Prophetを使った時系列分析
初めてProphetを使ってみましたので、コードを公開します。検索しながら触ってみましたが、日本語の記事は非常に少なかったので、この記事が誰かの参考になれば幸いです。
この記事で分かること
- Prophetを実際のデータに適用した動くコード
Prophetとは
Prophetはmeta社発の時系列分析ライブラリです。
以下、公式HPの説明をgoogle翻訳したもの。
Prophet は、非線形傾向が年、週、日の季節性と休日の影響に適合する加算モデルに基づいて時系列データを予測する手順です。これは、強い季節的影響がある時系列や複数の季節の履歴データに最適に機能します。 Prophet はデータの欠落や傾向の変化に対して堅牢であり、通常は外れ値を適切に処理します。
引用元:https://facebook.github.io/prophet/
Rとpythonで動くようで、今回はpythonで動かしました。
動作環境
MacOS Sonoma 14.4.1
python3.10.14
VisualStudioCode
分析するデータ
コンペサイトであるSignate(Kaggleの日本版)のデータで実施しました。コンペは
SOTA challengeの"アップル 引越し需要予測"です。
データの読み込み
まずはデータの読み込みです。本コンペは学習用データtrain.csvとテスト用データtest.csvの2つのみで、非常にシンプルで分かりやすかったです。
datetimeカラムに時系列が入っていたので、読み込むと同時にインデックスに指定。合わせて、parse_dates=Trueにすることで、datetime形式として読み込めます。
一般的に、時系列データを扱う際にはよくやる操作ですので流れで実施しましたが、実はProphetでは必要なく、あとでもとに戻しています。。
#ライブラリのインポート
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
#ファイルの読み込み
train=pd.read_csv('train.csv',index_col='datetime',parse_dates=True)
test=pd.read_csv('test.csv',index_col='datetime',parse_dates=True)
欠損値とデータ型の確認
ひとまず、データの情報を確認しました。欠損値もなく、データ型も問題なさそうです。特に加工しなくても学習できる状態になっており、初心者に優しい仕様でした。
#データの情報を確認
train.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2101 entries, 2010-07-01 to 2016-03-31
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 y 2101 non-null int64
1 client 2101 non-null int64
2 close 2101 non-null int64
3 price_am 2101 non-null int64
4 price_pm 2101 non-null int64
dtypes: int64(5)
memory usage: 98.5 KB
