本記事はサムザップ #1 Advent Calendar 2019の12/18の記事です。
サムザップではSREエンジニアとして、新規プロジェクトのインフラを設計・構築したり、社内横断として技術の標準化などを進めてます。
はじめに
現在自分が携わっているゲームアプリでは、AWSが提供するサービスを多く用いています。
中でも、マネージドサービス(ここではインスタンスの管理を自身で行わないという意味で使用)を多く用いた構成をとっており、インスタンスやその中で動いているミドルウェアの監視など、運用におけるマネージメントコストをできるだけ下げることを狙った設計を行っています。
逆に言うと、従来インスタンス運用で行っていたSSHなどで中に入って色々いじくる!みたいなことができないので、構築して挙動が確認できても、今までのような試験方法ができなかったりします。
ここでは、その中でも先日行ったアーキテクチャにおける障害試験のお話をできればと思います。
構成
今回使用するアーキテクチャを以下の図に示します。
これで全てではないですが、アプリケーションの挙動に直接関わりそうなところを一部抜粋で表示してます。
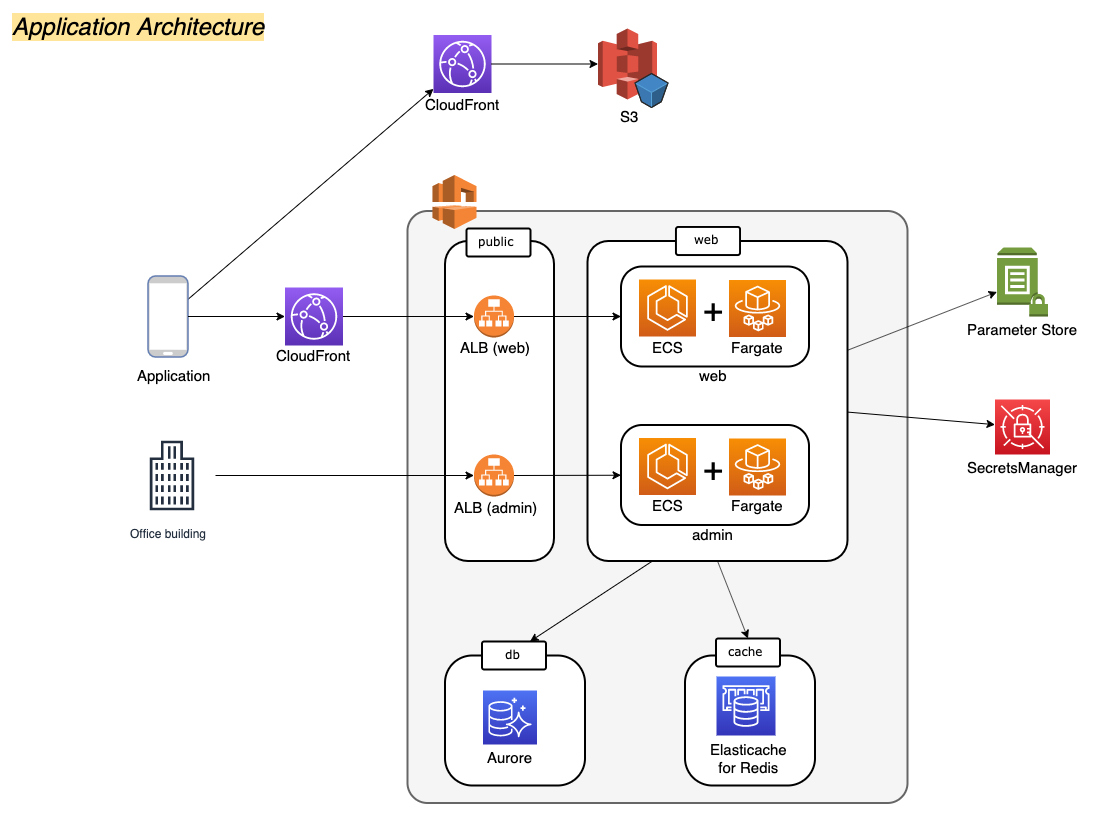
アーキテクチャとしては至ってシンプルです。
- PublicなサブネットにALBを配置。
- WEB API用のサブネットにはECS Fargateを配置してAPIサーバを構築。
- 運営側管理用サーバも同様にECS Fargateを使用して構築。
- DB用サブネットにはAuroraを配置。
- cache用サブネットにはElasticache for Redisを配置。
- DBの接続情報をSecrets Managerに格納。APIサーバから取得して内部でキャッシュ。
- Redisの接続情報はSystem Manager Parameter Storeに格納。APIサーバから取得して内部でキャッシュ。
- アプリケーションで扱う静的ファイル群はS3に格納し、CloudFrontをCDNとして前段に配置。
- ELBの前段にDDoS対策の一環でCloudFrontを配置。
障害試験
構築したアーキテクチャに対して、わざとサーバやミドルウェアを落としたり、ネットワーク上つながらないようにして障害を起こします。
今回はマネージドサービスを多く使用するので、障害の起こし方は、直接というよりかは擬似的なものが多くなります。
準備
障害試験を実施する前にもちろん準備が必要です。
準備は大きく以下の2つのことを行いました。
1. 試験実施準備完了定義
障害試験を実施するために必要な項目も洗い出し、すべての項目をクリアにして初めて、障害試験実施可能になるということを定義しました。
| 項目 | 担当分掌 (client/backend) |
|---|---|
| アプリケーションからAPIにリクエストを送り、意図するレスポンスが返ってくる | client, backend |
| 障害試験を行うための隔離された環境が用意されている | backend |
| API用ソースのデプロイがいつでもできる | backend |
| 管理用ソースのデプロイがいつでもできる | backend |
| webview用ソースのデプロイがいつでもできる | backend |
| LBのターゲットがHEALTH状態である | backend |
| DBクラスタのフェイルオーバを実行することができる | backend |
| サーバ稼働におけるログやメトリクスがいつでも閲覧できる | backend |
| 監視系統が全て稼働してる | backend |
| アラート系統が全て稼働している | backend |
| アプリケーションのビルドをいつでも行うことができる | client |
| アセットバンドルをいつでも適切なものに更新することができる | client |
| コードフリーズの期日が決まっている | client |
