ElixirImp/fukuoka.ex/kokura.exとLiveView JPの piacere です、ご覧いただいてありがとございます ![]()
ElixirではじめてAI・ML・ディープラーニングを学びたい方向けに、Pythonディープラーニング界の「Hello World」とも言える「MNIST手書き文字識別」をLivebook+Axonで実現します
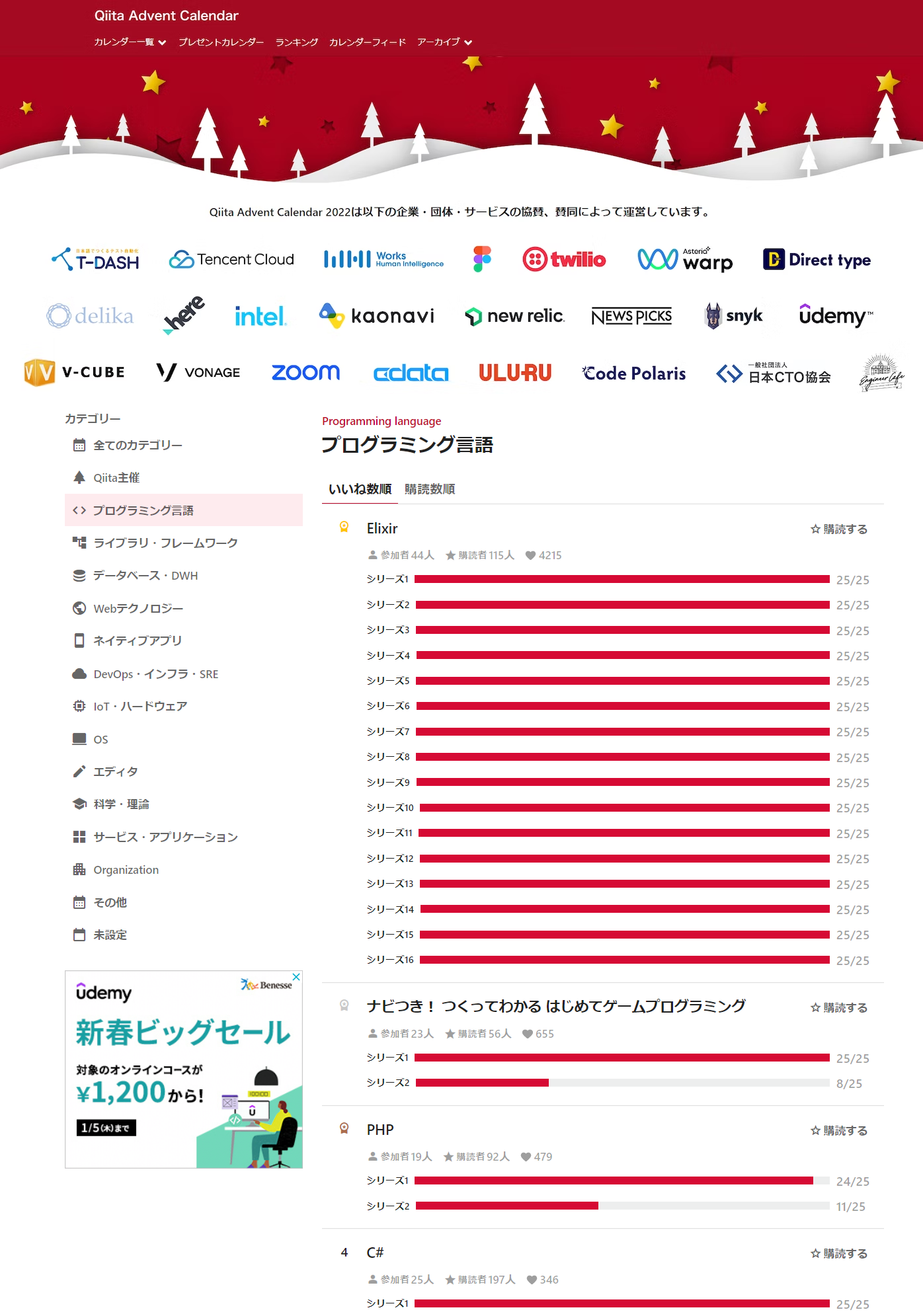
 Elixir Advent Calendar: 言語カテゴリ1位+全カテゴリ2位!
Elixir Advent Calendar: 言語カテゴリ1位+全カテゴリ2位!
例年を遥かに超える盛り上がりを見せ、堂々のトップ獲得ッ! ![]()
![]()
![]()
https://qiita.com/advent-calendar/2022/elixir
https://qiita.com/advent-calendar/2022/ranking/feedbacks
https://qiita.com/advent-calendar/2022/ranking/feedbacks/categories/programming_languages
本コラムの検証環境
本コラムは、以下環境で検証しています(Ubuntu実機やMacでも動くと思います)
検証環境①
- Windows 10+WSL2 Ubuntu 22.04
- Elixir 1.14.0 on WSL2 Ubuntu ※最新版のインストール手順はコチラ
- Livebook 0.7.2 ※最新版のインストール手順はコチラ
検証環境②
- Windows 11+WSL2 Ubuntu 18.04
- Elixir 1.14.0 on WSL2 Ubuntu ※最新版のインストール手順はコチラ
- Livebook 0.6.3 ※最新版のインストール手順はコチラ
「MNIST手書き文字識別」の概要
「MNIST(Modified National Institute of Standards and Technology database)」は、手書き文字画像が、0~9の数字のうち、どの数字により適合するかを識別する例題です
これは、「多クラス分類」と呼ばれる、複数のクラス(種類)への分類を行う例題となります
MNISTデータセットには、手書き文字画像(1文字は28 x 28ピクセル)と、それぞれの画像が何の数字であるかが0~9で入っているラベルで1セットの60,000文字分のデータが含まれています
大まかな処理の流れは下図の通りで、手書き文字識別を行う「モデル」を学習させ、そのモデルに手書き文字画像を渡すと、それが0~9のどの数字に最も適合するかを予測できるようになります
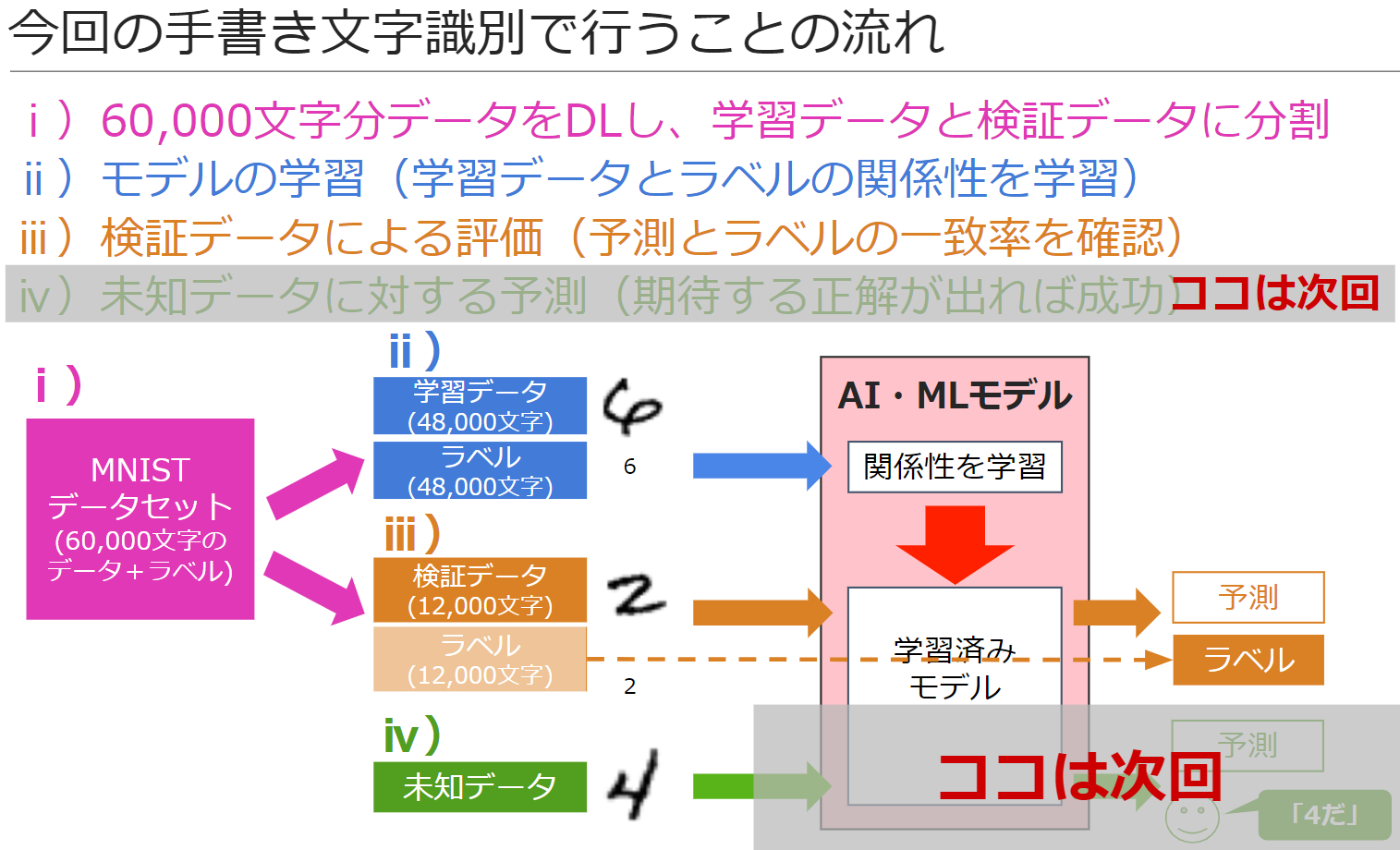
