はじめに
本記事は以下の続きです。筆者がどうしてもRAGを使ってみたく続けます。
今回やること
ずばり「フィギュアスケートの複雑なルールを正確に答えてくれるチャットボットに拡張しよう」です。フィギュアスケートのルールブックをRAGシステム化し、その情報を基にチャットボットが回答できるようにします。
実装
テキストドキュメントからRetrieverを作成する
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_google_vertexai import VertexAIEmbeddings
class RAGService:
def __init__(self, text_path, chunk_size=100, overlap=10, top_k=5):
print("RAG Service Standby")
loader = TextLoader(text_path, encoding="utf-8")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=overlap)
docs = text_splitter.split_documents(documents)
embedding_model = VertexAIEmbeddings(model_name="text-embedding-004")
vector_store = Chroma.from_documents(
documents=docs,
embedding=embedding_model,
persist_directory="./chroma_store"
)
vector_store.persist()
self.retriever = vector_store.as_retriever(search_kwargs={"k": top_k})
def get_retriever(self):
return self.retriever
解説
-
TextLoader
指定されたテキストファイルを読み込みます。 -
CharacterTextSplitter(chunk_size=100, chunk_overlap=10)
読み込んだ文書を「チャンク(小さなかたまり)」に分割します。chunk_sizeは1かたまり当たりの文字数、chunk_overlapはチャンク間の重なりの文字数を示します。以下記事が分かりやすいと思います。
- VertexAIEmbeddings(model_name="text-embedding-005")
vector_store = Chroma.from_documents
分割された各チャンクをベクトルに変換し、Chromaベクトルストア で効率的な類似検索ができるように格納します。text-embedding-005はGoogleが提供するembeddingモデルの中で、最新のものになります。
セッションIDごとに会話履歴の取得
# セッションIDごとの会話履歴の取得
def get_session_history(self, session_id: str) -> BaseChatMessageHistory:
if session_id not in self.store:
self.store[session_id] = CustomFirestoreChatMessageHistory(
user_id=session_id,
db=self.db
)
return self.store[session_id]
解説
- コンストラクタにキャッシュ(store)を定義、さらにif文で条件分岐しておくことで、同じユーザーIDで複数回呼ばれても、CustomFirestoreChatMessageHistory(Firebaseの履歴を管理するクラス)のインスタンスを使いまわせるようにしています。
- langchainにはFirebase対応のクラスが定義されていますが、定義したいデータベースの構造が異なるため、ここでは抽象クラス(必要なメソッドとかはこれだけど、自分で実装してね、というクラス)であるBaseChatMessageHistoryを継承してCustomFirestoreChatMessageHistoryクラスを定義しています。以下がそのクラスです。
from datetime import datetime
from typing import List, Optional, Sequence
from google.cloud import firestore
from langchain.schema import BaseMessage, HumanMessage, AIMessage
from langchain_core.chat_history import BaseChatMessageHistory
class CustomFirestoreChatMessageHistory(BaseChatMessageHistory):
"""
Firestore の "users/{id}/messages" 構造で
会話履歴を保存・取得し、さらに上限件数を制限するカスタム実装。
"""
def __init__(
self,
id,
db,
limit = 100
):
self.id = id
self.db = db
self.limit = limit
# Firestore上のメッセージをロードして保持
self.messages: List[BaseMessage] = self.load_messages()
def load_messages(self) -> List[BaseMessage]:
"""Firestore から最新の self.limit 件の会話履歴を取得し、BaseMessage リストにして返す。"""
docs = (
self.db.collection("users")
.document(self.id)
.collection("messages")
.order_by("timestamp", direction=firestore.Query.DESCENDING)
.limit(self.limit) # 最新 limit 件だけ取得
.stream()
)
raw_history = [doc.to_dict() for doc in docs]
# Firestoreは DESC で取っているので逆順(古→新)に並べ替える
raw_history.reverse()
messages: List[BaseMessage] = []
for item in raw_history:
role = item.get("role", "")
text = item.get("text", "")
