クロスバリデーション法を用いて精度を上げる!(4219位/11485人中)
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold
#test.csv(評価用データ)はしばらく使用しないため、ソースコードから消してあります。
df_train = pd.read_csv("train.csv")
# 欠損値を埋める
df_train["Age"] = df_train["Age"].fillna(df_train["Age"].mean())
df_train["Cabin"] = df_train["Cabin"].fillna(df_train["Cabin"].mode())
df_train["Embarked"] = df_train["Embarked"].fillna(df_train["Embarked"].mode())
# train
df_train.drop(["Name", "Ticket", "Cabin"], axis=1, inplace=True)
df_train["Sex"] = df_train["Sex"].replace({"male": 0, "female": 1})
df_train = pd.get_dummies(df_train)
train_y = df_train["Survived"]
train_x = df_train.drop("Survived", axis=1)
clf = xgb.XGBClassifier()
clf.fit(train_x, train_y)
accuracies = []
cv = StratifiedKFold(n_splits=150, shuffle=True, random_state=0)
for train_idx, test_idx in cv.split(train_x, train_y):
trn_x = train_x.iloc[train_idx]
val_x = train_x.iloc[test_idx]
trn_y = train_y.iloc[train_idx]
val_y = train_y.iloc[test_idx]
clf = xgb.XGBClassifier()
clf.fit(trn_x, trn_y)
pred_y = clf.predict(val_x)
accuracies.append(accuracy_score(val_y, pred_y))
print(np.mean(accuracies))
#出力結果
0.8047138047138048
訓練データ=過去問
検証データ=そっくり模試
テストデータ=本番入試
クロスバリデーション法とは?
訓練用データを訓練用データと検証用データの2つに分け、手元で精度を求められる方法
つまり、訓練用データ1つのみで精度を表せる画期的な方法!
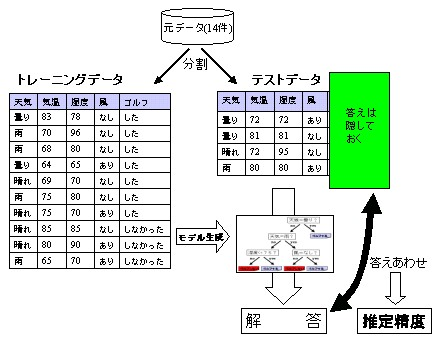
なぜクロスバリデーション法の利点とは?
今までは、[曇り,83,78,なし]→した [雨、70、96、なし]→した ....
この結果から、答えを予測するのだが、あまりにも条件を制限しすぎていることが問題となる。
つまり、テストデータがこのデータとぴったり同じであれば百発百中なのだが、実際そう厳密にぴったり同じデータになることは少ない。
しかし、クロスバリデーション法を用いると、上記の8つを訓練データ 残りの2つを検証データとすることでより汎用性の効いたclfを作ることができる!