はじめに
こんにちは、もんすんです!
Advent Calendar 2024のテスト自動化導入の時の話 by T-DASH Advent Calendar 2024の2日目の記事をお届けします!
さて、レガシーシステムでの開発において、「品質の維持」と 「スピードの向上」 は常に相反する課題ですね。(急に)
私は、レガシーシステムの保守や改修を行うことが多く、いつもこのような課題を感じているエンジニア人生を歩んできました。
時々、品質を維持すれば、スピードも上がるという話を聞きますが、これは、ある一定以上の品質水準を満たして、やっとそう言った状態になるのではないかと感じます。
逆に低品質なシステムにおいては、その状態を維持しても開発スピードは上がりません。
さて、レガシーなシステムでは、手動テストやリリースに多くの時間が割かれ、肝心の新機能開発が停滞してしまう状況に悩まされているチームは少なくありません。
今回は、過去にそんな課題に直面した私のチームが、テスト自動化を通じてどのように状況を改善し、成功に繋げたのか、そのプロセスを具体的に共有していこうと思います。
同じ課題に直面している方にとって、テスト自動化導入を考える上での一助となればと思います。
プロジェクト背景:変革前の現実
私たちの取り組みは、典型的なレガシーシステムから始まりました。
このシステムは長年にわたり維持されてきましたが、急速に変化するビジネス要求に対応するには、さまざまな制約が足かせとなっていました。
以下は、当時のプロジェクトの状況と直面していた課題です。
レガシーシステムの状況(当時)
-
技術基盤
- システムはJavaのバージョン8で構築されていました。
- 数年前にオンプレミスからAWS EC2へ移行しましたが、その過程でクラウドネイティブな設計思想は採用されていませんでした。
- 使用しているフレームワークはSpring Boot 2.x.xで、一部のコンポーネントは古い設計がそのまま残っていました。
-
テストやCI/CDの不在
- テストコードは一切存在せず、(なんなら基本設計すら無し)動作確認はすべて手動で行われていました。
- デプロイは深夜の作業が常態化し、メンバーに大きな負担がかかっていました。
- 継続的インテグレーションやデプロイ(CI/CD)の仕組みはなく、毎回のリリース時に手動でAWSコンソール上で作業を行う必要がありました。
直面していた課題
-
システム改修のリスク
- 手動テストに頼る環境では、ちょっとした修正であっても他の機能への影響を把握するのが困難でした。リリースも大きなバグがない限りは、1ヶ月か2ヶ月に一度というルールになっていました
- 修正ミスやリグレッション(既存機能の不具合再発)が頻発しており、リリース後のバグ対応が開発チームの大きな負担となっていました
-
品質保証プロセスの非効率性
- 機能の動作確認は、エンジニアが手作業で実施しており、時間と労力がかかる一方で、ヒューマンエラーも発生しやすい状態でした
- テスト不足により、リリース直後にユーザーから障害報告を受けることは当然何度かありました
-
開発スピードの停滞
- 手動テストや夜間デプロイに時間が割り当てられる分、開発チームは新機能の実装に対する工数を効率よく確保できませんでした。
- チームのモチベーションも低下し、「根本的な問題を解決しないまま日々の作業をこなす」状態が続いていました。
私のチームはシステムを根本的に改善し、持続可能な開発体制を構築する必要性を感じていました。
その第一歩として選んだのがテスト自動化の導入です。
テスト自動化導入のステップと挑戦
テスト自動化を導入するにあたり、私たちは段階的に取り組むことを重視しました。
ステップ1: 最初の一歩 - JUnitの導入
最初に着手したのは、テストコードを記述する文化をチーム内に根付かせることでした。
具体的なアクション
- プロジェクトの依存管理ツールであるGradleに、テストフレームワークとしてJUnitを導入
- 書きやすい範囲、つまり単体でテストが可能な機能から正常系テストコードを作成
- 各メンバーに対して、テストコードの記述方法を学ぶ小さなワークショップを実施
取り組みのポイント
