(この記事は「Keras Advent Calendar 2018」の17日目です)
fukuoka.ex代表のpiacereです
ご覧いただいて、ありがとうございます ![]()
前回に引き続き、データサイエンスプラットフォーム「Esuna」で、「タイタニック号乗客の生存予測(以降、タイタニック予測と省略)」を解いていく過程を解説したいと思います
はじめに
このコラムは、以下の三部構成になっており、うち「第一部:データに前処理を施す」は、本コラムとは別の前編コラムで解説済みで、第二部以降が、本コラムとなります
第一部:データに前処理を施す
第二部:機械学習(Keras)モデル構築とテスト
第三部:テスト結果をKaggleに提出する
第一部:データに前処理を施す ※別コラム
タイタニック予測のCSVファイルは、そのままでは、機械学習/ディープラーニングに掛けられないので、前処理が必要です
KaggleからCSVファイルを入手するところから、3種類の前処理をEsunaのUI上からポチポチと施す解説は、下記の前編コラムをご覧ください ![]()
|> Elixir+KerasでKaggleのタイタニック予測を解いてみた①
~UIでデータサイエンス、前処理/MLプラットフォーム「Esuna」~
第二部:機械学習(Keras)モデル構築とテスト
前処理で、機械学習/ディープラーニングに掛けられる状態になりましたので、モデルを構築し、学習とテストをさせていきます
「Mechine Learning」メニューから前処理CSVロード
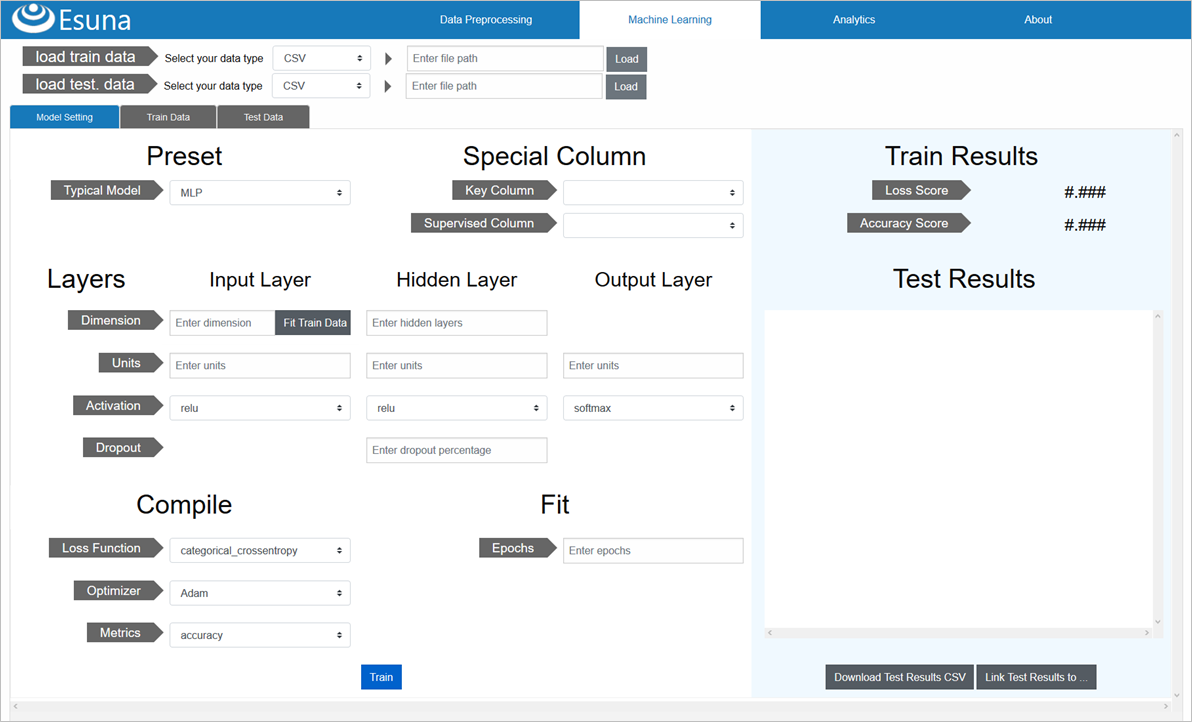
