この記事は、「TensorFlow Advent Calendar 2017」の24日目です
Merry Xmas! ![]()
piacere と申します ![]()
今年9月、11年ぶりの大規模な「太陽フレア」の地球到来が、けっこう話題になり、広範囲にオーロラが出たことでも記憶に新しいかと思いますが、この「太陽フレア」をディープラーニングで予測できないか、試してみたいと思います ![]()

なお、タイトルが「第3回」となっているのは、以下2つの続編(?)のためです ![]()
- 「第1回:地球の重力下で人工衛星を公転軌道に乗せる」
- 「万有引力の法則」の数式を偏微分し、JavaScriptでビジュアルプログラミング
- 2017/9の福岡数学イベントで「動画付きスライド」+「実際に動くプログラムとコード」にて登壇
- 「第2回:重力波を解析する」
- 重力波の観測データを、Jupyter Notebook上で信号処理により波形解析し、予測波形通りにマッチングするか検証
- 「数学とコンピュータ Advent Calendar 2017」の15日目としてコラム公開
- 2017/12の福岡Pythonイベントで「動画付きスライド」+「実際に動くプログラムとコード」にて登壇
- Qiitaスライド版もあります(全画面表示でご覧ください)
私は普段、福岡のスタートアップ企業で、「ビッグデータ分析+AI・ML開発の統括」と「Elixir/Kerasリードプログラマ」をしながら、社内外の勉強会を主催するCTOですが、業務で数学・物理学を使う機会はほぼありませんので、説明等に拙い点が多々あるかと思いますが、暖かい目でご容赦いただけると幸いです
なお、Twitterでは、ハッシュタグ#QuaUnivFukuoka にて、重力や宇宙、物理・数学関連のネタをつぶやいてますので、フォローいただけたら幸いです ![]()
太陽フレアとは?
「太陽フレア」は、太陽の表面で起きる爆発現象です
以下の動画で、どんなイメージかご覧ください
https://www.youtube.com/watch?time_continue=89&v=1MI3YDGgtN4

冒頭で大規模な太陽フレア(通常の1,000倍)の発生に伴う「太陽風」が発生し、飛んでいき、3:00あたりで地球の地磁気にぶつかり、地磁気が千切れ、千切れた地磁気がオーロラになる様が見れます
「太陽風」とは、電気を帯びた高温なプラズマで、100万トンもの質量があり、地球到達時の速度は約300~900km/s、温度は10の6乗(1,000,000度弱!)と、まともにぶつかったら人類がサクっと滅亡するレベルのものが飛んできていた、という訳です ![]()
そんなトンデモないものが飛んできているのに、何故、私達が滅亡せずにいられるかというと、冒頭の動画でご覧いただいた通り、「地磁気」と呼ばれる、地球周辺に発生している磁場がバリアの役割をしてくれているからです(ただし、通信衛星、放送衛星などの人工衛星に影響を及ぼすため、太陽風が衝突した際は、GPSに誤差が生じたりします)
太陽フレアの発生を予測する活動
さて、地磁気に守られているとはいえ、そんな物騒なものが飛んでくるのを放置する訳にもいかないので、世界レベルで、太陽フレアの発生を予測する活動が行われています
たとえば国内だと、NICT( National Institute of Information and Communications Technology:情報通信研究機構)と呼ばれる機関で、世界トップクラスとなる予測精度80%以上を実現する、機械学習とビッグデータを用いた太陽フレアの発生予測モデルが、今年2月にプレスリリースされました
https://www.astroarts.co.jp/article/hl/a/8959_prediction

具体的には、大量の太陽画像を元に、黒点の特徴を、SVM(サポートベクターマシン)、KNN(k近傍法)、ERT(アンサンブル学習)の3つで同時に機械学習方させ、24時間以内の太陽フレア発生を高精度で予測できるようにしました
オープンデータとして入手できる太陽フレアの観測データ
上記でご紹介したような、膨大なビッグデータによる機械学習のレベルは、そもそもデータの入手から難しい領域なのですが、オープンデータとして公開されている観測データが、実はあります
NOAA(National Oceanic and Atomospheeic Administration:米国海洋大気圏局)という、海洋と大気の調査・研究を専門とするアメリカの政府機関(本部はメリーランド州シルバースプリング)が、以下サイトで公開しています
Real Time Solar Wind | NOAA / NWS Space Weather Prediction Center
http://www.swpc.noaa.gov/products/real-time-solar-wind
過去7日分のデータをダウンロードできるので、こちらを使って、簡単な予測をしてみましょう ![]()
過去データから未来の太陽フレアを予測してみる
ディープラーニングを実行するための開発環境を揃えてから、NOAAのデータを使った予測をKerasで開発してみます ![]()
Python 3.xのインストール
Anacondaを使うと、Pythonおよび関連ライブラリのインストールが簡単になります
Anacondaのインストール方法は、AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」という別シリーズでも扱っているため、こちらのスライドのP13~P16をご参考ください

