time, cumsum(total), ylab="売上げ累積");
lines(c(0,6), c(sum(total)/2, sum(total)/2));
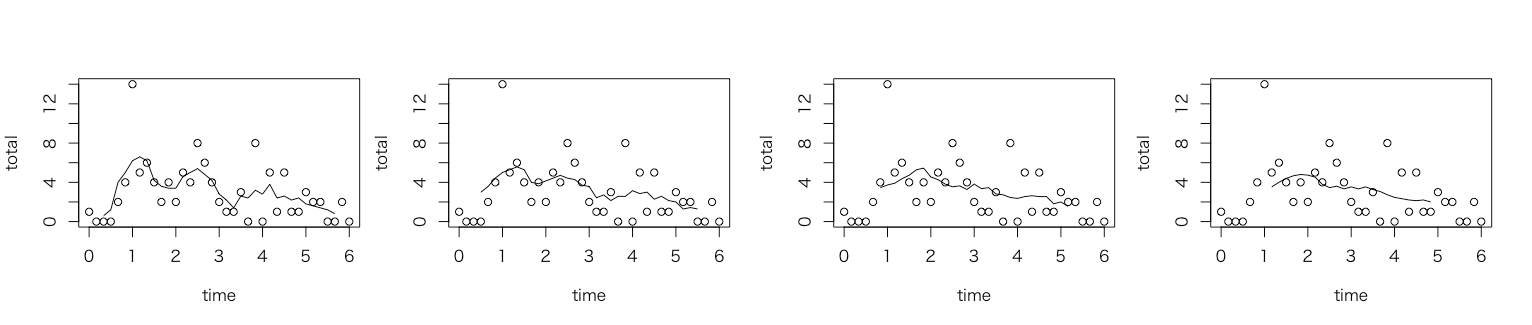
10分ごとの売り上げから、細かい変動を除いてみる(移動平均)。ウィンドウを広くしていくと、プロファイルは上がって下がる感じ(山が一つ)のような気がしないでもない。まぁ先入観かもしれない。なお、始めも終わりも裾を引かない。となると、変動に当てはめるのは二次曲線とかかなぁ、とこの段階では想像する。
x <- simpleSmoothTs(total, width= 5); plot(time, total); lines(time, x);
x <- simpleSmoothTs(total, width= 7); plot(time, total); lines(time, x);
x <- simpleSmoothTs(total, width= 11); plot(time, total); lines(time, x);
x <- simpleSmoothTs(total, width= 15); plot(time, total); lines(time, x);
直線や曲線の当てはめ
まずは手探り
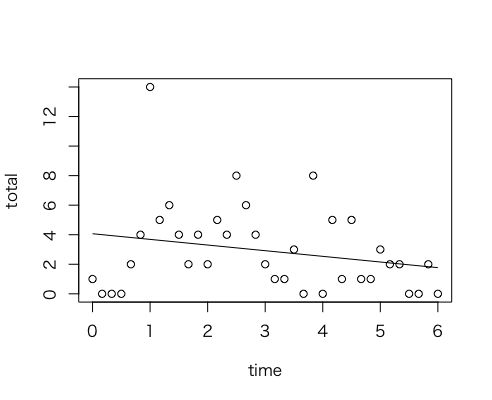
ここまでも手探りだったけど、それじゃぁモデリングしてみましょうか、ということで、まずはとりあえず直線を当てはめてみる。まぁ、はまってるような、はまってないような...
mod <- lm(total ~ time);
plot(time, total);lines(time, predict(mod));
次に二次曲線を当てはめてみる。二次曲線は非線形だから nls で当てはめる。頂点の場所が分かりやすいように、曲線の式は $y = a(x - b)^2 + c$ にする。上に凸なので $a < 0$、$b$ はピークの時刻、$c$ はピークの高さになる。プロットから $b = 2.5$、$c = 6$ くらいになるかな、などと予想しながらやってみる。すると、まぁ直線より少しはいいような...でもまだ、なんとも言えないかなぁ。
mod <- nls(total ~ a*(time - b)^2 + c, start = c(a = -1, b = 2, c = 0));
plot(time, total);lines(time, predict(mod));
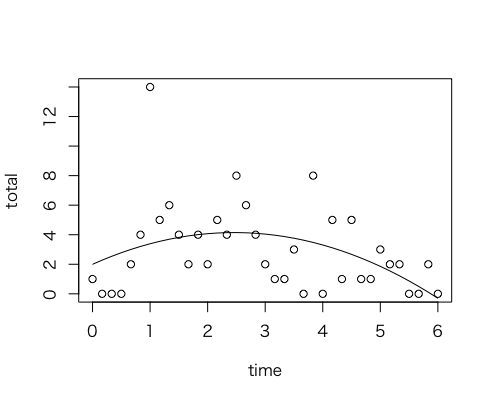
この二次曲線モデル自体を見てみると、p値も小さいし、収束も早い。ピークは 2.46h あたりで、10分間に4.1冊の割合というのが売上げ速度の(期待値の)最大値のようだ。
> summary(mod);
Formula: total ~ a * (time - b)^2 + c
Parameters:
Estimate Std. Error t value Pr(>|t|)
a -0.3548 0.1602 -2.215 0.0335 *
b 2.4608 0.4336 5.675 2.28e-06 ***
c 4.1456 0.6606 6.276 3.78e-07 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.756 on 34 degrees of freedom
Number of iterations to convergence: 3
Achieved convergence tolerance: 9.315e-10
もっと高次だったらどうかな?ということで四次曲線を当てはめてみる。すると、当てはまりは悪くないし、また「上がる > プラトー > 下がる」というプロファイルはまぁ、売っていた時の感覚からも納得できる。最後の方はヒマだったし。
> mod <- nls(total ~ a*(time - b)^4 + c, start = c(a = -0.5, b = 2, c = 0));
> plot(time, total);lines(time, predict(mod));
> summary(mod);
Formula: total ~ a * (time - b)^4 + c
Parameters:
Estimate Std. Error t value Pr(>|t|)
a -0.04681 0.01944 -2.408 0.0216 *
b 2.84146 0.23405 12.141 6.52e-14 ***