画面上部の「Machine Learning」メニューをクリックして、機械学習モデル構築/呼出を行っていきます
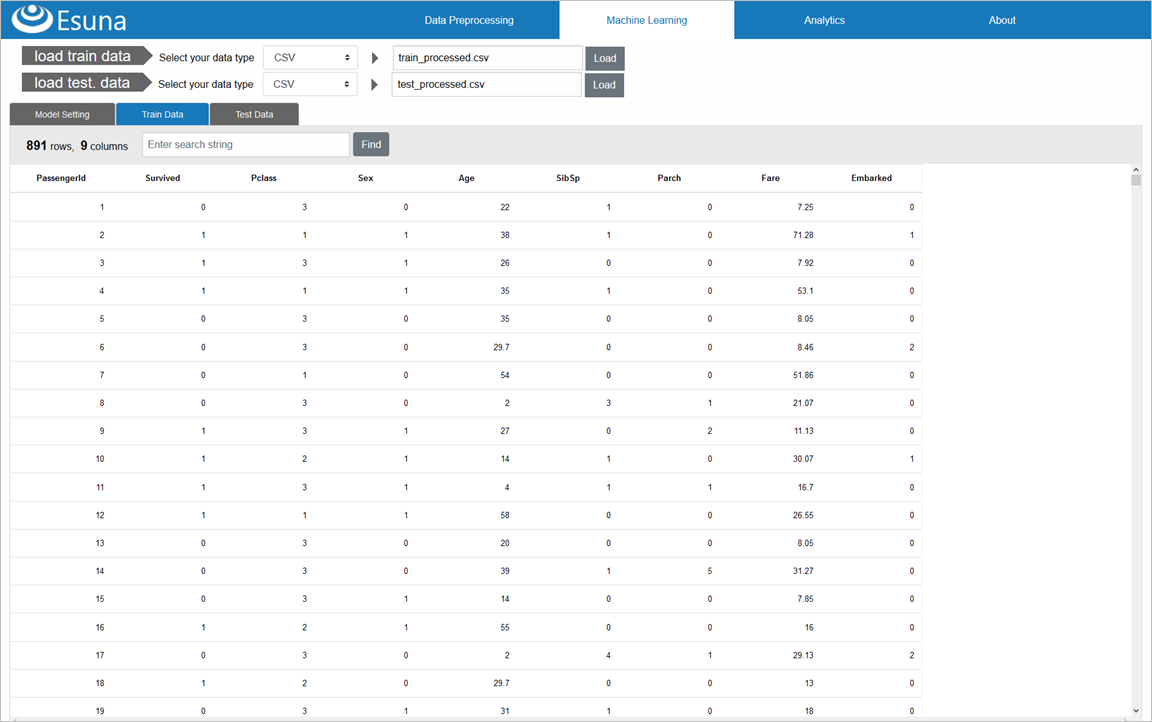
まずは、前処理を施した、訓練データ(train_processed.csv)と、テストデータ(test_processed.csv)をロードします
「load train data」「load test data」共に、「CSV」を選択した後、「Load」ボタンをクリックして、前処理済みのtrain_processed.csv、test_processed.csvを選択し、ロードします
ロード後、「Train Data」タブをクリックすると、訓練データが表示されます
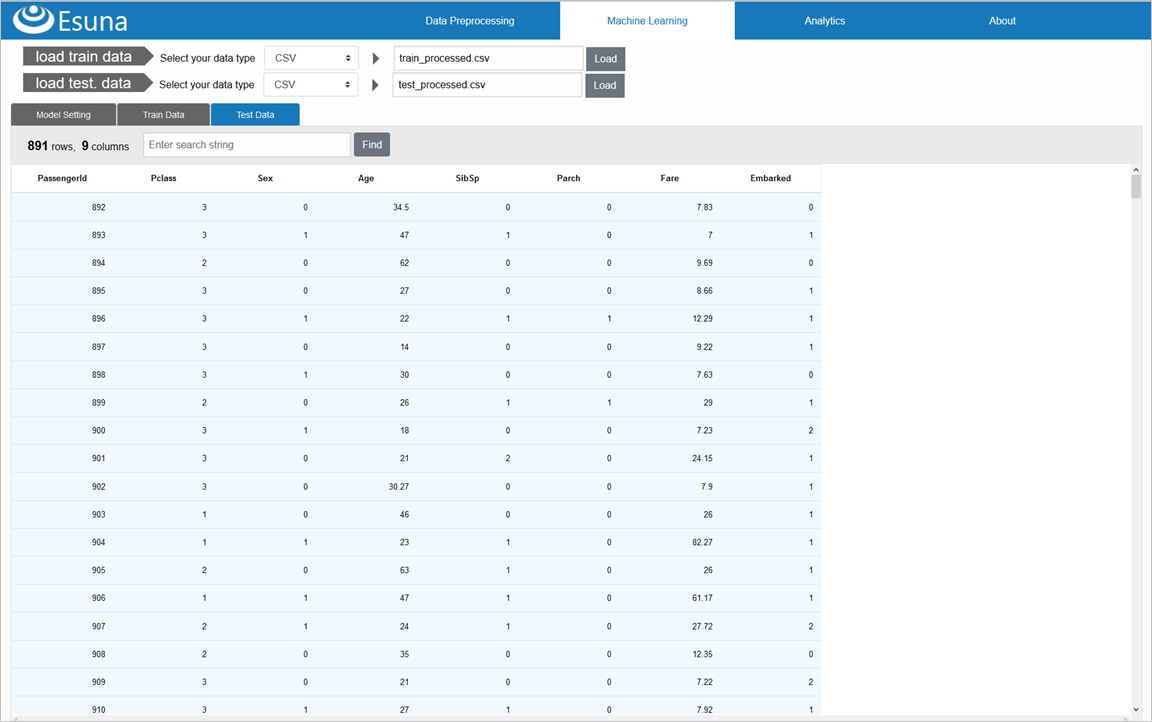
「Test Data」タブをクリックすると、テストデータが表示されます
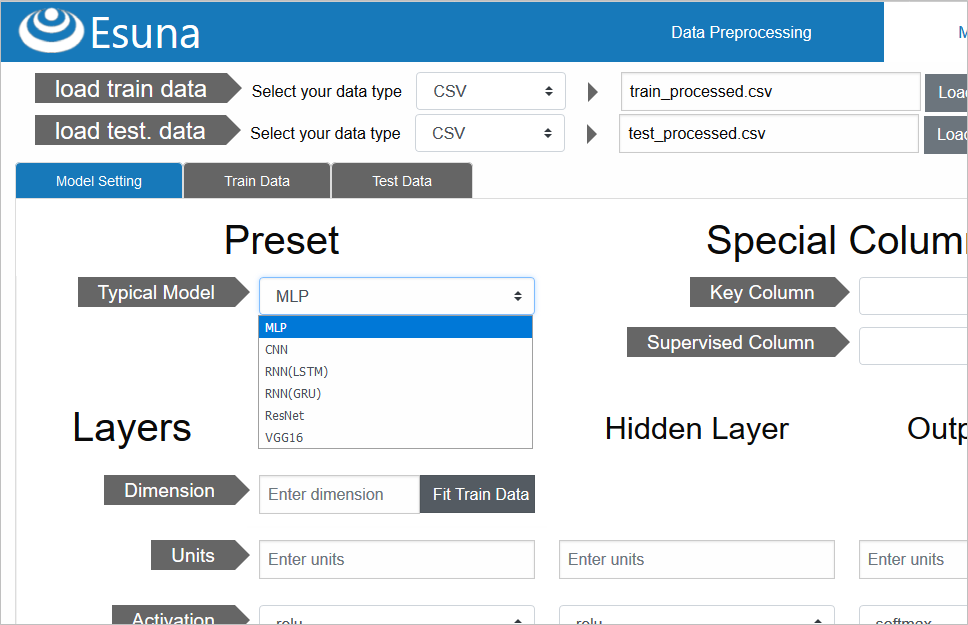
代表的モデルを選択
「Model Setting」タブに戻り、モデル構築に入ります
タイタニック予測では、複数の特徴量から「分類」、つまり、0(死亡)か1(生存)を予測するモデル構築をするため、代表的モデルが選択できる「Typical Model」から、「MLP」=「多層パーセプトロン(MuLtilayer Perceptron)」を選択します
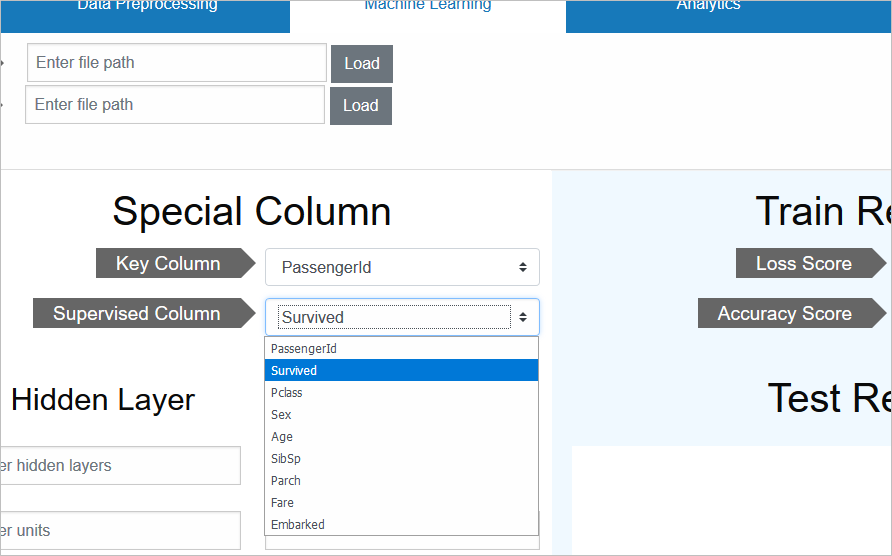
キーと正解データの指定