必要ライブラリのインストール
スライドP17にある通り、TensorFlowとKerasをインストールしてください
作業フォルダの作成
作業フォルダを作成します
mkdir -p 【任意の場所で、任意のフォルダ名】
cd 【上記の場所・フォルダ名】
ここでは、「/piacere/code/solar_wind」というフォルダ名を使います
mkdir -p /piacere/code/solar_wind
cd /piacere/code/solar_wind
なお、Jupyter Notebookでも一応実行はできるのですが、学習ログの表示等が遅いため、ターミナル上のPythonで行うこととします
観測データを入手する
NOAAが提供する観測データは、以下URLからダウンロードできます
上記URLをクリックし、下部にある「1day」プルダウンを「7days」に変更し、グラフ更新が終わったら、「Save as text」をクリックして、手元にダウンロードしてください
以下のような、1分間隔の太陽風各種時系列データの入ったTSVがダウンロードされます
Timestamp Bt Bx By Bz Phi Theta Dens Speed Temp
2017-12-18 00:00:00.000 7.72 -6.12 2.94 3.62 154.32 28.05 -99999 -99999 -99999
2017-12-18 00:01:00.000 7.56 -6.73 2.52 2.32 159.46 17.93 -99999 -99999 -99999
2017-12-18 00:02:00.000 7.72 -6.08 2.24 4.22 159.81 33.07 -99999 -99999 -99999
2017-12-18 00:03:00.000 7.68 -6.52 2.39 3.18 159.90 24.60 -99999 -99999 -99999
これを、先ほど作成したフォルダ内にコピーします
RNN、LSTM:時系列データに向いたディープラーニング
RNN(Recurrent Neural Network)は、時系列に特化した学習モデルで、「未来のデータ並びの予測」をするのに、よく使われます
中でも、LSTM(Long Short Term Memory)というRNNの一種は、従来のRNNでは学習できなかった「長期依存」を学習可能であり、短い学習時間でも精度の高い学習が可能なのが特徴です ![]()
このLSTMを使って、太陽風データを学習させ、予測させてみましょう
なお、RNNおよびLSTMは、「時系列データ」と言えば必ず出てくるほど有名なモデルで、ググれば詳しいことも容易に調べられるので、ここでの説明は省略します 以下のQiitaコラムが、とても分かりやすいと思います ![]()
わかるLSTM ~ 最近の動向と共に
https://qiita.com/t_Signull/items/21b82be280b46f467d1b
太陽風の速度をプロット
まず、元データのロードがちゃんとできているかを確認するのも含めて、プロットしてみましょう
対象となるデータは、太陽風の速度である「Speed」列にします
なお「Speed」列には、「-99999」というノイズデータが含まれているため、データロード後に除去しておきます
import pandas as pd
import matplotlib.pyplot as plt
ssv_back = pd.read_csv( 'rtsw_plot_data_back.txt', delim_whitespace=True )
ssv_back = ssv_back[ ssv_back[ 'Speed' ] != -99999 ]
data = []
for value in ssv_back[ 'Speed' ].values:
data.append( float( value ) )
plt.figure()
plt.plot( range( 0, len( data ) ), data, color = "b", label = "Speed" )
plt.legend()
plt.show()
実行します
python plot_solar_wind.py
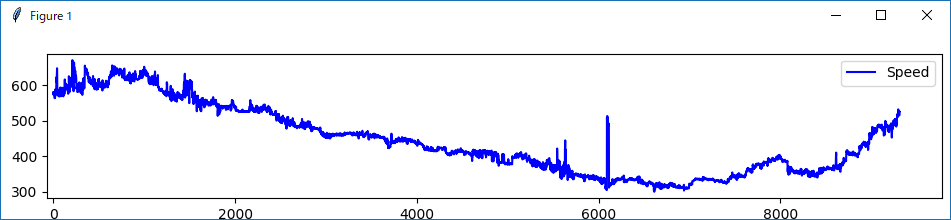
元データと比較してみましょう

同じグラフであることが確認できました ![]()
データを学習用と予測確認用に分ける
元データを、学習用8998件と、予測確認用474件の、以下2ファイルに分割します
Timestamp Bt Bx By Bz Phi Theta Dens Speed Temp
2017-12-18 00:00:00.000 7.72 -6.12 2.94 3.62 154.32 28.05 -99999 -99999 -99999
2017-12-18 00:01:00.000 7.56 -6.73 2.52 2.32 159.46 17.93 -99999 -99999 -99999
2017-12-18 00:02:00.000 7.72 -6.08 2.24 4.22 159.81 33.07 -99999 -99999 -99999
…
2017-12-24 06:23:00.000 10.49 6.20 -3.67 -7.62 329.39 -46.63 12.93 404.10 123517
2017-12-24 06:24:00.000 10.43 6.16 -3.35 -7.72 331.45 -47.75 13.25 406.20 122714
