はじめに
私はGUIの画面をポチポチしてくのが比較的好きではないです。
その為、Google Analytics(以下GA)のコンソール画面であれこれ数字を出すのにフラストレーションが溜まりまくりでした。
そこで、私が好きなPythonとJupyterでGAからデータをとってくる環境を整え、そこから分析やABの結果出しまでワンストップで行えるようにしました。
Jupyter Notebookならコードの実行とMarkdownによる考察等の記録もできるのでどんな分析をしたのかが残って便利です。
例えばこんな感じ。
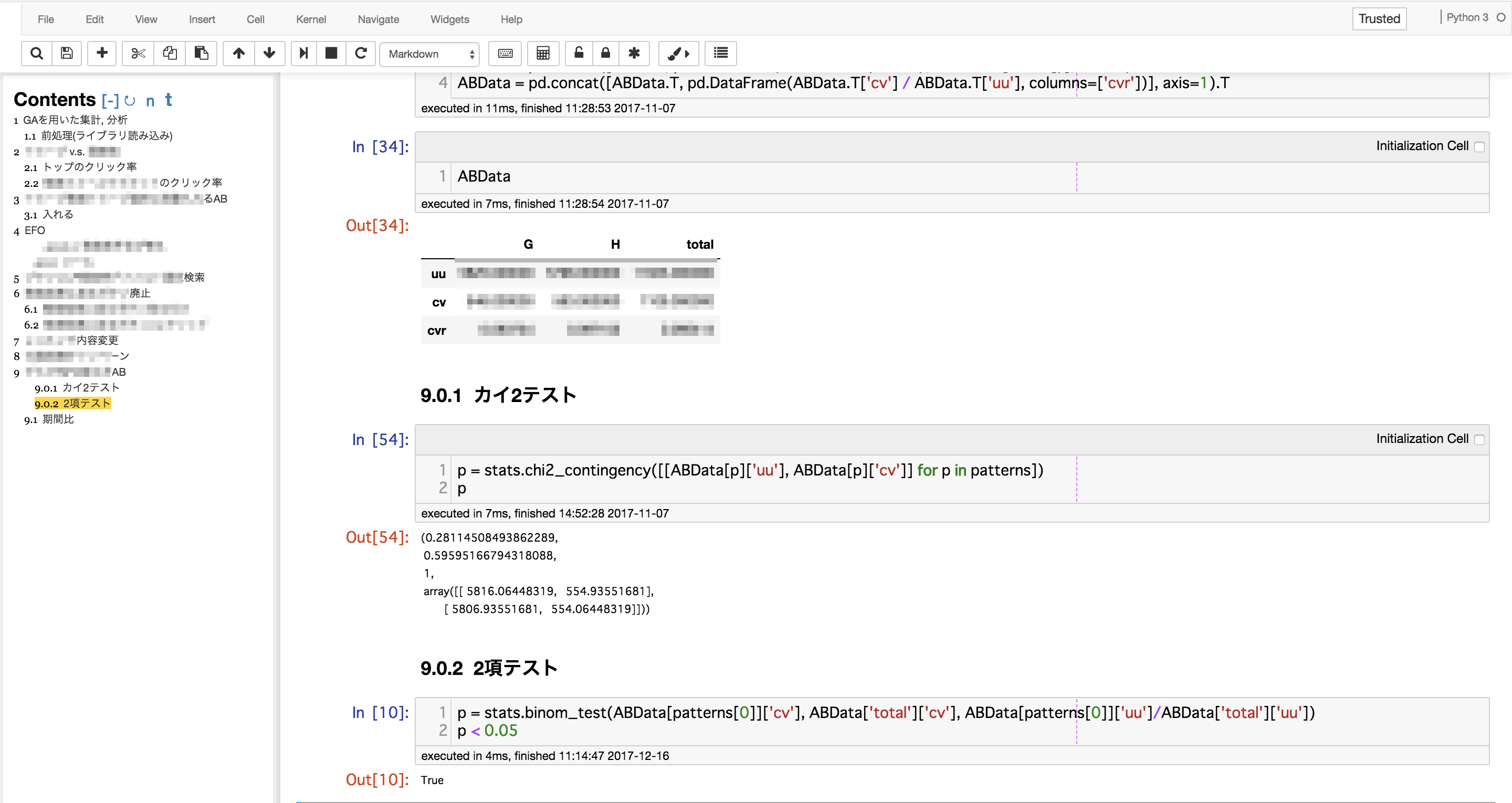
いい感じですね。
環境構築
Python環境の用意
macの場合はbrewに pyenvがあります。
$ brew install pyenv
その他の環境ではリポジトリをクローンしてきましょう。
$ git clone https://github.com/pyenv/pyenv
あとはpyenvにパスを通しましょう。
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile
$ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile
次にAnacondaをインストールします。
これを入れておけば必要なJupyterや数値計算に必要なモジュールが入っています。
最新のAnacondaのバージョンを確認します。
$ pyenv install --list | grep anaconda | tail
インスト-ルします。
$ pyenv install anaconda3-5.0.0
インストール完了したらPythonバージョンを切り替えてJupyterを起動します。
$ pyenv global anaconda3-5.0.0
$ jupyter notebook
shut down all kernels (twice to skip confirmation).