訓練データ/テストデータ共に、乗客をユニークに識別するID「PassengerId」が残っていますが、これは前述通り、予測データには必要なので、キーとして指定します
この指定を行うと、テストデータのPassengerIdが、予測データには残り、訓練データ/テストデータの両方から、特徴量としては削除されます
それと、正解データとして、生存/死亡を表す正解データ「Survived」を指定します
この指定を行うと、訓練データの特徴量としては削除されますが、モデル学習時の正解率(≒Accracy)の検証には、正解データとして利用されます
モデルの各種設定
あとは、モデルの層の構成や、損失関数、オプティマイザ、評価用メトリクス、学習施行回数といった各種設定を行っていきます
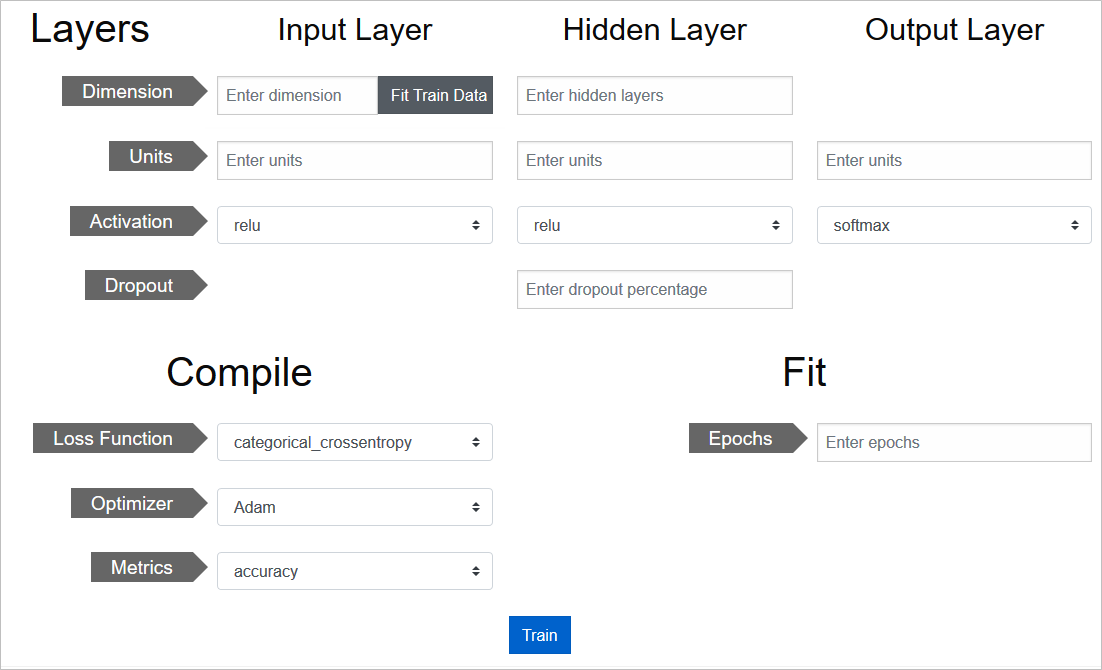
基本的に、Kerasで指定可能なパラメータばかりなので、細かい説明は割愛して、設定値の画面キャプチャを張って説明代わりとします
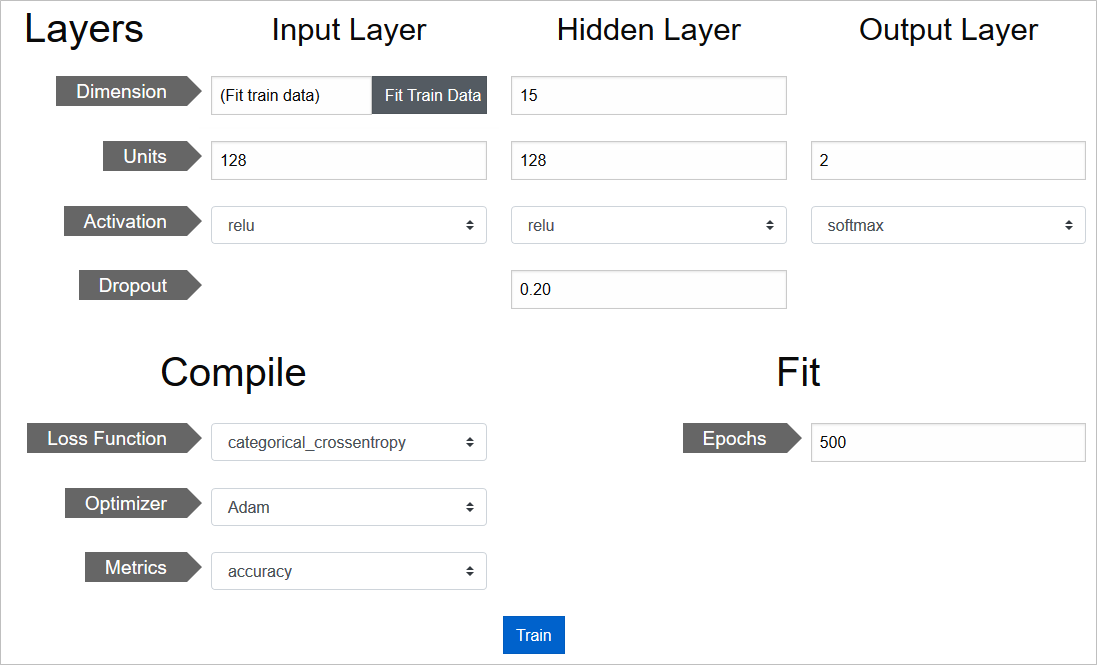
設定自体は、プルダウンの選択や、パラメータ数字の手入力で済みます
たとえば、活性化関数は、こんな種類が選択可能です
損失関数は、これらが使えます
オプティマイザはこんな感じです
Esunaから生成されたKerasコード
モデルの各種設定を行った後、「Train」をクリックすると、EsunaからKerasコードが生成され、このコードをPython経由で起動し、モデルの学習とテストが実行されます
Esunaから生成されたKerasコードは、以下のようなコードとなります
import pandas as pd