c 3.78541 0.56799 6.665 1.20e-07 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.768 on 34 degrees of freedom
Number of iterations to convergence: 5
Achieved convergence tolerance: 9.558e-08
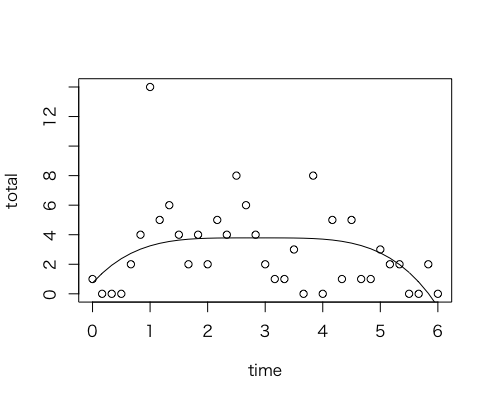
最適モデル
二次より四次がいいなら、もっと高いといいのかもしれない。次数には最適値があるのかもしれない。というわけで探してみる。AIC を使って探すと六次式が最適(AIC 極小)になる。プロットを見ると、2h の前にピークがあってその後プラトー、そして最後に下がる。より感覚的に納得できる感じ。p値は今一つだが、まぁこの辺りがとりあえずのゴールかな、と思う。もっと売り上げ数の多いサークルのデータで見てみたいところ。
> t <- time; # 長い変数名がイヤだから
> mod <- lm(total ~ 1 + t + I(t^2) + I(t^4) + I(t^6) + I(t^8) + I(t^10));
> mopt <- step(mod);
> plot(time, total);lines(time, predict(mopt));
> summary(mopt);
Call:
lm(formula = total ~ t + I(t^2) + I(t^4) + I(t^6))
Residuals:
Min 1Q Median 3Q Max
-3.1733 -1.4567 -0.5842 0.8173 9.5552
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.4237932 1.7057428 -0.248 0.8054
t 7.4616040 2.9388969 2.539 0.0162 *
I(t^2) -2.6696918 1.1822114 -2.258 0.0309 *
I(t^4) 0.0777012 0.0448673 1.732 0.0929 .
I(t^6) -0.0010574 0.0007093 -1.491 0.1458
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.666 on 32 degrees of freedom
Multiple R-squared: 0.2726, Adjusted R-squared: 0.1817
F-statistic: 2.998 on 4 and 32 DF, p-value: 0.03292
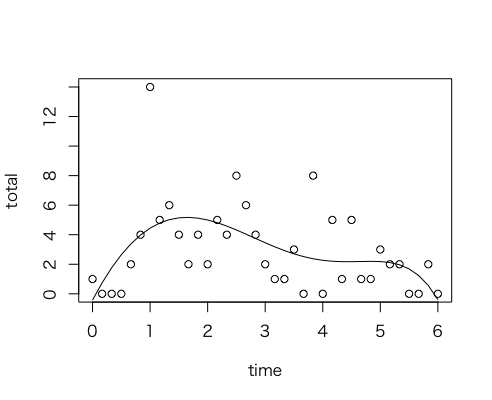
有名な時系列解析法ではどうか
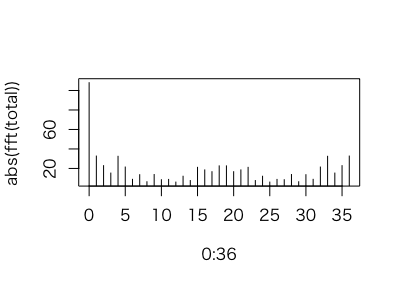
まぁもういいかなと思いつつも、一応時系列解析的なこともやってみる。自己回帰とFFT。自己回帰は最適モデルの次数が低く、元データに見るべき周期性はないことを示している。FFT も周期成分(左端のパワー = sum(total) 以外の成分)には目立ったものはない。
> ar(total, order=16)
Call:
ar(x = total, order.max = 16)
Coefficients:
1 2 3
0.2367 0.3650 -0.2760
Order selected 3 sigma^2 estimated as 7.463
> plot(0:36, abs(fft(total)), type="h");
結論
技術書典6における、6時間の開催時間内の売り上げの推移は、多項式でモデリングするとスタートダッシュとプラトーのバイモーダルな感じになる。直線的あるいは上がって下がるだけ(山が一つ)と言った感じではない。また時間内には意味のある周期性(振動)はなさそう。
もっとマシな解析のためには
時間の単位が「分」なのは、それが人にとって感覚的に理解/把握しやすい長さだからだろう。その細かさのデータがあれば、もうちょっと分かりやすい解析ができるように思う。具体的には、かんたん後払いで400件(毎分1件)以上くらい売れていればよかったのかな、と思う(そのくらいあれば、10分間あたりの平均が10件以上になって、分布も見えたかもしれない)。今回は29件だった。理想は遠い。計算尺本は売れないのか(売るけど)。
なお、手でとった今回の記録をあとで「かんたん後払い」のデータと照らし合わせたところ、書き漏らしがあることが分かった。悲しい。昔はこんなミスはしなかった(と今は思うんだが)。年はとりたくないものだ...