- 初期段階では、テストコードの量や網羅性よりも「書き始めること」にフォーカス
- 書いたコードを共有し、チーム全員が「テストを書く」ことに慣れる環境・習慣を整備
- プルリクのレビューでは、まずテストコードがあるかを確認
ステップ2: CIの構築 - GitHub Actionsでの自動テスト実行
次に、テストを効率よく実行する仕組みを整えるため、継続的インテグレーション(CI)ツールとしてGitHub Actionsを導入しました。
具体的なアクション
- プルリクエストを作成すると、自動的にJUnitで記述したテストが実行されるワークフローを設定
- チーム全体でプルリクエスト単位のテスト結果を確認し、品質を意識する習慣を作成
取り組みのポイント
- 設定の複雑さを避け、最低限のフローからスタート
- 具体的には、テストが失敗した場合に通知を受けるだけの簡易的な仕組みから始め、徐々に拡張
ステップ3: テストカバレッジの可視化 - JaCoCoの導入
テストコードの量が増えてきたタイミングで、カバレッジ(テスト対象のコードの割合)を測定するためのツールとしてJaCoCoを導入しました。
具体的なアクション
- GradleタスクにJaCoCoの設定を追加し、テスト実行時にカバレッジを自動測定
- 測定結果をAWSのS3にアップロードし、静的ホスティングすることで、チーム全員がテスト結果をいつでも確認できる仕組みを構築
取り組みのポイント
- JaCoCoの結果を見える化することで、どの部分のテストが不足しているかを直感的に把握
- チームメンバーがカバレッジを基にテストの対象範囲を議論する機会を増やし、コード品質に対する意識を向上
ここまでで、gradle.buildでは以下のような設定を追加したりしました。
plugins {
id 'org.springframework.boot' version '2.1.6.RELEASE'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id 'java'
id 'jacoco'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
// JUnit Jupiter (JUnit 5)
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testImplementation 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
// JUnit Platform Commons
testImplementation 'org.junit.platform:junit-platform-commons:1.8.1'
testImplementation 'org.junit.platform:junit-platform-engine:1.8.1'
// JUnit Platform Launcher (for launching tests)
testRuntimeOnly 'org.junit.platform:junit-platform-launcher:1.8.1'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.mockito', module: 'mockito-core'
}
testImplementation 'org.mockito:mockito-core:3.12.4'
testImplementation 'org.mockito:mockito-inline:3.12.4'
}
jacoco {
toolVersion = "0.8.10" // JaCoCo のバージョンを指定
}
test {
useJUnitPlatform()
finalizedBy jacocoTestReport // テスト終了後にレポート生成を実行
}
jacocoTestReport {
dependsOn test // テストが実行された後にレポートを生成
reports {
xml.required = true