Prophetで読み込める形式に変換
Prophetでは、時系列カラムを'ds'、予測したいデータカラムを'y'とする必要があります。最初に時系列カラムをインデックス化してしまったので、一度リセットしたうえで、カラム名を変更します。
#ライブラリのインポート
from prophet import Prophet
#読み込める形式に変換
##インデックスをリセット
df_pro=train.reset_index()
##カラム名をDSへ変更
df_pro.rename(columns={'datetime': 'ds'}, inplace=True)
学習&予測
準備ができたので早速予測していきます。まずはインスタンスを作成。
#インスタンス化
m=Prophet()
必須ではありませんが、ここで日本の休日をデータに追加しておきます。'JP'の部分を変えると他の国の休日データに簡単に変更できます。
#カントリーホリデーを追加
m.add_country_holidays(country_name='JP')
これもなくても予測はできますが、説明変数は下記コードで追加できます。データフレームにもともと含まれていますが、下記のように追加してあげないと考慮されません。
#説明変数を追加(このままではyだけで予測してしまうので)
m.add_regressor('client')
m.add_regressor('close')
m.add_regressor('price_am')
m.add_regressor('price_pm')
そして学習させます。scikit-learnの流れを汲んでいるので、シンプルで分かりやすいです。
#学習
m.fit(df_pro)
未来を日付を予測するために、予め未来の日時を含んだデータフレームを作成しておく必要があります。このデータフレームには、前述のところで説明変数を追加した場合は、こちらのデータフレームにも同様のカラムを追加しておく必要があります。今回は、testデータが未来の日時と説明変数のデータフレームでしたので、そのまま使います。
未来のデータは作らなくても、過去のデータに対してのみ、当てはめすることはできます。さくっと動かしたいだけなら、ここはスキップしてもOKです。
#予測する未来の日数を作成
future=test.reset_index()
##カラム名をDSへ変更
future.rename(columns={'datetime': 'ds'}, inplace=True)
最後にpredictで予測します。
#予測
forecast = m.predict(future)
可視化
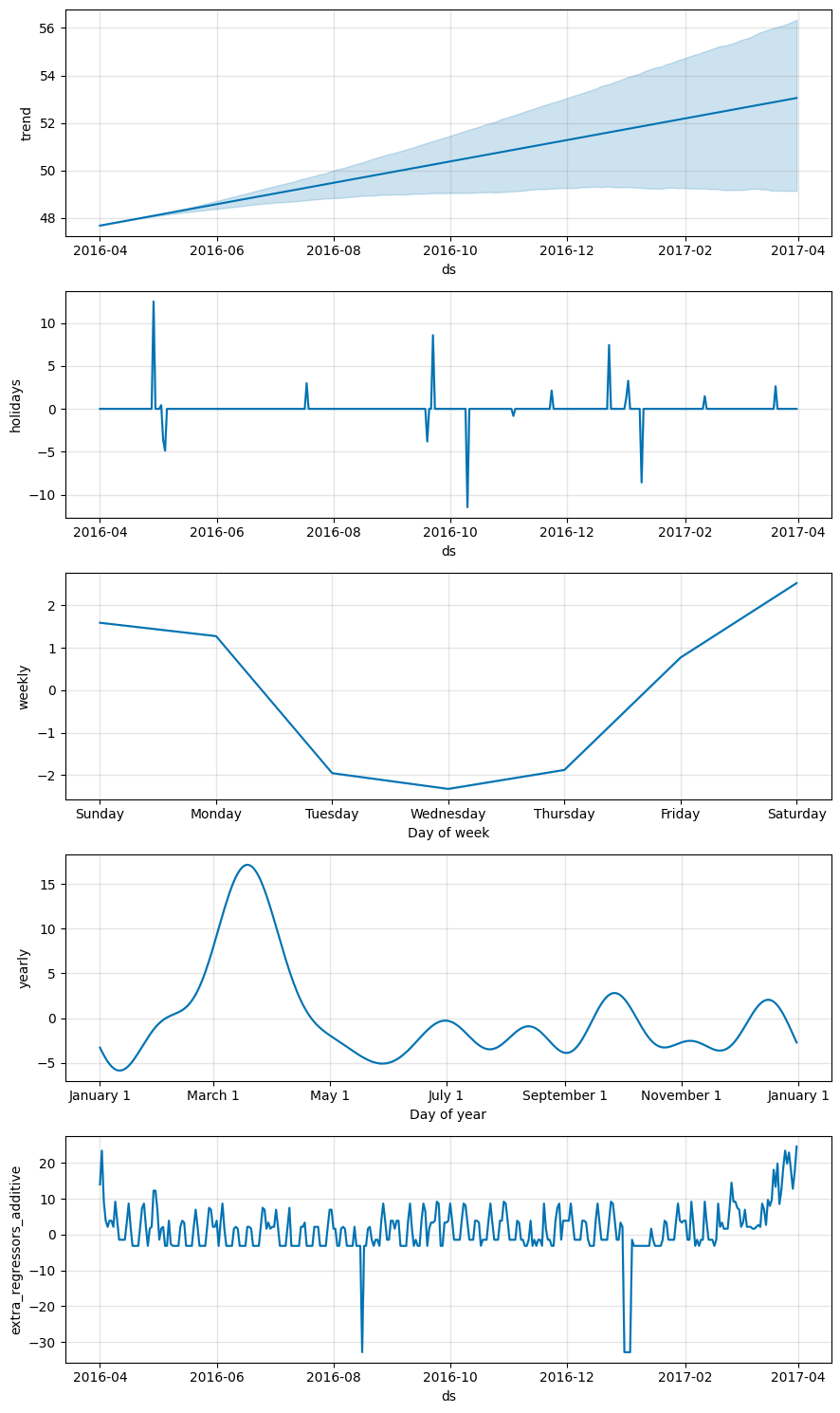
予測したデータを可視化します。
fig1 = m.plot(forecast)
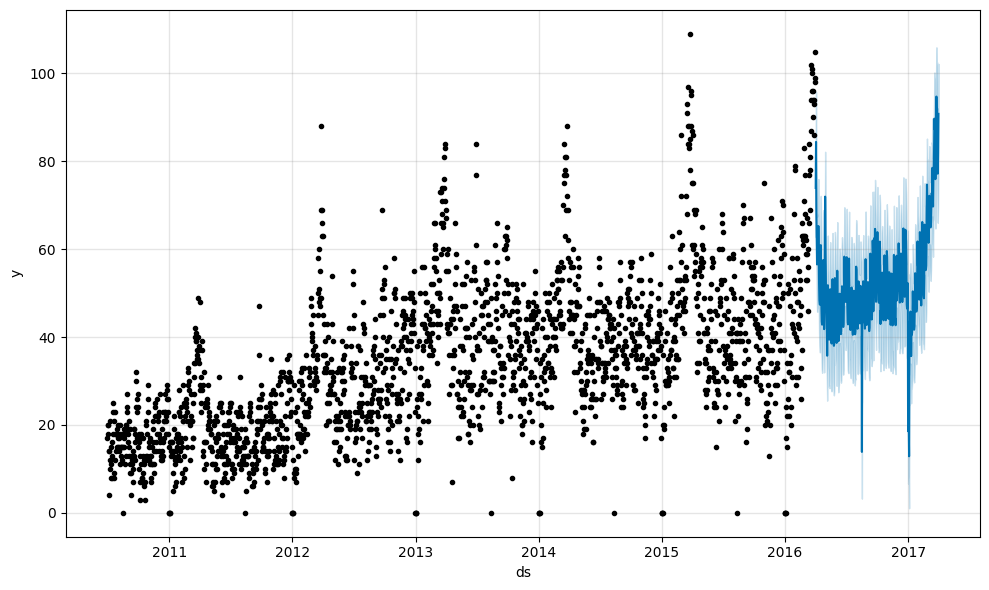
fig2 = m.plot_components(forecast)
終わりに
Prophetを使った時系列予測を実際のコンペデータを用いて実施してみました。Scikit-learnと使い方は類似しており、非常にわかりやすく、人気の理由がわかります。
このあと、特徴量エンジニアリングやoptunaを使用したハイパーパラメータチューニングなど行ってスコアの向上を目指していますので、また共有したいと思います。
以上