はじめに
SEをしているフィリプスです。
MySQLを使ったことがありますが、ちゃんと理解していなかったので
、これから勉強をしながらチョコチョコメモをします。
SELECT文から
次のようなクエリがよく使われています。
select * from T where ID=10;普段MySQLターミナルやDBツールにこのSQL文を入れて、実行して結果レコードが出てきます。しかし、この間MySQLは一体どんな仕組で動いているかを知りたい。
MySQLアーキテクチャーの理解は不可欠
答えを探すため、まずMySQLのアーキテクチャーを理解しないといけないです。奥野さんのスライドに詳しく紹介されていますが、自分の理解で説明してみます。
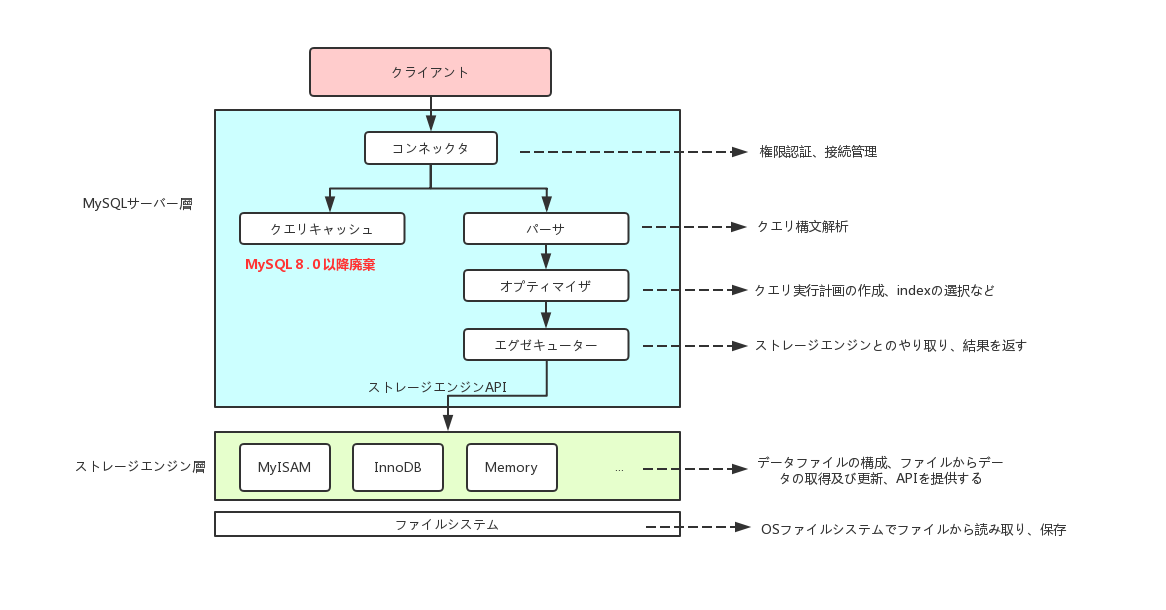
ザックリ言うと、MySQLはサーバー層とストレージエンジン層である。
サーバー層には、クエリキャッシュ、パーサ、オプティマイザ、エグゼキューターなどがあって、多数のサービス機能および組み込み関数も含めています。ストアドプロシージャー、トリガー、ビューなどな機能もサーバー層に提供されています。
ストレージエンジン層のメイン役割はデータの保存および取得です。MySQLはストレージエンジンを抜き差しできる(プラガブル)アーキテクチャである。InnoDB、MyISAMやMemoryなどのストレージエンジンをサポートしています。その中に一番使われてるのはInnoDBです。MySQL5.5.5以降、デフォルトストレージエンジンはMyISAMからInnoDBになる。ストレージエンジンに関するは後ほど整理するので、今回は飛ばします。
従って、違うストレージエンジンは同じサーバー層を共有する。話題を戻して図に基づいて今のSQL文の実行流れを見てみましょう。
コネクタ
データベースへ接続する時、最初に出迎えるのはコネクタです。コネクタはクライアントからの接続管理および権限認証を担当します。一般的に下記のようなコマンドラインで接続をします。
mysql -h$ip -P$port -u$user -pコマンドを入力すると、パスワードの入力を要求されます。
コネクタはクライアントと有名なTCPハンドシェイクにつき、入力したユーザ名とパスワードを認証します。
・ユーザ名やパスワードは無効の場合、"Access denied for user"というエラーメッセージが出てきて、クライアント側は実行終了。
・認証を通る場合、もらった権限を同じ接続に全操作に適用する。
ちなみに、認証を通過してから例え権限を変更されても、この接続に対して影響はありません。
接続を成功して、もし何もしないと、リンクはアイドル状態になります。show processlistコマンドで接続のリストを確認できます。そのまま置いて何もしなければ、時間を経って接続は自動的に切ります。経つ時間はwait_timeoutというパラメタに決めます。デフォルト値は8時間です。接続が切られてからクライアント側がリクエストをすると"Lost connection to MySQL server during query"というエラーメッセージが出てきます。もしリクエストを続けたければ、接続し直しなければなりません。
接続を立ち上がる手順は複雑し、スレッドの消滅、作成および認証などで効率に悪いので、できるだけ接続回数を控えた方がオススメです、ちなみに、同じ接続に複数リクエストで利用すること。しかし、注意すべき点があります。あんまり接続を長くにすると、メモリを食われる可能性があります。原因としてはMySQL実行中一時的なメモリは接続スレッドに保管されて、一般的に接続を切るまで解放しません。だからこんな接続を貯まるとOOM(Out Of Memory)問題を起こる可能性があります。
対策としては2つ考えられます。
①定期的に接続を切ります。ある時間を経って、あるいは大きいクエリを実行したら接続を切ります。
②MySQLのバージョンは5.7以降の場合、mysql_reset_connectionで接続リソースを初期化できます。この操作により再接続や再認証は行いません。