if role == "user":
messages.append(HumanMessage(content=text))
elif role == "model":
messages.append(AIMessage(content=text))
else:
messages.append(AIMessage(content=text))
return messages
def add_user_message(self, message: str) -> None:
"""ユーザーからの発話を追加"""
user_msg = HumanMessage(content=message)
self.add_messages([user_msg])
def add_ai_message(self, message: str) -> None:
"""AI(モデル)からの発話を追加"""
ai_msg = AIMessage(content=message)
self.add_messages([ai_msg])
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
"""
複数メッセージを一括で追加。
新規メッセージのFirestore書き込み後、上限を超えていれば古いメッセージを削除する。
"""
for msg in messages:
self.messages.append(msg)
# Firestore書き込み
if isinstance(msg, HumanMessage):
self.write_chat_history("user", msg.content)
elif isinstance(msg, AIMessage):
self.write_chat_history("model", msg.content)
else:
self.write_chat_history("system", msg.content)
# Firestore & メモリ上の履歴を上限件数以内に収める
self.enforce_chat_history_limit()
def write_chat_history(self, role: str, text: str):
"""Firestore に単一メッセージを {role, text, timestamp} 形式で保存。"""
doc_ref = (
self.db.collection("users")
.document(self.id)
.collection("messages")
.document()
)
doc_ref.set(
{
"role": role,
"text": text,
"timestamp": datetime.utcnow(),
}
)
def enforce_chat_history_limit(self):
"""
Firestore の会話履歴を最大 self.limit 件に制限し、
古いメッセージを削除する。
同時にメモリ上(self.messages)からも超過分を削除する。
"""
# (1)Firestore 側の古いメッセージを削除
messages_ref = (
self.db.collection("users")
.document(self.id)
.collection("messages")
)
docs = (
messages_ref.order_by("timestamp", direction=firestore.Query.ASCENDING)
.stream()
)
all_docs = list(docs)
total_count = len(all_docs)
if total_count > self.limit:
to_delete_count = total_count - self.limit
old_docs = all_docs[:to_delete_count] # 古い順に to_delete_count 件
for doc in old_docs:
doc.reference.delete()
# (2)メモリ上の messages も最後の self.limit 件だけ残して削除
# (最新が末尾にあるので、必要に応じて len(self.messages)とlimitでスライス)
if len(self.messages) > self.limit:
self.messages = self.messages[-self.limit:]
def clear(self) -> None:
"""
必要に応じて、メモリ上の履歴や Firestore 上の履歴を削除する処理を記述。
"""
# 例: メモリ上の履歴をクリア
self.messages.clear()
# Firestore からも削除したい場合は以下など:
messages_ref = (
self.db.collection("users")
.document(self.id)
.collection("messages")
)
for doc in messages_ref.stream():
doc.reference.delete()
解説
-
init
本クラスのコンストラクタ。
ユーザID(id)、Firestore クライアント(db)、履歴上限件数(limit)を受け取り、クラス内で保持。load_messages() を呼び出して、Firestore 上にすでにある最新メッセージを取得し、self.messages にセットしています。「初期化のタイミングで外部データ(Firestore)をロードしてメモリ上に準備する」ことで、以後の操作がスムーズになっています。 -
load_messages
limit 件だけ降順(新しい順)に取り出し、逆順に並べて古い順 → 新しい順に整列。role に応じて HumanMessage / AIMessage に振り分け、BaseMessage リストを返しています。 -
add_user_message
ユーザ発話(文字列)を HumanMessage に包み、add_messages に渡します。ラッパメソッドであり、「ユーザからの発話」と「モデルからの発話」を分けて扱いやすくなっています。 -
add_ai_message
モデル(AI)の発話を AIMessage として包み、add_messages に渡します。 -
add_messages
HumanMessage や AIMessage など複数の BaseMessage を一括追加し、Firestore へ書き込むためのメインメソッドです。受け取った各メッセージを self.messages に追加したあと、write_chat_history を呼び出して role と text を Firestore の新規ドキュメントに保存します。さらに全メッセージを処理し終わった段階で enforce_chat_history_limit を呼び、メッセージ総数が limit を超過していれば古いものを削除します。これにより常に最新 100 件のみが保持されます。 -