2017-12-24 06:25:00.000 10.25 5.92 -4.01 -7.32 325.89 -45.67 13.11 406.20 121549
Timestamp Bt Bx By Bz Phi Theta Dens Speed Temp
2017-12-24 06:26:00.000 10.57 6.07 -3.22 -8.01 332.05 -49.38 12.87 404.40 121963
2017-12-24 06:27:00.000 10.16 6.09 -3.82 -6.01 327.89 -39.93 12.67 403.60 123018
2017-12-24 06:28:00.000 9.64 6.24 -7.23 -0.98 310.81 -5.84 12.82 405.30 121606
…
2017-12-24 14:17:00.000 9.34 5.24 -2.01 7.39 339.05 52.80 12.56 525.40 325359
2017-12-24 14:18:00.000 9.34 5.49 -2.18 7.20 338.37 50.65 12.31 526.60 324343
2017-12-24 14:19:00.000 9.29 4.85 -0.33 7.75 356.06 57.94 12.36 526.30 325531
過去データを元に予測する
LSTM学習モデルを作成します
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers.recurrent import LSTM
from keras.optimizers import Adam
import matplotlib.pyplot as plt
ssv_back = pd.read_csv( 'rtsw_plot_data_back.txt', delim_whitespace=True )
ssv_back = ssv_back[ ssv_back[ 'Speed' ] != -99999 ]
data = []
for value in ssv_back[ 'Speed' ].values:
data.append( float( value ) )
ssv_forward = pd.read_csv( 'rtsw_plot_data_forward.txt', delim_whitespace=True )
ssv_forward = ssv_forward[ ssv_forward[ 'Speed' ] != -99999 ]
data_forward = []
for value in ssv_forward[ 'Speed' ].values:
data_forward.append( float( value ) )
def build_dataset( datas ):
input = []
expected = []
length = 20
for i in range( len( datas ) - length ):
input.append( datas[ i: i + length ] )
expected.append( datas[ i + length ] )
re_input = np.array( input ).reshape( len( input ), length, 1 )
re_expected = np.array( expected ).reshape( len( input ), 1 )
return re_input, re_expected
input, expected = build_dataset( data )
input_forward, expected_forward = build_dataset( data_forward )
length_of_sequence = input.shape[ 1 ]
in_out_neurons = 1
hidden_neurons = 300
model = Sequential()
model.add( LSTM( hidden_neurons, batch_input_shape =
( None, length_of_sequence, in_out_neurons ), return_sequences = False ) )
model.add( Dense( in_out_neurons ) )
model.add( Activation( "linear" ) )
optimizer = Adam( lr = 0.001 )
model.compile( loss = "mean_squared_error", optimizer = optimizer )
model.fit(input, expected,
batch_size = 500,
epochs = 80,
validation_split = 0.1
)
predicted = model.predict( input )
plot_data = pd.DataFrame( predicted )
plot_data.columns = [ "predicted" ]
plot_data[ "expected" ] = expected_forward
plot_data.plot()
plt.show()
早速、実行してみましょう
python predict_solar_wind.py
Using TensorFlow backend.