html.required = true
}
}
プロジェクトの情報を省き簡略化したものが、以下のGHAのワークフローファイルになります。
以下のyamlファイルは、フローをわかりやすくするため、基本的な情報のみに省略しております。
このままでは正しく動作しないので、もしプロジェクトで利用する際は気をつけてください。
name: Running Test Workflow
jobs:
test:
runs-on: ubuntu-latest
steps:
# 1. Gitリポジトリをチェックアウト
- name: Checkout code
uses: actions/checkout@v3
# 2. Java環境をセットアップ
- name: Set up JDK
uses: actions/setup-java@v3
with:
java-version: '8'
distribution: 'temurin'
# 3. Gradle Wrapperを使ってテストを実行
- name: Run tests
run: ./gradlew clean test
# 4. テスト結果を保存
- name: Upload test results
if: always()
uses: actions/upload-artifact@v3
with:
name: test-results
path: build/reports/jacoco/test/html
最後にS3にアップされ、静的ホスティングしているページがこんな感じです。
もちろんプロジェクト情報は載せず、記事用に実装したソースコードに対するテスト結果ですが、正しく出力されました。

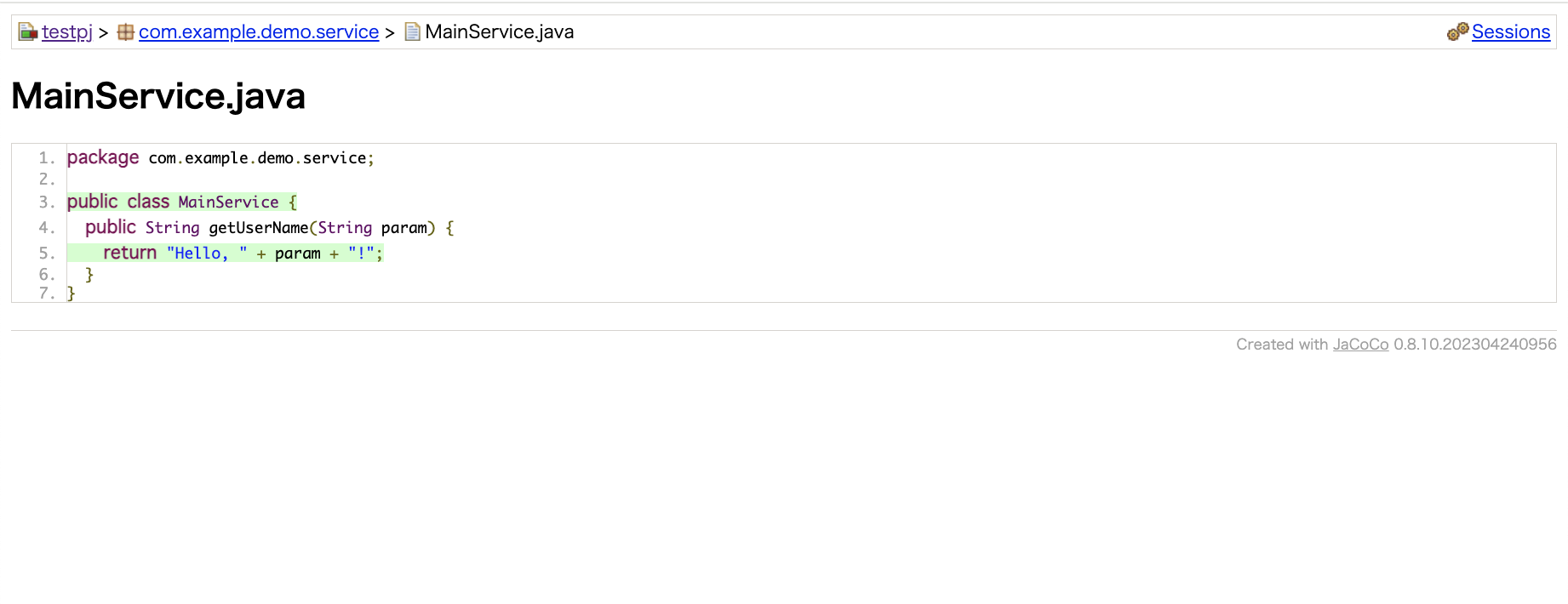
これらのステップを踏むことで、システム全体に少しずつテストコードが追加され、効率的なテスト実行とカバレッジの可視化を実現することができました。
導入の成功を支えた鍵
テスト自動化の導入は技術的な取り組みだけでなく、上層部の理解を得ることやチーム全体を巻き込むことが重要な要素です。
このプロジェクトが成功した背景には、いくつかの工夫がありました。
ここでは、上層部を説得した方法とチームメンバーを動かしたポイントについて紹介します。
上層部の説得:価値を伝えるための具体例と戦略
テスト自動化の導入には初期コストや学習コストが伴います。
そのため、経営陣や運用チームから「なぜテスト自動化が必要なのか」という質問にしっかり答えることが求められました。
アプローチ1: ビジネスインパクトを具体的に提示
- 過去に発生したリリース後の障害対応やバグ修正のコストを数値化し、「手動テストに依存している現状のリスクと非効率性」を可視化
- 「自動化することで障害率が低下し、結果的にリリースサイクルが短縮できる」という、ビジネスへの直接的なメリットを具体的に説明
アプローチ2: 小さな成功事例を積み重ねて信頼を得る
- 初期段階で導入したテスト自動化が、特定のリグレッションバグを防止した例を報告
- 実績を積むことで、運用チームの「本当に効果があるのか?」という疑念を払拭
アプローチ3: 言語を「ビジネス側」に合わせる
- 「テストカバレッジ」や「CI/CD」という技術的な用語を避け、代わりに「品質保証」「迅速なリリース」などのビジネスサイドが理解しやすい言葉で説明
- ROI(投資対効果)の概念を用い、長期的な視点での利益を強調
実際のところ、一番響いたのは、アプローチ2でした。
最も障害の発生する箇所に関してのテストコードを書くことで、障害率が低下したことで、チームとしての信頼を獲得できました。
このおかげで、アプローチ1にあるようなインパクトの説明における説得力にもつながりました。
逆にアプローチ3にあるようなものは、あまりビジネスサイドを理解できていないと、適切ではない行動になっていた可能性があります。
特にROIについては、あまり私自身、正しい説明ができていたか怪しいですし、むしろ逆効果になっていた可能性もあるので、要注意なアプローチな気がします。
チームの巻き込み:全員参加型の文化づくり
テスト自動化を成功させるには、開発メンバー全員が自分事として取り組む必要があります。