write_chat_history
Firestore の users/{id}/messages に新規ドキュメントを生成し、role, text, timestamp を書き込みます。 -
enforce_chat_history_limit
Firestore 上のメッセージを最大 self.limit 件に収めるためのメソッドです。
まず Firestore の users/{id}/messages を timestamp 昇順に取得し、総数が limit を超える場合は古い順に余剰分だけ削除します。メモリ上の self.messages に関しても末尾(新しいほう)から limit 件だけ残して古い要素を破棄します。これにより、データベースとアプリの両方でメッセージ数が同期され、最新履歴を一定件数だけ保持する状態を保ちます。
langchainで会話履歴ありのRAGチャットチェーンを作成する
def get_llm(self):
llm = ChatVertexAI(
model="gemini-2.0-flash",
temperature=0,
max_tokens=None,
max_retries=6,
stop=None,
project=self.project_id,
location=self.location,
)
return llm
def rag_generate(self, user_id: str, message: str):
# Vertex AI chat model (PaLM/Gemini)
llm = self.get_llm()
# システムプロンプト
system_prompt = ("""
あなたは可愛らしくかつ賢い、質疑応答タスクのアシスタント、名前は「ちいくん」です。
以下の抽出した文脈を用いて質問に答えてください。
答えがわからない場合は、「わからない」と答えてください。最大3文で簡潔に答えてください。
"{context}"
"""
)
prompt_template = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
# RAG Chain 構築
basic_qa_chain = create_stuff_documents_chain(
llm=llm,
prompt=prompt_template,
)
retriever = self.rag.get_retriever()
rag_chain = create_retrieval_chain(retriever, basic_qa_chain)
history = self.get_session_history(user_id)
# Runnable chain を RunnableWithMessageHistory でラップ
runnable_with_history = RunnableWithMessageHistory(
runnable=rag_chain,
get_session_history=self.get_session_history, # FirestoreChatMessageHistory を返す関数
input_messages_key="input",
history_messages_key="history",
output_messages_key="answer",
)
# RAGチェーン実行 (対話履歴をFirestoreに保存)
response = runnable_with_history.invoke(
{"input": message},
{"configurable": {"session_id": user_id}}, # ここでは user_id を session_id として使う
)
# AI応答を履歴に追加 (Firestoreにも書き込み)
answer_msssage = response.get("answer", [])
history.add_user_message(message)
history.add_ai_message(answer_msssage)
return {"answer": answer_msssage}
解説
-
prompt_template = ChatPromptTemplate.from_messages
LangChain の Stuff チェーン。RAG の retrieved context を {context} に詰め込み、LLM に問い合わせる処理を表します。 -
rag_chain = create_retrieval_chain(retriever, basic_qa_chain)
PDF などをベースにした Retriever を呼び出し、basic_qa_chain と結合。この組み合わせで「ユーザ発話 → 関連文書を検索 → LLM に回答させる」流れが完成。 -
runnable_with_history = RunnableWithMessageHistory
LangChain の履歴付きチェーン。過去の対話履歴(Firestore)を自動注入できるようにする。input → 今回の発話、chat_history → 過去履歴、answer → 出力。
実行結果
RAG投入前
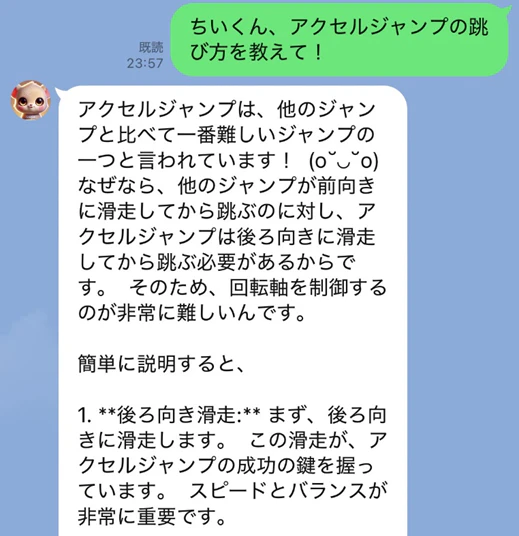
RAG導入後
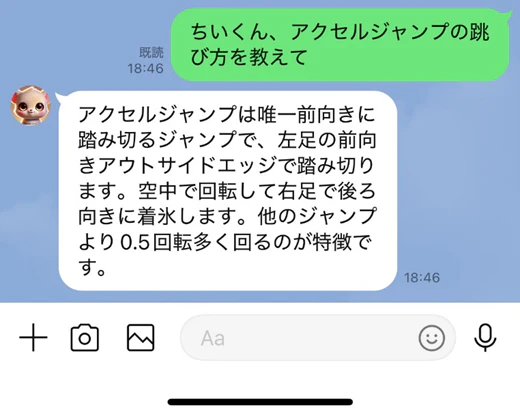
アクセルジャンプは前向き踏切のジャンプなので正しく情報が読み取れていることが分かります。
クラウド環境へのデプロイ時に躓いたこと
- CPU不足
ChromaDBにはスレッド機能があるらしく、今回のアプリケーションで利用すると自動的に複数スレッド立ち上がるようになっていました。デプロイ時にCPU不足を言われたので、2つのCPUを構成するようにしました。 - メモリ不足
おそらくRAGシステムの容量が大きすぎたのか、メモリ不足エラーが出てしました。Cloud Runのデフォルトのメモリ容量は512MiBですが、ここでは2Gi指定でデプロイしました。
※ CPUの数およびメモリ容量を指定するオプションは、「--memory」「--cpu」
例:gcloud run deploy line-rag-bot --source . --cpu 2 --memory 2Gi
参考
- ChatVertexAI
- LangChainでつくるRAGチャットボット
- CharacterTextSplitter