なお評価のために、60,000文字全てを学習には使い切らず、80%の48,000文字で学習を行い、残り20%の12,000文字は、モデル評価用の「検証データ」とします
これは、データ全域を学習データとしてしまうと、未知データが来た際に予測が間違うようなモデルが作られるのを避けるためです(こうした学習データでしか機能しない状態を「過学習」と呼びます)
最終的なコード
下記のコードで、手書き文字識別が実現できます(以降の節で各パートの解説をします)
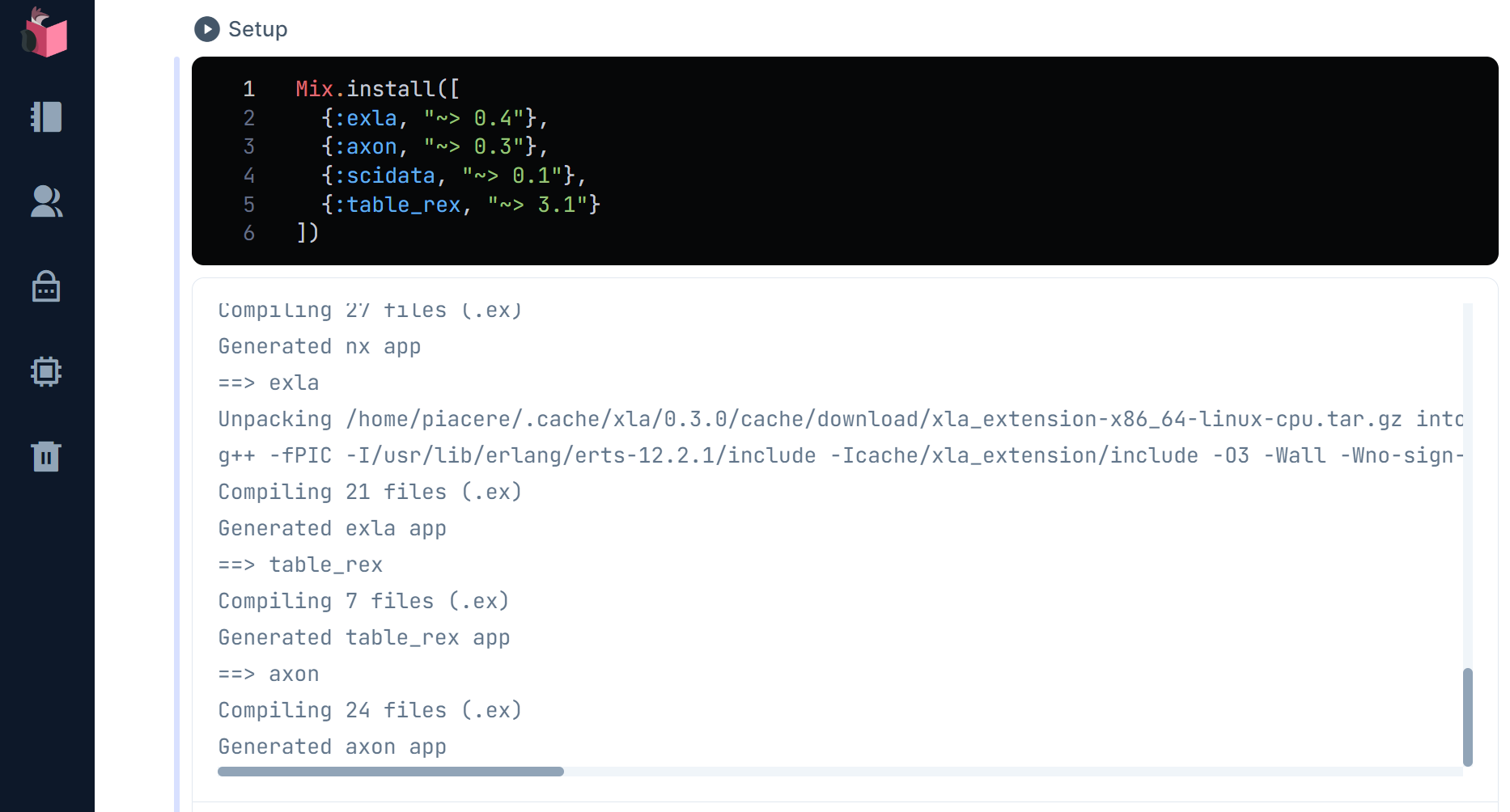
Mix.install([
{:exla, "~> 0.4"},
{:axon, "~> 0.3"},
{:scidata, "~> 0.1"},
{:table_rex, "~> 3.1"}
])
{datas_raw, labels_raw} = Scidata.MNIST.download()
{data_bins, type, shape} = datas_raw
datas = data_bins
|> Nx.from_binary(type)
|> Nx.reshape({elem(shape, 0), 784})
|> Nx.divide(255.0)
{label_bins, type, shape} = labels_raw
labels = label_bins
|> Nx.from_binary(type)
|> Nx.new_axis(-1)
|> Nx.equal(Nx.tensor(Enum.to_list(0..9)))
{train_datas, test_datas} = datas
|> Nx.to_batched(32) # 32文字ごとにバッチ化
|> Enum.split(round(60000 * 0.8 / 32)) # 80%をtrainに、20%をtestに
{train_labels, test_labels} = labels
|> Nx.to_batched(32) # 32文字ごとにバッチ化
|> Enum.split(round(60000 * 0.8 / 32)) # 80%をtrainに、20%をtestに
require Axon
model = Axon.input("input", shape: {nil, 784})
|> Axon.dense(128, activation: :relu)
|> Axon.dropout()
|> Axon.dense(10, activation: :softmax)
Axon.Display.as_table(model, Nx.template({1, 784}, :f32))
|> IO.puts
alias Axon.Loop.State
trained_state = model
|> Axon.Loop.trainer(:categorical_cross_entropy, Axon.Optimizers.adamw(0.005))