クエリキャッシュ(MySQL 8.0以降廃棄)
古いバージョンのMySQLはクエリキャッシュという仕組があります。SQL実行結果をクライアントに返すと同時に内容をキャッシュしておき、同一のSQLが送信された時にキャッシュされた内容をそのまま返し、メリットとしてはSQL実行を避ける事で応答速度の向上が可能。
しかし、クエリキャッシュのチェック、格納、無効化にコストがかかるため、キャッシュヒットが低いと逆に遅くなる可能性がある。テーブルに更新操作が発生するとこのテーブルのクエリキャッシュがクリアされますので、業務上アップデート操作が頻繁な場合、キャッシュヒットが極めて低くなって、クエリキャッシュ逆に負担になります。
MySQL8.0以降、クエリキャッシュは廃棄され、前のバージョンに対して、もしクエリキャッシュを使いたくなければ、query_cache_typeというパラメタをDEMANDに設定すればデフォルトでクエリキャッシュは使いません。
パーサ
クエリキャッシュをヒットしない場合、クエリの実行を始めます。パーサが登場します。パーサでは文法の誤りがないか、テーブルやフィルドが存在しているかをチェックして、問題があれば"You have an error in your SQL syntax..."というエラーメッセージが出てくる。"use near"のところに注目すれば、誤る場所が分かると思います。構文には問題がなければSQL文をコンピュータが読む命令に変換します。
オプティマイザ
パーサを通して、MySQLは既にクエリのやることを分かりました。しかし、やる方法は一つに限らないので、オプティマイザによって実行計画が立てられ、短時間でクエリが実行できるように最適化されます。複数インデックスが存在するとどっちにしようか、複数joinがあれば結合順番どうすればいいかなどを決めます。例としては
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;先にテーブル「t1」からc=10のIDを取ってからテーブル「t2」に結合して、d=20を判断してもいいし、逆にテーブル「t2」からd=20のIDを取ってからテーブル「t1」に結合して、c=10を判断しても正しい結果を捕えますが、実行効率は違います。
オプティマイザが何をしたか、具体的なロジックは後ほど整理しますので、今回は展開しません。
エグゼキューター
実行計画を立てた以上、残りは実行すること。実行役を担当するはエグゼキューターです。実行する前に、また権限認証を行います。今回は接続の権限ではなく、具体的なデータベースやテーブルにクエリ権限を持っているかをチェックします。もちろん同じような権限チェック(オプティマイザの前にprecheck)はクエリキャッシュをヒットする時も行います。もし権限チェックが失敗したら、下記のようなエラーメッセージが出てくる。
mysql> select * from T where ID=10;
ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'
チェックを成功する場合、エグゼキューターは下記の手順で実行します。
1.InnoDBストレージエンジン(デフォルトストレージエンジン)のAPIを叩いて、テーブル「T」の1行目レコードを取得して、ID=10は成立かどうかを判断します。成立しないとスキップします。成立すれば、このレコードを結果集に保存する。
2.InnoDBストレージエンジンのAPIを叩いて次の行のレコードを取得して、1と同じ判断ロジックを繰り替えしてテーブルの最後まで行います。
3.エグゼキューターはクエリ条件を満たす結果集をクライアントに返します。
インデックスがある場合、"条件を満たす1行目"や"条件を満たす次の行"というAPIを叩いてもできます。
まとめ
今回SELECT文の実行からMySQLのアーキテクチャーを覗いてみました。SELECT文の実行によりサーバー層にはコンネクタ、クエリキャッシュ、パーサ、オプティマイザ、エグゼキューターの存在及び役割を説明しました。ストレージエンジンとのやり取りはAPIを利用します。