train= pd.read_csv( "train_processed.csv" )
test= pd.read_csv( "test_processed.csv" )
supervised_column = "Survived"
supervised = pd.get_dummies( train[ supervised_column ] )
train = train.drop( [ supervised_column ], axis = 1 )
key_column = "PassengerId"
train = train.drop( [ key_column ], axis = 1 )
key = test[ key_column ].values
test = test.drop( [ key_column ], axis = 1 )
from keras.models import Sequential
from keras.optimizers import Adam
from keras.layers import Dense, Activation, Dropout
model = Sequential()
input_units = 128
input_activation = "relu"
model.add( Dense( input_dim = train.shape[ 1 ], units = input_units) )
model.add( Activation( input_activation ) )
hidden_layers = 15
hidden_units = 128
hidden_activation = "relu"
hidden_dropout = 0.20
for i in range( 0, hidden_layers ):
model.add( Dense( units = hidden_units ) )
model.add( Activation( hidden_activation ) )
model.add( Dropout( hidden_dropout ) )
output_units = 2
output_activation = "softmax"
model.add( Dense( units = output_units ) )
model.add( Activation( output_activation ) )
compile_loss = "categorical_crossentropy"
compile_optimizer = "adam"
compile_metrics = [ "accuracy" ]
model.compile(
loss = compile_loss,
optimizer = compile_optimizer,
metrics = compile_metrics
)
number_of_epochs = 500
model.fit( train.values, supervised.values, epochs = number_of_epochs )
score = model.evaluate( train, supervised, verbose = 0 )