|> Axon.Loop.metric(:accuracy, "Accuracy") # 計算過程を表示するための処理
|> Axon.Loop.handle(:iteration_completed, fn state ->
%State{epoch: epoch, iteration: iteration, metrics: metrics, step_state: step_state} = state
%{loss: loss} = step_state
"Loss: #{:io_lib.format('~.5f', [Nx.to_number(loss)])}"
metrics =
metrics
|> Enum.map(fn {k, v} -> "#{k}: #{:io_lib.format('~.5f', [Nx.to_number(v)])}" end)
|> Enum.join(" ")
IO.write("\rEpoch: #{Nx.to_number(epoch)}, Batch: #{Nx.to_number(iteration)}, #{metrics}")
{:continue, state}
end)
|> Axon.Loop.run(Stream.zip(train_datas, train_labels), %{}, epochs: 3, compiler: EXLA)
model
|> Axon.Loop.evaluator()
|> Axon.Loop.metric(:accuracy, "Accuracy")
|> Axon.Loop.run(Stream.zip(test_datas, test_labels), trained_state, compiler: EXLA)
n = 0
m = 0
Enum.at(test_datas, n)[m]
|> Nx.reshape({28,28})
|> Nx.to_heatmap
Enum.at(y_test, n)[m]
Axon.predict(model, trained_state, Enum.at(test_datas, n))[m]
|> Nx.map(& Nx.round(&1))
各パートについて解説
ライブラリのロード
Livebook最上部の「Notebook dependencies and setup」で、下記を実行し、必要ライブラリをロードしてください
Mix.install([
Mix.install([
{:exla, "~> 0.4"},
{:axon, "~> 0.3"},
{:scidata, "~> 0.1"},
{:table_rex, "~> 3.1"}
])
Livebookが初めての方は、基本的な操作をこちらのコラムで学べます
ⅰ)学習データと検証データの準備
MNISTデータセットをダウンロードし、学習用データと、モデル精度を評価するための検証データに分割します