[C 20:26:51.081 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8889/?token=925d951d434ea26b063141beaa06a0815f9fa51950c04cc8
みたいな感じで出るのでURLをブラウザにコピペしてアクセスします。
最初はファイル一覧の画面がでます。$ jupyter notebook [パス]になるのでパス無しだとカレントディレクトリを見ます。
Google DriveやDropbox等のクラウドストレージのパスを指定すると、別の端末からも操作できて便利なのでおすすめです。(機密情報の取扱いには注意)
GAのAPIを使う準備
システムで使うにはAPIを使います&キーが必要になります。
また、サンプルが様々な言語で用意されているのでそれを使うとスムーズです。
Pythonのクイックスタートをみて準備を進めましょう。
GAのAPI許可
サービスアカウントの作成を。サービスカウントのページから行います。
プロジェクトが選択されていなければ選択、なければ作成をします。
サービスアカウント作成時に「新しい秘密鍵の提供」を選択し「キーのタイプ」は「p12」を選択します。
これで作成するとキーファイルがダウンロードされます。(後ほど利用)
モジュールのインストールとサンプルのダウンロード
モジュールをインストールします。
$ pip install --upgrade google-api-python-client
APIアクセスが楽になるサンプルコードをダウンロードしてきます。
ステップ 3: サンプルを設定するにあるコードをコピーしてファイルに貼り付けて保存するか、ダウンロードしてきます。
Notebookを作成するディレクトリに配置しておきましょう。
実際に使う
準備用のセル
モジュールのインポートやAPI情報を指定しておきます。
# サンプルファイルを読み込む
import HelloAnalytics as HA
# この辺は分析用に使うもの
import pandas as pd
from collections import OrderedDict
import datetime
from scipy import stats
import numpy as np
scope = ['https://www.googleapis.com/auth/analytics.readonly'] # データとってくるだけのときはこれだけでOK
service_account_email = SERVICE_ACCOUNT_EMAIL # 自分のサービスアカウントEmail(~gserviceaccount.com)
key_file_location = 'path/to/key.p12' # ダウンロードしてきた自分のキーファイルをおいたパス
service = HA.get_service('analytics', 'v3', scope, key_file_location, service_account_email)
profile = HA.get_first_profile_id(service)
これでGAをJupyterでゴニョゴニョする準備ができましたね。
各種紹介
指定ページの流入元
このLPはどこからの流入が多いのだろう?
page = 'path/to/page'
res = service.data().ga().get(
ids='ga:' + profile,
start_date=(datetime.date.today() - datetime.timedelta(days=29)).__str__(),
end_date=(datetime.date.today() - datetime.timedelta(days=1)).__str__(),
metrics='ga:users',
dimensions='ga:date,ga:source',
filters="ga:pagePath=~{0}".format(page) # =~ は正規表現の一致を含む になります。これが使い勝手が良い。
).execute()
uu_df = pd.DataFrame(res['rows'])
uu = uu_df.pivot(index=0, columns=1, values=2).fillna(0).astype(int)
| 1 | 流入元A | 流入元B | 流入元C | 流入元D |
|---|---|---|---|---|
| 0 | ||||
| 20171117 | 400 | 340 | 890 | 610 |
| 20171118 | 480 | 310 | 900 | 590 |
| 20171119 | 520 | 330 | 1020 | 640 |
| 20171120 | 500 | 350 | 800 | 670 |
| 20171121 | 440 | 290 | 7000 | 680 |
のようになります。
指定ページの前のページ
どこから遷移してくるのだろう?