predict = model.predict_classes( test.values )
submission = pd.DataFrame()
submission[ key_column ] = key
submission[ supervised_column ] = predict
submission.to_csv( "predict.csv", index = False )
そもそもKerasは、非常にシンプルなコード構成なので、設定値さえ流し込めれば、ノンコーディングで簡単にコード生成ができる訳です
なお、Early Stopping等の細かい設定は、Esunaに未だ実装できていませんが、それほど大変では無くエンハンスしていけると思います
これは一重に、Kerasの設計/凝縮度が、極めて良くできている、という賜物です
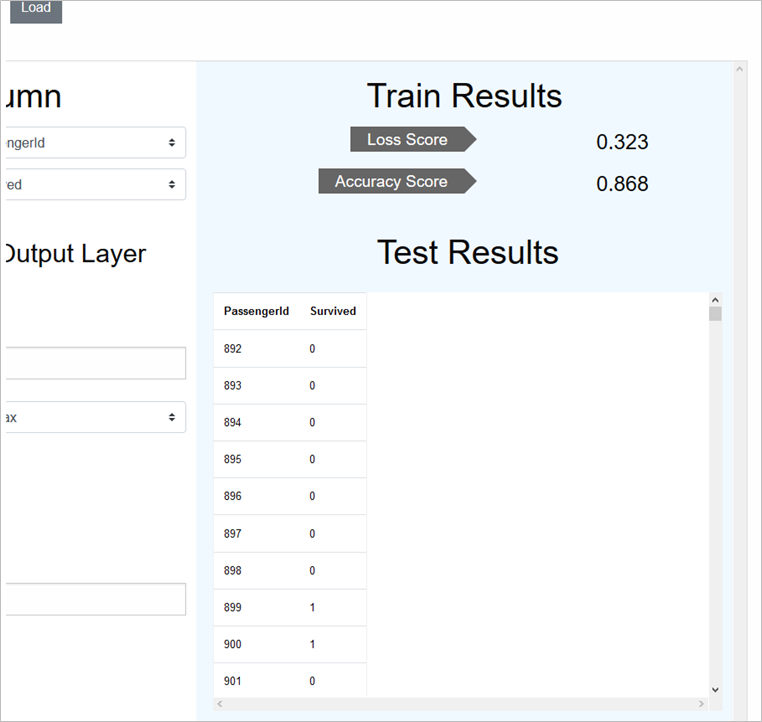
学習/テスト結果の確認
学習されたモデルの評価(上記コードのmodel.evaluateに相当)は、損失と正解率で出ます
テスト結果は、キー付きの予測値としてテーブル表示されます
第三部:テスト結果をKaggleに提出する
Kaggleコンペ提出用CSVをダウンロード
テストデータの予測結果は、「Download Test Results CSV」をクリックすると、CSVダウンロードできます
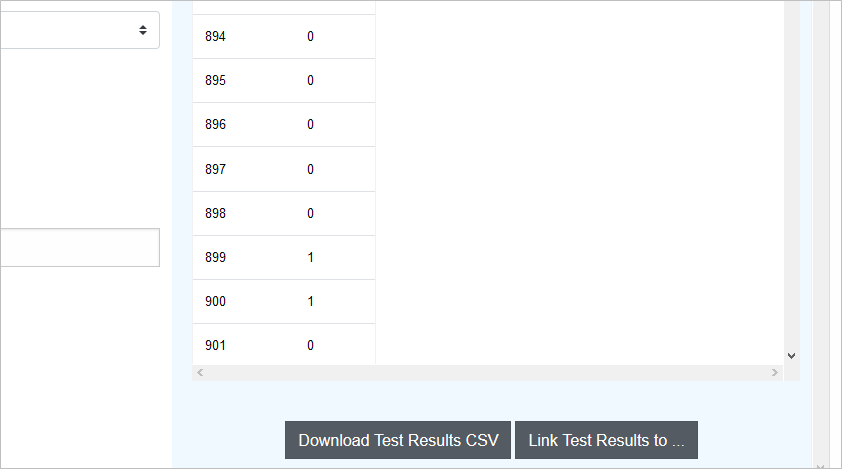
このファイルをKaggleコンペに提出(submit)します
Kaggleからテスト結果の精度が返ってくる