ⅰ-1.MNISTデータセットをダウンロード
様々なデータセットを扱える「Scidata」を使って、MNISTデータセットをダウンロードします
中身は、手書き文字画像データ群とラベルデータ群のデータセットとなっているので、datas_rawとlabels_rawに分割して扱っていきます
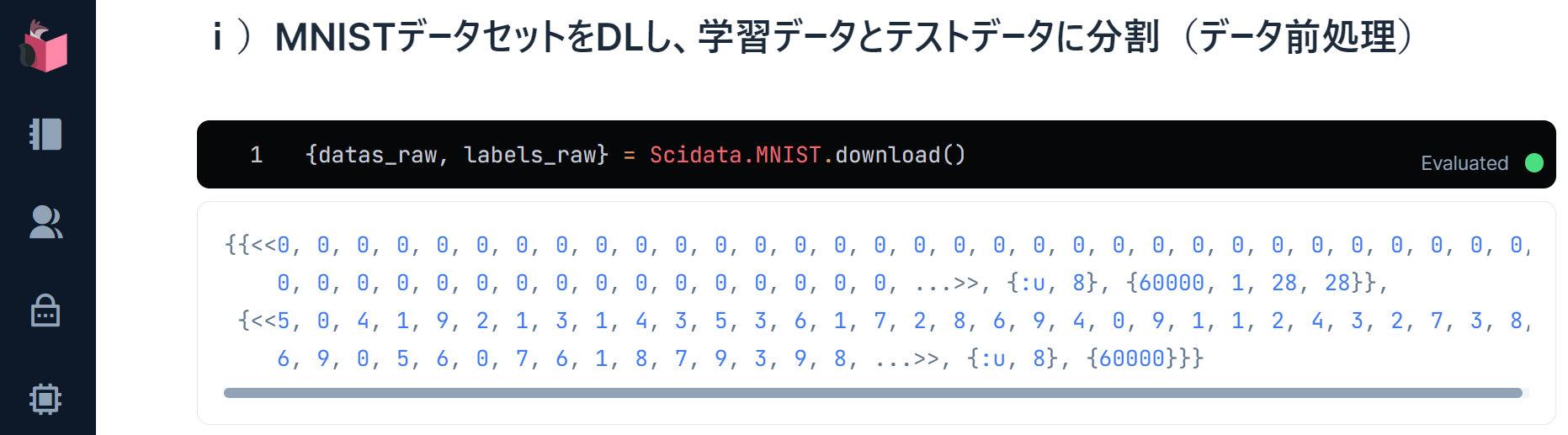
{datas_raw, labels_raw} = Scidata.MNIST.download()
datas_rawの中身は、「60,000文字分の手書き文字画像バイナリ」「型」「シェイプ(文字数、バイナリの次元数、横ピクセル数、縦ピクセル数)」で1セットのタプルになっています
ⅰ-2.手書き文字画像データを1文字ずつで扱えるようにする
datas_rawの「60,000文字分の手書き文字画像バイナリ」「型」「シェイプ」をそれぞれ「data_bins」「type」「shape」に分解し、更にdata_binsを1文字ずつで扱えるように分解します
{data_bins, type, shape} = datas_raw
datas = data_bins
|> Nx.from_binary(type)
|> Nx.reshape({elem(shape, 0), 784})
|> Nx.divide(255.0)
試しに適当な1文字の手書き文字画像をヒートマップ表示してみます
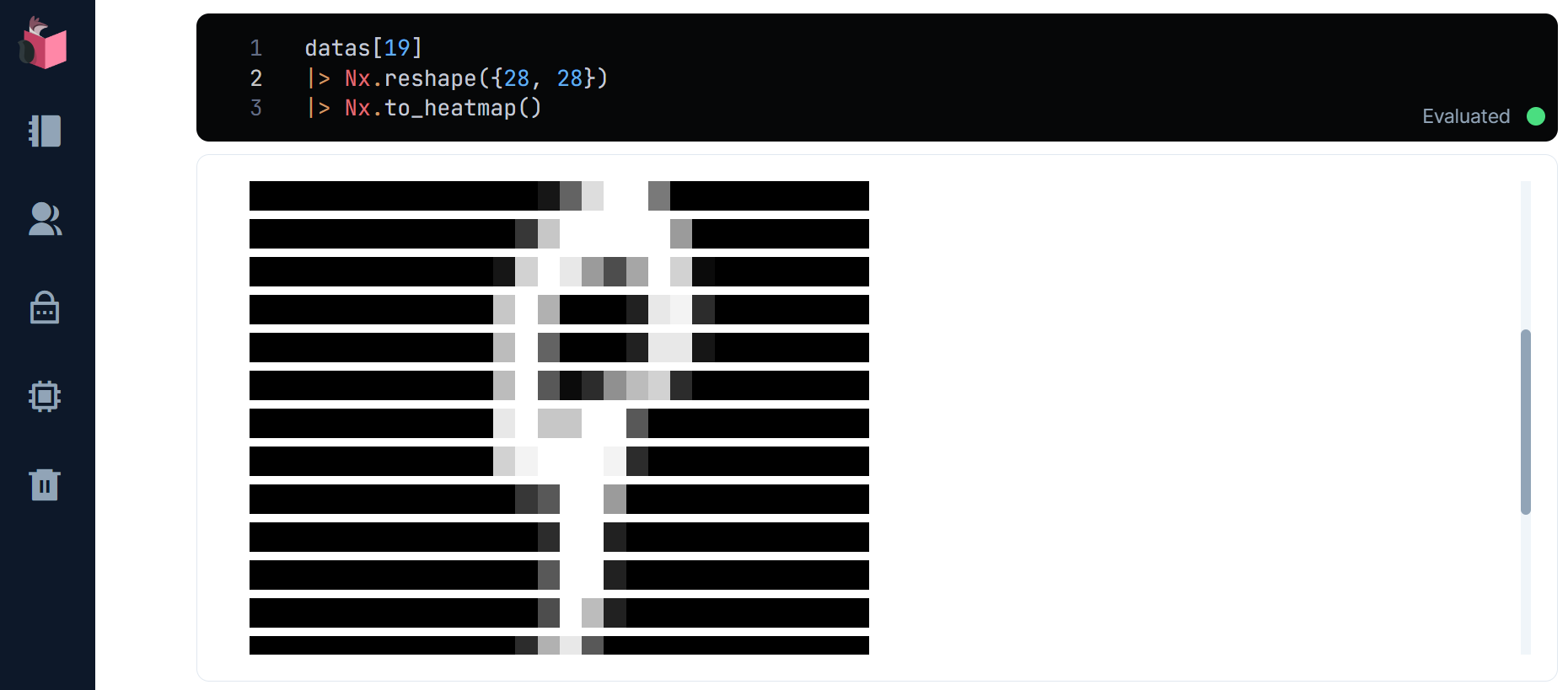
ここで、1文字分の手書き文字画像データは、28 x 28 = 784ピクセルの1次元行列となっているため、そのままではヒートマップ表示しても手書き文字に見えないため、28 x 28の2次元行列に変形してから、ヒートマップ表示します(この例では0オリジンで20番目の文字を表示)
datas[19]
|> Nx.reshape({28,28})
|> Nx.to_heatmap
20番目の文字は、「9」のようです(添字の19を変更して、他のデータも見てみてください)
ⅰ-3.ラベルを1文字ずつで扱えるようにする
labels_rawの中身は、「60,000文字分の手書き文字画像のラベル値」「型」「文字数」で1セットのタプルになっています
labelsの、「60,000文字分の手書き文字画像のラベル値」「型」「文字数」をそれぞれ「bin」「type」「shape」に分解し、更にbinを1文字ずつで扱えるように分解します
{label_bins, type, shape} = labels_raw
labels = label_bins
|> Nx.from_binary(type)
|> Nx.new_axis(-1)
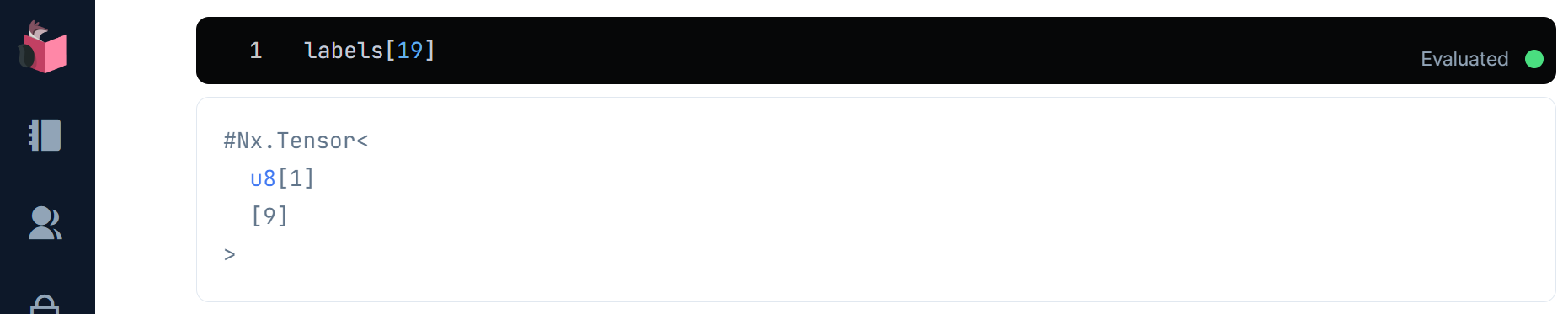
試しに適当な1文字のラベルを表示してみます(この例では0オリジンで20番目の文字を表示)
labels[19]