page = "path/to/page"
res = service.data().ga().get(
ids='ga:' + profile,
start_date=(datetime.date.today() - datetime.timedelta(days=8)).__str__(),
end_date=(datetime.date.today() - datetime.timedelta(days=1)).__str__(),
metrics='ga:users',
dimensions='ga:date,ga:previousPagePath',
filters="ga:pagePath=~{0}".format(page)
).execute()
uu = res['rows']
uu_df = pd.DataFrame(res['rows'])
uu = uu_df.pivot(index=0, columns=1, values=2).fillna(0).astype(int)
| 1 | prePage1 | prePage1 | prePage1 | prePage1 |
|---|---|---|---|---|
| 0 | ||||
| 20171208 | 123 | 234 | 345 | 456 |
| 20171209 | 123 | 234 | 345 | 456 |
| 20171210 | 123 | 234 | 345 | 456 |
| 20171211 | 123 | 234 | 345 | 456 |
uu.plot(legend=False)
とやると
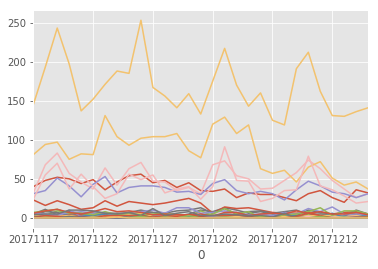
かんたんにグラフ出力ができます。
ABの結果を見る
ページや開始日とかの設定する。
start_date = '2017-12-01' # ABテスト開始日
patterns = ['A', 'B']
data = {p: dict() for p in patterns}
page = "path/to/test/page"
cv_page = "path/to/cv/page"
まずABそれぞれのUU取得。
for p in patterns:
res = service.data().ga().get(
ids='ga:' + profile,
start_date=start_date, # 指定した開始日から
end_date=(datetime.date.today() - datetime.timedelta(days=1)).__str__(), # 今日まで
metrics='ga:users',
segment='users::sequence::ga:pagePath=~{0}'.format(page),
filters="ga:<ABテスト用のディメンジョンとか>=~/{0}/".format(p)
).execute()
data[p]['uu'] = int(res['rows'][0][0])
次にABそれぞれのCV数を取得。
s
for p in patterns:
res = service.data().ga().get(
ids='ga:' + profile,
start_date=start_date,
end_date=(datetime.date.today() - datetime.timedelta(days=1)).__str__(),
metrics='ga:users',
segment='users::sequence::ga:pagePath=~{0};->>ga:pagePath=~{1}'.format(page, cv_page),
filters="ga:<ABテスト用のディメンジョンとか>=~/{0}/".format(p)
).execute()
data[p]['cv'] = int(res['rows'][0][0])
pandasのデータフレームに落とし込みます。
patternData = [pd.DataFrame(list(data[p].values()), index=data[p].keys(), columns=[p]) for p in patterns]
ABData = pd.concat(patternData, axis=1)
ABData = pd.concat([ABData, pd.DataFrame(ABData.sum(axis=1), columns=['total'])], axis=1)
ABData = pd.concat([ABData.T, pd.DataFrame(ABData.T['cv'] / ABData.T['uu'], columns=['cvr'])], axis=1).T
| / | G | H | total |
|---|---|---|---|
| uu | 10000 | 10000 | 20000 |
| cv | 500 | 700 | 1200 |
| cvr | 0.05 | 0.07 | 0.06 |
みたいなかんじになります。
scipyのstatsを使って有意差を確認します。
p = stats.binom_test(ABData[patterns[0]]['cv'], ABData['total']['cv'], ABData[patterns[0]]['uu']/ABData['total']['uu'])
p < 0.05 # True
で、Markdownセルに考察を書けばもうレポートの完成。
HTMLで吐き出したり、LaTeXも入れればPDFではいたりもできます。(拡張機能ではスライドも作れます。)
おわりに
GAのWEB版も高機能で素敵ですがJupyterNotebookを使えばPythonとともに様々インタラクティブに分析しながら数値を見れます。
是非Jupyter+Python+GAで楽しくサイト改善をしていきましょう。