Kaggleコンペにsubmitしたところ、今回のKerasモデルでは、精度72.2%でした
ちなみに、比較用の参考までに、同じ前処理済みのデータにて、scikit-learnのRandomForestClassifierで実施したケースでは、精度69.9%でした
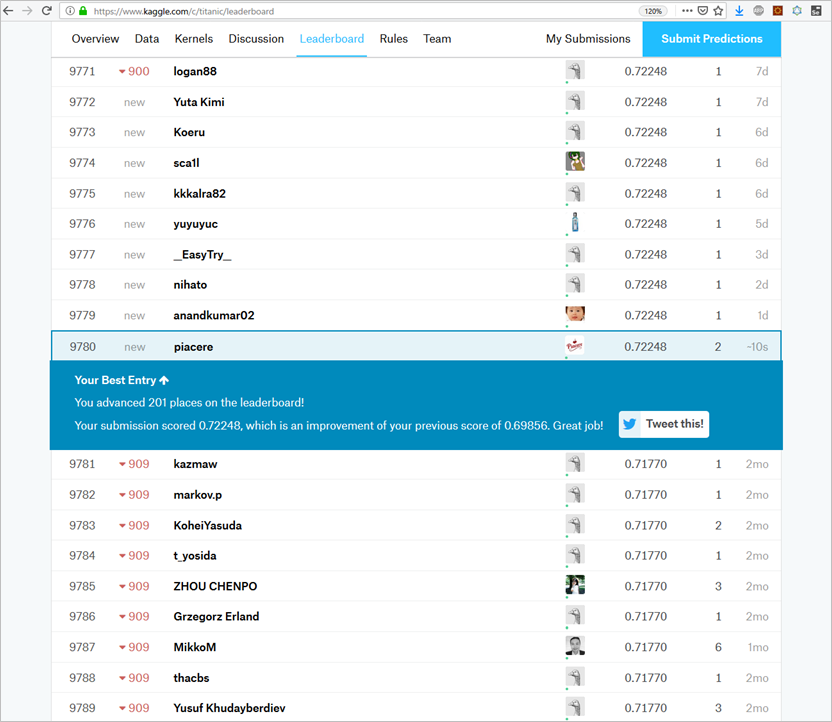
前処理もKerasが通る最低限しかやっておらず、モデル学習時に交差検証もしていないような適当過ぎるモデル構築だったので、こんなもんでしょう ![]()
今回は、Esunaの前処理+モデル構築をご紹介するための、最も手数の少ない手順でしたので、前処理の端々でコメントしたような、「業務傾向」を加味する本気チャレンジの経過は、また別途、コラム化したいと思います
Kaggleへの提出方法等も、そちらのコラムで解説するとし、今回は割愛します
今後Esunaに搭載したい機能
今回、Kaggleコンペに提出するまでの過程を通して、以下のような機能を、Esunaに搭載したいと思いました
- 前処理
- 欠損列の自動検出、欠損補完のレコメンド、自動補完
- impute_missing_stringで最頻値/最稀値の自動検出
- メニュー変更時の前処理を保存するか否かアラートする
- 前処理完了時、他の対象データの前処理もするかをアラートする
- CSVファイルを経由せずに、Kerasに前処理後データを渡せるようにする
- モデル構築
- 交差検証設定の追加、評価データの精度表示
- 入力データ指定は前処理後データの履歴から選択可に
- 設定項目が不完全なので補充する
- 解く問題の性格で、出力層活性化関数/損失関数/オプティマイザをレコメンド