20番目のラベルが、手書き文字と同様、「9」であることが確認できます(添字の19を変更して、他のデータも見てみてください)
ⅰ-4.ラベルを数値からクラス行列に変形
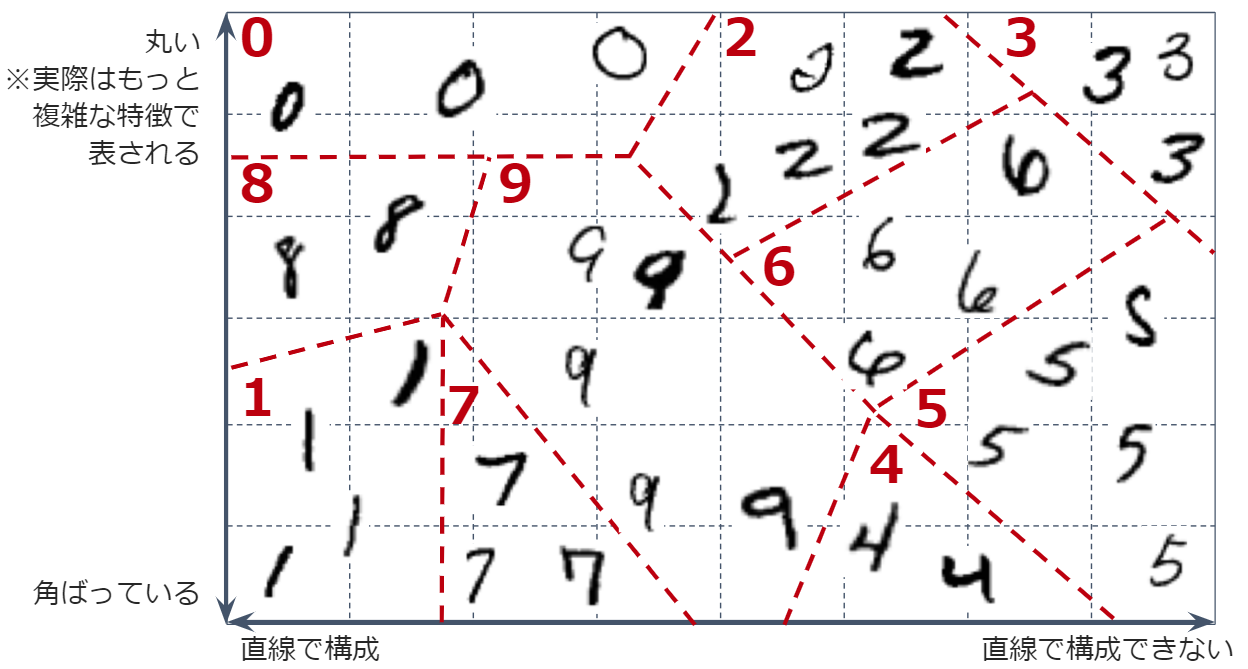
MNISTのような多クラス分類では、予測の結果を、長さ10の1次元行列の先頭から各要素ごとに0、1、2、…9を意味するよう割り当て、その要素の値が1に近いときはその数字に適合(0に近いときは不適合)するような行列として表現します
イメージとしては、下図の通りです(実際は、0や1ピッタリにはならず、0~1の間の小数になります)
ラベルをこの形式に変形しておきます
labels_data = labels_raw_data
|> Nx.equal(Nx.tensor(Enum.to_list(0..9)))
試しに適当な1文字のクラス行列化されたラベルを表示してみます(この例では0オリジンで20番目の文字を表示)
labels_data[19]
20番目のラベルのクラス行列は、10番目が1であり、先頭要素から0~9を示すため、「9」を示すことが確認できました(添字を変えて、他のデータも見てみてください)

ⅰ-5.学習データと検証データの分割
手書き文字データとラベルの両方を、学習データ80%(48,000文字分)、検証データ20%(12,000文字分)に分割します
なお、学習速度・並列度アップと過学習回避を目的とした「バッチ学習」のためのデータ分割として、32文字ずつのグループ分割もその手前で行います
{train_datas, test_datas} = datas
|> Nx.to_batched(32) # 32文字ごとにバッチ化
|> Enum.split(round(60000 * 0.8 / 32)) # 80%をtrainに、20%をtestに
分割できました
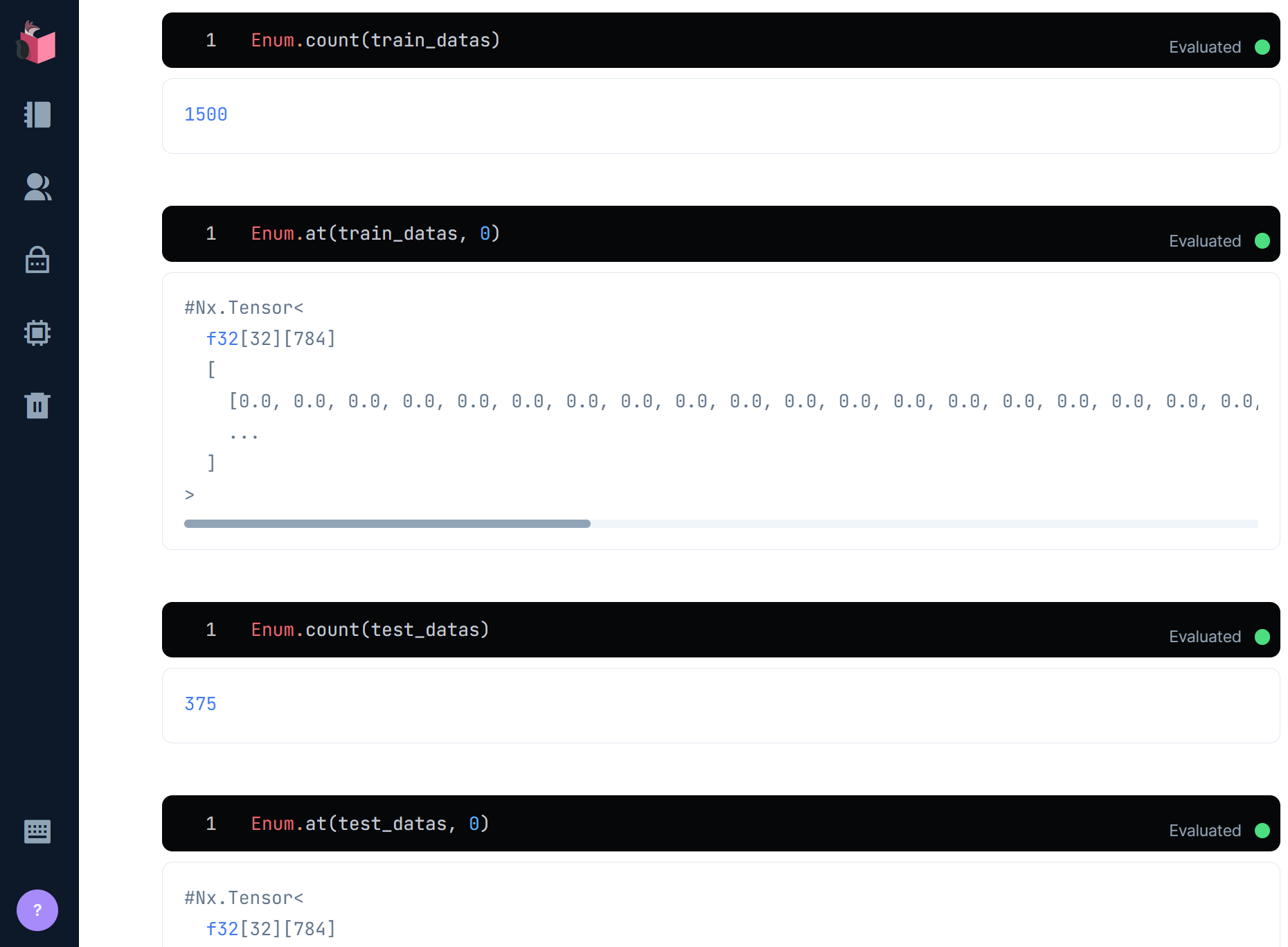
ラベルも、学習データ48,000文字分、検証データ12,000文字分に分割します
{train_labels, test_labels} = labels
|> Nx.to_batched(32) # 32文字ごとにバッチ化
|> Enum.split(round(60000 * 0.8 / 32)) # 80%をtrainに、20%をtestに
以下コードで、各バッチごとの全32文字の手書き文字画像をヒートマップで表示して確認することもできます
# a番目のバッチの全32文字の手書き文字画像をリスト
a = 0
Enum.map(test_datas, & &1[a]
|> Nx.reshape({28,28})
|> Nx.to_heatmap)
以下コードで、各バッチごとの全32文字のラベルを表示して確認することもできます
# b番目のバッチの全32文字のラベルをリスト
b = 0
Enum.map(test_labels, & &1[b])