以下の取り組みが、チームのモチベーション向上や協力体制の構築に役立ちました。
成功ポイント1: 負担を分散し、小さな成功を共有
最初は一部のメンバーで取り組み、成功事例を全体開発MTGで共有しました。
「実際に役立つ」と感じたメンバーが次第に増加しました。
テストコードを書く範囲を「簡単な部分から」「正常系のみ」「全員で少しずつ」としたことで、大きな心理的負担を軽減することができました。
成功ポイント2: フィードバックの文化を醸成
プルリクレビュー時にテストコードも確認するルールを設定しました。
これにより、テストを書くことがチーム全体に浸透しました。
成果を定期的に可視化し、カバレッジ率や検出したバグ数を共有してチーム全員が改善を実感できる仕組みを作成しました。
成功ポイント3: 技術的支援を提供
テストコードの記述が未経験のメンバー向けに、小さめのワークショップやテスト記述例の共有を実施しました。
JaCoCoやGitHub Actionsの設定に詳しいメンバーが、他のメンバーをサポートする形でペアプロやモブプロの時間を設け、技術的・心理的ハードルを下げることができました。
成功ポイント4: 継続的なモチベーション維持
カバレッジ率が向上したり、リリース後の障害が減少したりした成果を定期的に振り返る習慣を徐々に導入していきました。
会社の定期的な個人目標の設定・振り返りを通じて、個々の貢献を明確に評価し、モチベーションを高められないかも次のステップとして進められないかも考えていました。
(私がチームにいる間に実現することはできませんでした。)
いいことだけじゃない。「失敗話」
テスト自動化は多くのメリットをもたらしましたが、導入の過程では当然ながら失敗や課題もありました。
成功を語る上で、これらの困難をどのように乗り越えたかも、ここで共有しようと思います。。。
失敗1: テストの優先順位設定が難航
一番初めに、開発チーム内で、テストを書く範囲を決める際、どこから手をつけるべきか意見が分かれました。
一部のメンバーは単体テスト(UT)に、別のメンバーは結合テストやE2Eテストに重点を置くべきという意見のぶつかり合いがあり、議論が長引くことがありました。
学び
-
焦点を絞ることの重要性
すべてをカバーしようとせず、「まずは正常系」「特に障害が発生しやすい箇所」に限定したことで議論が収束しました -
全員が納得する基準を作る
「ユーザーに影響を与える可能性が高い部分」を基準に、テスト対象の優先順位を設定するルールを明確化しました
失敗2: テストコードの品質にばらつきが発生
初期段階では、メンバーのスキルや経験値の差により、テストコードの書き方にばらつきが出ました。
テストに精通しているメンバーが書いたコードは理解しやすくメンテナンス性が高い一方、人によっては、コードが複雑で意図が読み取れないこともありました。
学び
-
ベストプラクティスの共有
テストコードの書き方についてチームでガイドラインを策定し、コードレビューを通じて品質を一定水準以上に保つ仕組みを構築することが大切 -
知識の共有
テストを書く際に「これが正解」と言える具体例を用意し、新規メンバーでも迷わないようなサンプル集があるとよかったかもしれません
失敗3: 上層部への費用対効果説明の難航
導入初期、上層部から「テスト自動化にリソースを割くより、新機能開発を優先すべきでは?」と反対されることがありました。
費用対効果を適切に説明できず、チーム全体の士気に影響を与えた期間もありました。
学び
-
データで語ることの重要性
テスト自動化が障害対応時間を削減し、開発効率を向上させた具体例をデータで示すことで、反対意見を徐々に払拭しました -
短期と長期の利益を両方伝える
短期的には障害減少、長期的にはリリース頻度の増加というメリットを提示し、経営陣に納得してもらう形を目指しました
失敗4: 作業負担の偏り
初期段階では、特定のメンバーが自動化作業を主導しており、他のメンバーが後追いでサポートする形にならざるを得ませんでした。
結果として一部の人に作業が集中し、疲弊を招くことになりました。
学び
-
役割分担の明確化