- (できれば)Cloud AutoMLのようなリッチUI
- (できれば)転移学習、カプセルネットワーク、ENASを利用可能に
- モデル管理
- モデルのバージョン/訓練データ/精度の組み合わせを履歴保存
終わり
Kaggleのタイタニック予測にて、データサイエンスプラットフォーム「Esuna」を使い、前処理とKerasモデル生成/呼出を行ってみました
Esunaによる前処理とモデル生成/呼出は、非常にカンタンなUIから操作できることが、実感できたのでは無いかなぁ、と思います
まもなく、OSSとして公開されるEsunaを、楽しみにお待ちください ![]()
なお、現在はKerasのコードを生成していますが、来年の夏頃には、Elixir GPUドライバ「Hastega」の上で動く、Elixirで実装された機械学習/ディープラーニングエンジンにより、Elixir AI・MLのコードを生成できるようにする見込みです
こちらも、楽しみにお待ちください ![]()
(TensorFlow/Kerasモデルの解析が順調に進めば、TensorFlow/Kerasで作ったモデルをそのまま上記エンジンで動かせるようになるかも?)
p.s.「いいね」よろしくお願いします
ページ左上の  や
や  のクリックを、どうぞよろしくお願いします
のクリックを、どうぞよろしくお願いします![]()
ここの数字が増えると、書き手としては「ウケている」という感覚が得られ、連載を更に進化させていくモチベーションになりますので、もっとElixirネタを見たいというあなた、私達と一緒に盛り上げてください!![]()