ⅱ)モデルの構築/学習
モデルを構築し、そのモデルを学習データで学習させます
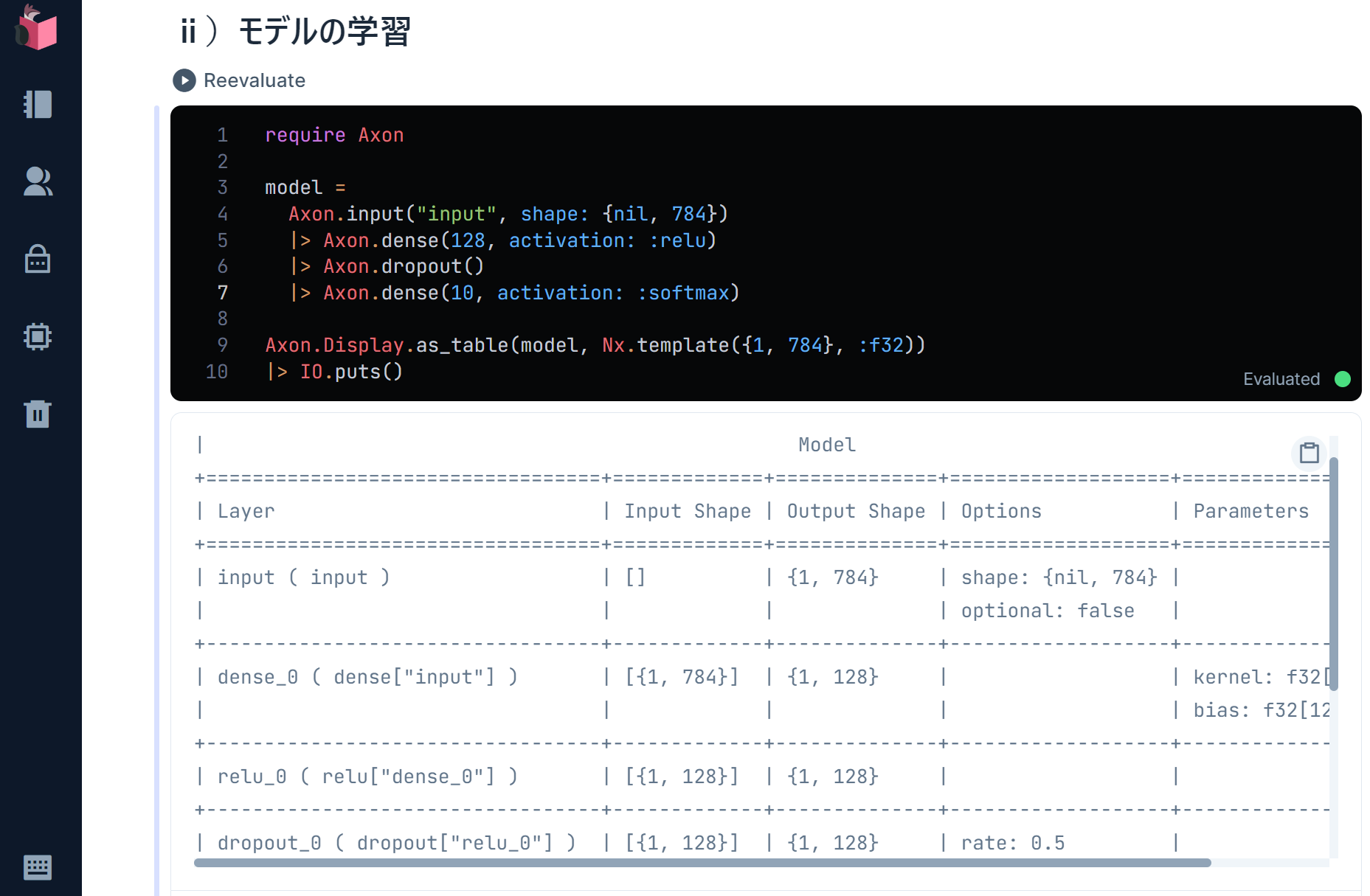
ⅱ-1.Axonでモデル構築
Axonは、入力層と、活性化関数を含む中間層、分類や回帰を行う出力層で、モデルを構成します
中間層は、計算効率の良いReLUを活性化関数として設定し、ランダムでニューラルネットワークの間引きを行うことで過学習回避を実現するドロップアウトも設定します
出力層は、他クラス分類に向いているソフトマックス関数を設定します
require Axon
model = Axon.input("input", shape: {nil, 784})
|> Axon.dense(128, activation: :relu)
|> Axon.dropout()
|> Axon.dense(10, activation: :softmax)
Axon.Display.as_table(model, Nx.template({1, 784}, :f32))
|> IO.puts
構築されたモデルが、下記のようにサマリーとして表示されます
ⅱ-2.モデルの学習
AxonのLoopモジュールにある学習機能を使って、モデルの学習を行います
損失関数は、多クラス分類のための「カテゴリカル交差エントロピー」を使います
最適化関数は、収束が速く、使い勝手が良い「Adam」に、パラメータの自由度を制限するWeight decayを追加した「AdamW」を使います
これらはAxon.loop.trainer()で指定します
精度の評価は「正解率」で行うことをAxon.loop.metric()で指定します
Axon.loop.handle()にて、バッチが回るたびに同エポック内の正解率(Accuracy)と学習誤差(loss)を表示更新するようにします
学習試行回数であるエポック数は、5~10回にして、精度向上したいのですが、今回はAxonをGPUと比べて実行が遅いCPUモードで動かすことから、3回のみとします(なおGPUで動かす場合の解説は、次回以降の続編で解説します)
エポック数および学習データとなる手書き文字画像(train_datas)とラベル(train_labels)は、Axon.loop.run()で指定します(空マップを指定している箇所には、利用するモデルを指定できますが、学習時は空マップを指定します)
alias Axon.Loop.State
trained_state = model
|> Axon.Loop.trainer(:categorical_cross_entropy, Axon.Optimizers.adamw(0.005))
|> Axon.Loop.metric(:accuracy, "Accuracy") # 計算過程を表示するための処理
|> Axon.Loop.handle(:iteration_completed, fn state ->