Epoch 1/80
3352/3352 [==============================] - 10s 3ms/step - loss: 12.8656 - val_loss: 1.7866
Epoch 2/80
3352/3352 [==============================] - 8s 2ms/step - loss: 3.0232 - val_loss: 2.6921
Epoch 3/80
3352/3352 [==============================] - 8s 2ms/step - loss: 2.1609 - val_loss: 2.9982
…
Epoch 78/80
3352/3352 [==============================] - 7s 2ms/step - loss: 0.0878 - val_loss: 0.0474
Epoch 79/80
3352/3352 [==============================] - 7s 2ms/step - loss: 0.0865 - val_loss: 0.0386
Epoch 80/80
3352/3352 [==============================] - 8s 2ms/step - loss: 0.0854 - val_loss: 0.0479
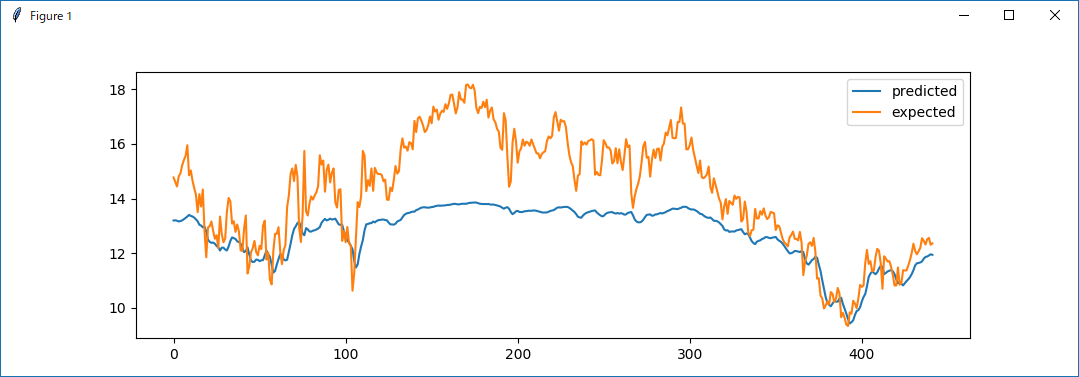
学習回数が少ないか、モデルがこなれていない影響か、完全に追従してはいませんが、アップダウンの傾向は、それなりに捉えている感じはします
もう少し時間が取れれば、チューニングで改善していく余地はあると思います
次はあなたの手元で
このような貴重なデータを手元で気軽に見れるよう、一般公開しているNOAAの心意気に感謝しつつ、「オープンデータが日常」となるような技術発展を遂げた、この時代に生きられたことは、本当に嬉しいことだと思います ![]()
「Speed」以外の項目についても、ぜひお手元にてAnacondaをインストールして、Kerasでの予測を試してみてください ![]()
機械学習とビッグデータのフロンティア、それは「宇宙」
冒頭でご紹介したような、機械学習とビッグデータを用いた宇宙データ解析の事例は、国内では割と珍しい(東大は昨年、比較的発表が多かったですが)のですが、世界レベルでは、宇宙の観測データをビッグデータと見立て、機械学習により解析する分野が、非常に熱い展開を迎えています ![]()
これは、太陽フレアのような、危機管理的な使い方だけで無く、たとえば、衛星で撮った地球の「各国・都市における光の量の増加」から、次に経済発展を遂げる国を特定し、その地域への投資活動を行ったり、より低軌道を周回する衛星から見える、広大な農地のうち、作物が良く育つ場所と、そうで無い場所を見分け、肥料の散布量を調整したりといった、ビジネスへの活用も出始めています
他にも、粒子加速器のデータ分析や、重力波の解析においても、機械学習とビッグデータのニーズは高い一方で、それを実現できる人材が圧倒的に不足しているのが現状です ![]()
機械学習やビッグデータにこれまで縁は無かったけど、小さい頃、SFやスペースコロニーに憧れて、エンジニアを目指した覚えがある方なら、簡単な宇宙データの解析から、ディープラーニングに少しずつ触れていってみるのはいかがでしょう? ![]()

---終わり---
p.s.
本記事および重力プログラミング「第2回:重力波を解析する」に連動したLT・セッションを、福岡(天神か小倉付近)で数回、登壇します
直近は、1/19(金)開催予定の「福岡理学部」のイベントとなる予定です
Twitterでアナウンスしますので、ご興味あればフォローください(Elixir/ビッグデータ分析/AI・機械学習/量子コンピュータ/技術未来予測/BLAME!についてもツィートしてます)