チーム内で役割分担を明確にし、「知識を持つ人が独り占めしない」仕組みを整備することでうまくいくことができました -
段階的な巻き込み
まずは少人数で試行し、得られた知見を全員に共有する機会を設けたり、NotionなどでWiki化したりすることで作業負担を軽減しました。
これらの失敗は、プロジェクト全体を改善するための貴重な教訓となりました。
大切なのは、失敗そのものを恐れず、それをチーム全体で学びに変えていく姿勢だなと感じました。
この経験があったからこそ、私たちはテスト自動化をチーム全員の文化として根付かせることができました。
今後の展開
テスト自動化を導入したことで、品質や開発スピードの向上といった成果を得ることができました。
しかし、それに満足せず、さらなる改善と進化を目指していくのが大切です。
テスト導入時点で見えていた課題や今後の目標を整理し、次なるステップをご紹介します。
1. 異常系テストのカバー率向上
この記事の内容においては、テストは正常系に重点を置いています。
そのため、カバレッジはまだまだなので、異常系や例外処理のテストカバレッジを向上させることが課題です。
やりたいこと
- 例外が適切に処理されていることを確認するUTの追加
- ユーザー入力エラーやネットワーク障害など、現実的な障害シナリオを再現するテストの拡充
具体的アプローチ
- 現在のログデータや
New Relicなどに出力されるデータを分析し、よく発生する問題を特定する。 - モックツールを活用し、異常系テストシナリオを効率的に作成していく。
2. 統合テストやE2Eテストの展開
単体テストの導入は進んでいますが、システム全体の動作を保証する統合テストやE2Eテストの導入も重要なので、やっていきたいです。
やりたいこと
- ユーザーの実際の操作を模したシナリオの自動化による、リリース前のリグレッションチェックの強化
具体的アプローチ
- Seleniumを用いたE2Eテストの追加
- フロントエンドからバックエンド、データベースまでを含む統合テストの拡充
- E2Eテストは実行時間が長いため、主要なシナリオに絞ること
3. デプロイフローのさらなる改善
本記事の内容においては、テスト自動化の範囲内に留まっていますが、デプロイフロー全体の最適化も必要と考えています。
やりたいこと
- テスト結果を元にした自動的なデプロイ判定の導入とそれによる開発サイクルの高速化
- 本番環境へのリリースの夜間や週末における実施を止め、業務時間内でも安心して実施できる仕組みの構築
具体的アプローチ - GHAもしくはAWS CodeBuildにデプロイのパイプラインを追加し、自動テスト成功時にステージング環境へデプロイの実施
- カナリアリリースやBlue-Greenデプロイメントを活用した安全な本番環境更新の実現
4. そのほか
上記以外の内容や具体的アプローチがまだ見えていないことは以下の通りです。
これでもまだまだ足りないかも。
やりたいこと
- テスト自動化に関するスキルや知識を、全てのチームメンバーが最低限身につけるられる環境を構築する。
- テストデータ管理ツールを用いて、テストシナリオに適したデータセットを容易に生成・管理する。
- Dockerを用いることで環境をコンテナ化し、統一化する。
-
Mutation Testの導入によるテストのテストを実施する。
最後に
今回は、レガシーシステムの品質向上と開発スピードの向上を目指して、私と私のチームが取り組んだテスト自動化の導入プロセスをまとめてみました。
「成功の鍵」としては、 以下の2点が一番大きかったかなと思います。
- 上層部の理解を得るために具体的なメリットを示して、小さな成功事例を積み重ねて信頼を得たこと
- 継続的にチーム全員を巻き込む文化づくりや技術的支援を行ったこと
正直、継続化することは骨が折れます。
テストコードを書くことが習慣化されていないメンバーにとっては、結構面倒だったという話もありました。
そういったメンバーを気遣いながらも、途中でやめない気持ちで続けていくことが大切だなと感じました。
テスト自動化の導入は決して簡単ではありませんが、取り組むことで得られるメリットは非常に大きいと実感しています。
同じ課題に直面している方々の参考になれば幸いです!