%State{epoch: epoch, iteration: iteration, metrics: metrics, step_state: step_state} = state
%{loss: loss} = step_state
"Loss: #{:io_lib.format('~.5f', [Nx.to_number(loss)])}"
metrics =
metrics
|> Enum.map(fn {k, v} -> "#{k}: #{:io_lib.format('~.5f', [Nx.to_number(v)])}" end)
|> Enum.join(" ")
IO.write("\rEpoch: #{Nx.to_number(epoch)}, Batch: #{Nx.to_number(iteration)}, #{metrics}")
{:continue, state}
end)
|> Axon.Loop.run(Stream.zip(train_datas, train_labels), %{}, epochs: 3, compiler: EXLA)
1エポックあたりのバッチ実行回数は、学習データ件数48,000に対し、32文字分を1バッチサイズにしているので、48,000 ÷ 32 = 1,500バッチとなることが、実行結果の「Batch」で分かります
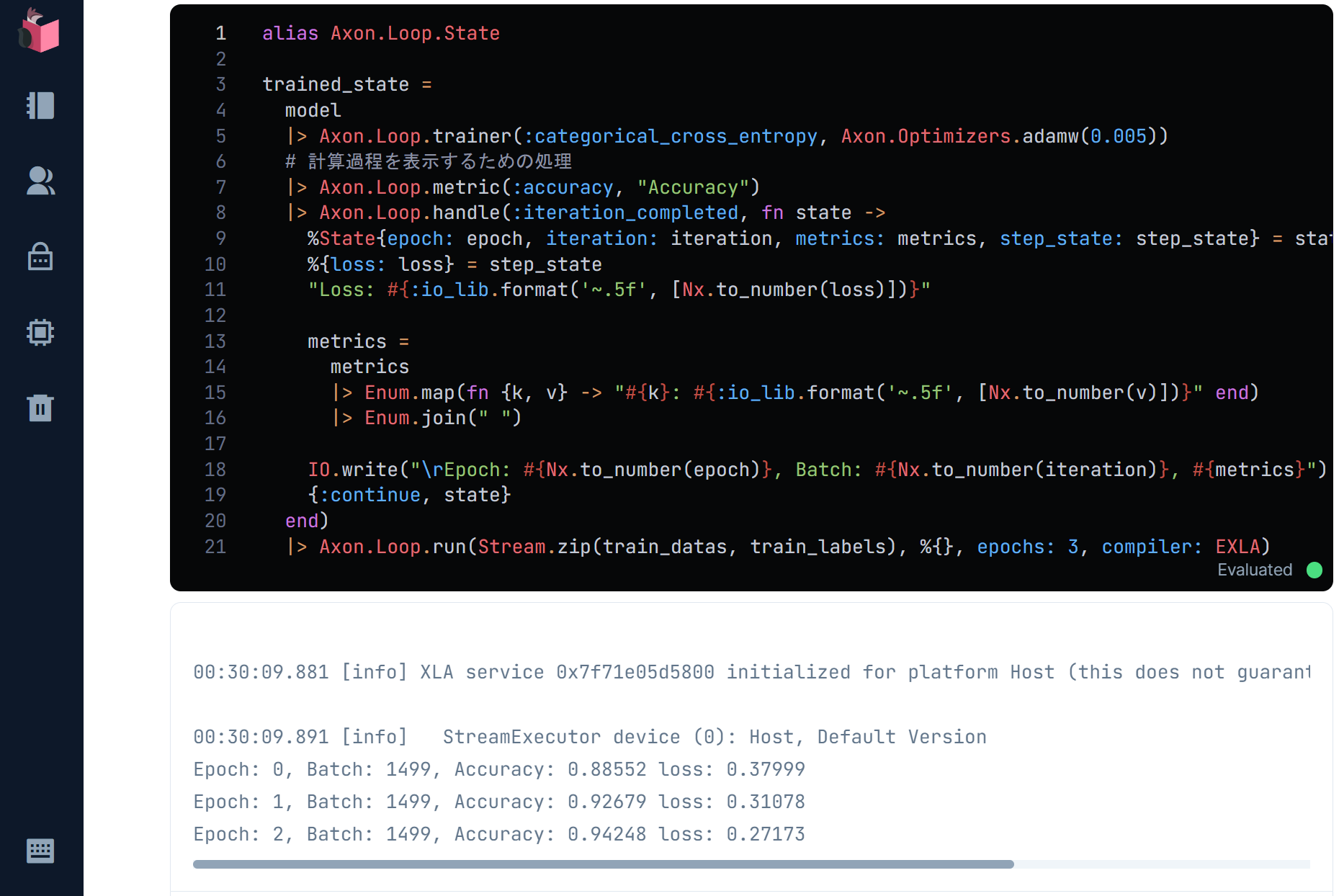
なお、Axon.Loop.handle()内の関数の戻り値で{:continue, state}では無く、{:halt_loop, state}を返却すると、学習を中断できるので、正解率や誤差の値で早期に学習を打ち切る「Early Stopping」を判断することも可能です
ⅲ)検証データによる学習済みモデルの評価
検証データで、学習済みモデルでの予測を行い、モデルの精度を評価します
ⅲ-1.手書き文字画像全量での予測の正解率チェック
Axon.Loop.evaluator()を使うことで、正解率をチェックすることができます
Axon.Loop.run()の学習時に空マップを指定してた箇所に、学習済みモデルの結果(trained_state)を指定することで、学習は行わず、学習済みモデルによる予測を行うモードとなります
model
|> Axon.Loop.evaluator()
|> Axon.Loop.metric(:accuracy, "Accuracy")
|> Axon.Loop.run(Stream.zip(test_datas, test_labels), trained_state, compiler: EXLA)
実行結果は、下図の通りで、正解率(Accuracy)が「0.954…」と出ていますが、この値が1に近いほど、検証データでの手書き文字の予測と、ラベルの一致度が高く、予測精度が高いことを意味します
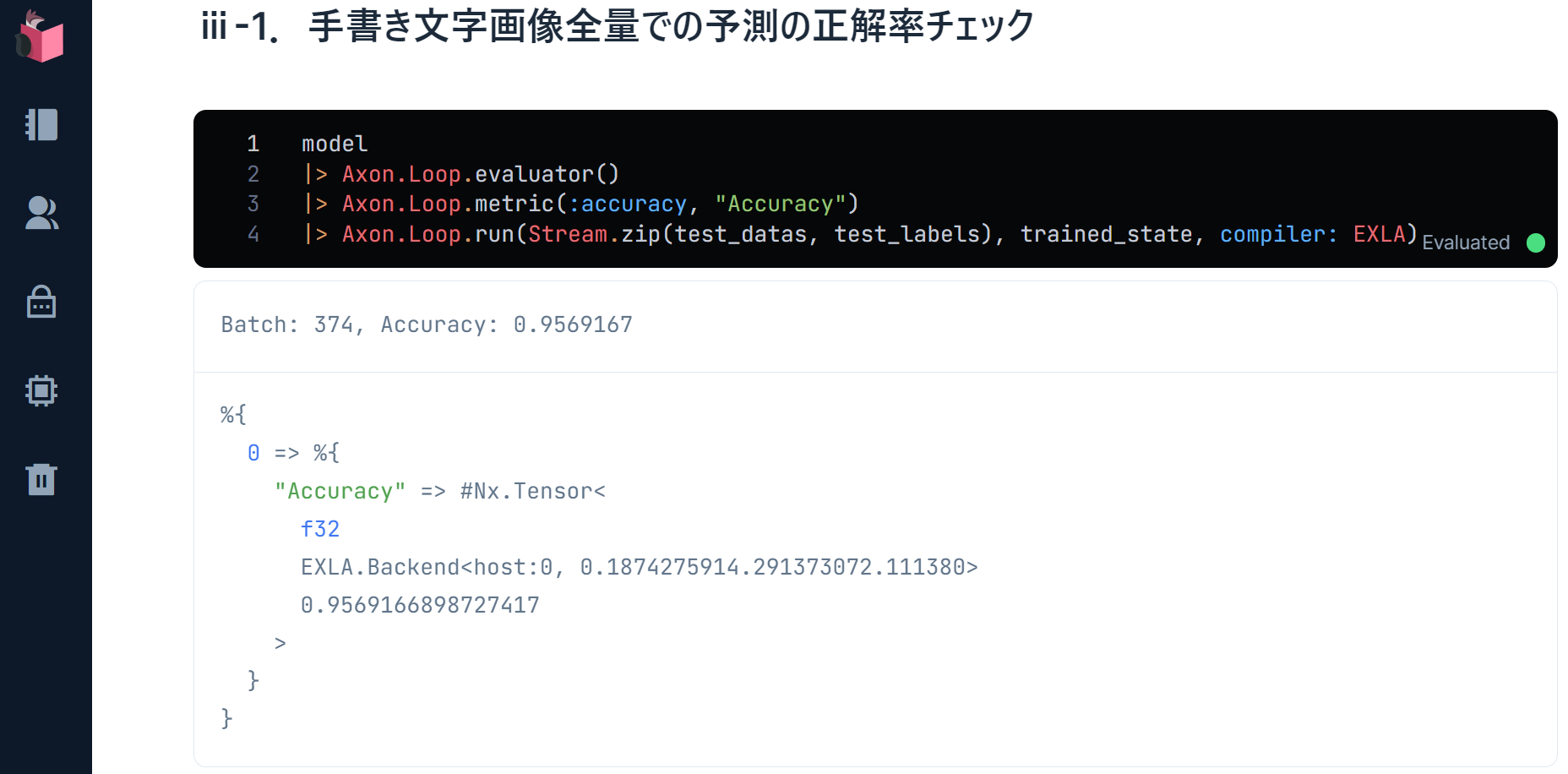
0.7~0.8位あれば、割と使えるモデルということで、今回の結果は、エポック数が少ない割には良い精度だと思います
ⅲ-2.1文字ずつの予測の一致チェック
今度は、全量では無く、1文字ずつの精度を見ていきます
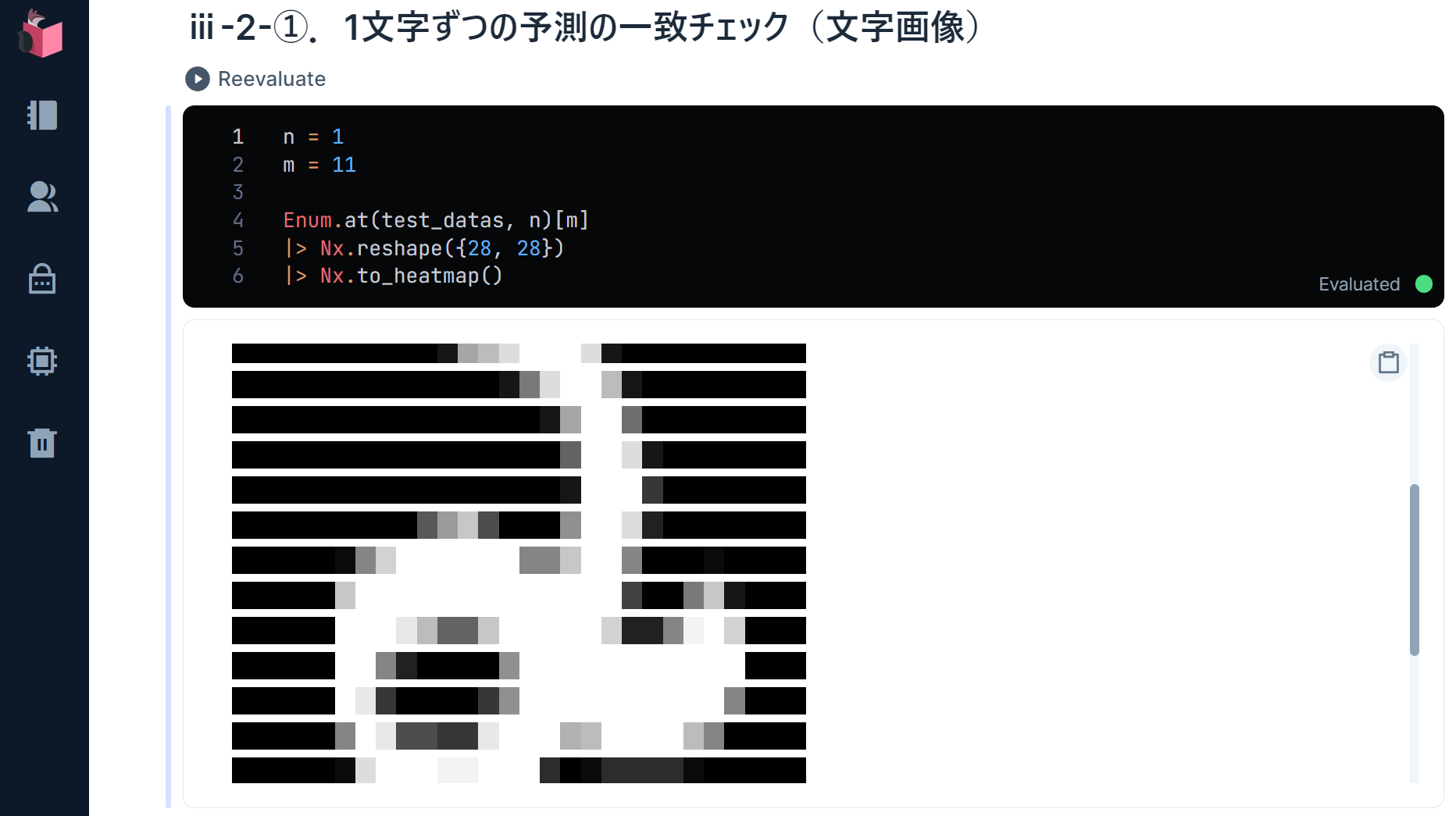
対象となる手書き文字をまず確認します
n = 10
m = 10
Enum.at(test_datas, n)[m]
|> Nx.reshape({28,28})
|> Nx.to_heatmap
1番目のバッチの11文字目は、かなり崩れた「2」のようです
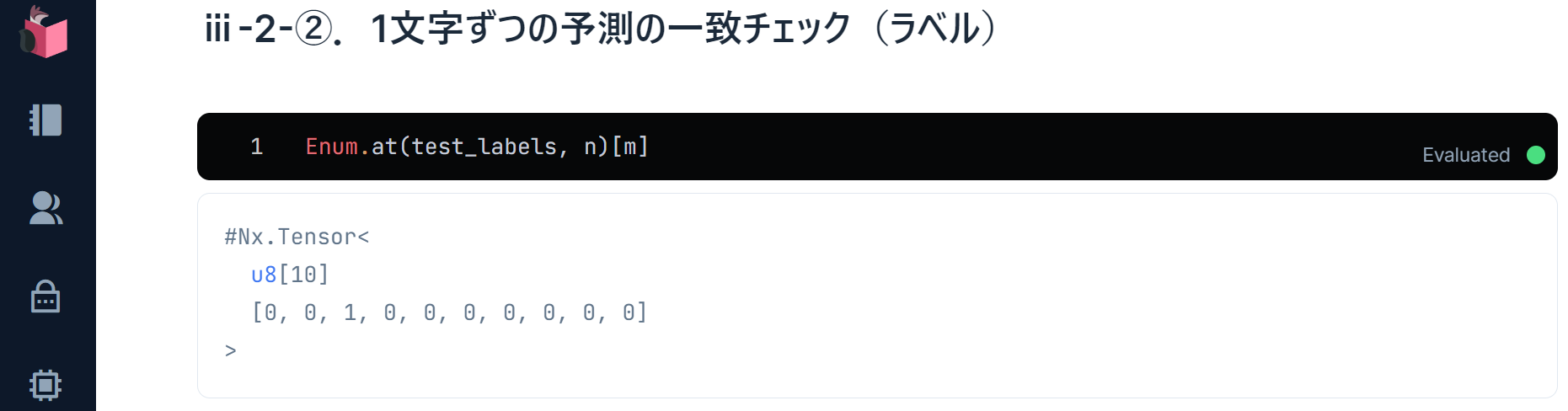
ラベルも確認します
Enum.at(test_labels, n)[m]
やはり「2」のようです
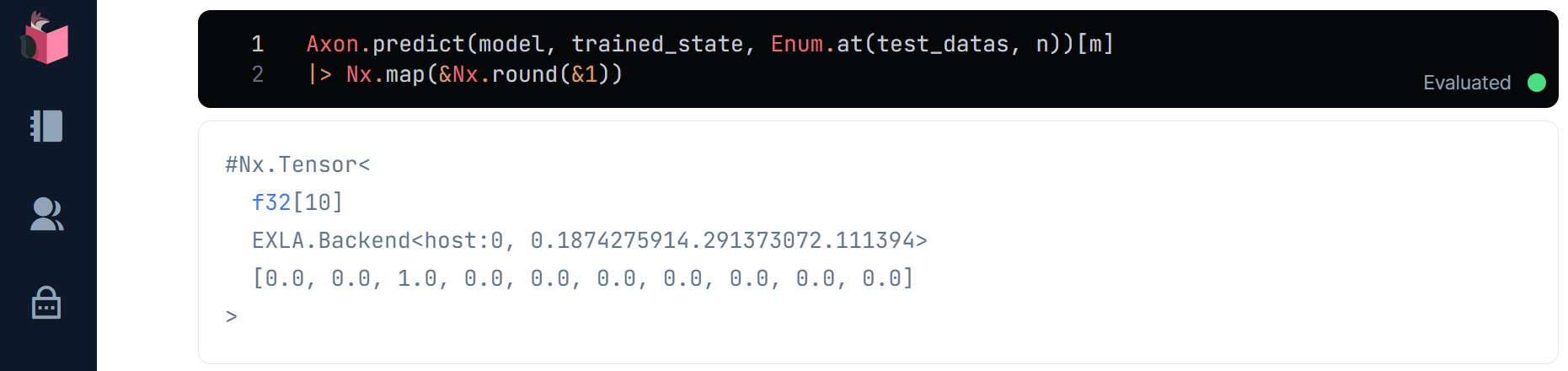
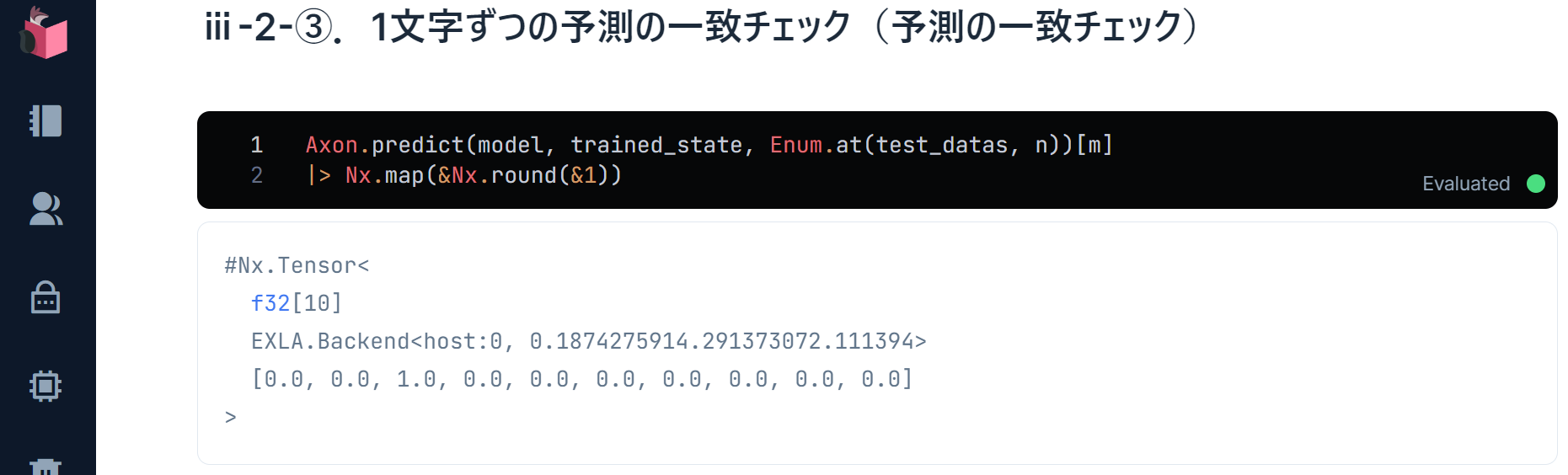
Axon.predict()で、この手書き文字がどのように識別されるか予測してみましょう
Axon.predict(model, trained_state, Enum.at(test_datas, n))[m]
|> Nx.map(& Nx.round(&1))
予測も「2」で、一致が確認できました(添字を変えて、他のデータも見てみてください)
終わり
今回は、MNIST手書き文字識別をLivebook+Axonで実現することを通して、Elixirでのディープラーニングを体験しました
Livebook+Axonを使うことで、PythonのJupyterNotebookやColaboratory、NumPy、Kerasを使ったときとほぼ同じフィーリングでAI・ML開発ができます
次回は、ブラウザ上で手書き文字を書いて、リアルタイムで手書き文字識別することを行います
主催/運営しているElixirコミュニティ紹介
4. LiveView JP : A place to mob-program in LiveView, LiveBook+Nx+Axon, and elixir-desktop
5. Neos.ex : A place to connecting Elixir and NeosVR to create a new world
Elixir生誕10周年を祝い、"Elixirの現在" に追いつける
Elixir界隈に激震をもたらした2021年の大変動を活用するコラム群を日々アップデートしています
本コラムも、第3弾「Elixir/Livebook+NxでPythonっぽくAI・ML」に追加しています
p.s.このコラムが、面白かったり、役に立ったら…
 や
や  にて、どうぞ応援よろしくお願いします:bow
にて、どうぞ応援よろしくお願いします:bow