| サーバにSSHログインして調査することができる | backend |
| 試験で発覚したバグを修正するためのフローや期間が確立されている | client, backend |
| 障害試験のためのアプリがインストールされた端末が用意できている | client |
2. 試験項目の準備と想定挙動の記載
障害時は、システムにとってどういう状態になるかということを把握し、それに合った対処法を理解しておくことが肝心です。
各サービスなどにおいて、障害が起きた際にどういう挙動になるかという想定を一つずつ記載できるようにフォーマット化しました。
- 対象システム
- 対象のサービス名やシステム名。
- 手順
- 障害を起こすための手順。
- 想定挙動
- 障害時にアプリケーションがどのような挙動になるか、またインフラ的にはどういう状態になっているのか。
- 実際の挙動
- 試験の実施をした結果、どのような挙動になったのか。
このフォーマットに従って、試験項目を事前に記載した上で、実際の障害試験に臨みました。
試験実施
項目が多いので一部抜粋し、また実際の挙動などは省いて記載します。
APIサーバ
観点としては、主にスケールイン・アウトや1サーバだけが落ちた状態、APIサーバが全く機能していない状態を想定しています。
| 対象システム | 手順 | 想定挙動 |
|---|---|---|
| ECS Fargate | 負荷をかけた状態でタスク必要数を 増減させる。 |
【アプリ挙動】 アプリ影響なし。 【インフラ状態】 負荷を捌けるだけのタスク数があれば問題なし |
| ECS Fargate | タスクを一つ停止させる。 | 【アプリ挙動】 アプリ影響なし 【インフラ状態】 数分後停止したタスクの代わりのタスクが起動する |
| ECS Fargate | 必要タスク数を0にする | 【アプリ挙動】 HTTPステータスコード503が返る 【インフラ状態】 APIサーバが存在しない状態 緊急アラートが飛ぶ |
データベース
データベースは主にAuroraを使用しているので、writerとreaderのインスタンスそれぞれに対して障害を起こすように試験を進めました。
データベースの障害試験時はクラスタやインスタンスの起動・停止が頻繁に発生するので、余裕をもった試験時間の確保も必要になりました。
| 対象システム | 手順 | 想定挙動 |
|---|---|---|
| Aurora (writer) |
インスタンスを停止させる。 ▼コマンド mysql> ALTER SYSTEM CRASH;
|
【アプリ挙動】 readerインスタンスが昇格するまでHTTPステータスコード503が返る。 【インフラ状態】 フェイルオーバーが発生し、readerのインスタンスが昇格する。 |
| Aurora (reader) |
インスタンスを停止させる。 ▼コマンド mysql> ALTER SYSTEM CRASH;
|
【アプリ挙動】 問題なし。 【インフラ状態】 リードレプリカのインスタンスが停止状態。 |
| Aurora クラスタ |
負荷をかけている間に意図的にフェイルオーバを実行する。 | 【アプリ挙動】 readerインスタンスが昇格するまでHTTPステータスコード503が返る。 【インフラ状態】 readerインスタンスがwriterに昇格する状態。 |
| Aurora クラスタ |
クラスタを停止させる。 | 【アプリ挙動】 HTTPステータスコード503が返る。 【インフラ状態】 DBに全くアクセスできない状態。 |
キャッシュサーバ
キャッシュサーバとしては、主にElasticache for RedisをクラスタモードOFFで使用しています。
当アプリケーションでは、プライマリとレプリカのエンドポイントを特に区別せず、Redisシャードの設定エンドポイントを指定して接続しています。
ElasticacheはAuroraなどと違い、ノードを停止させる機能はないので、接続できない状態を作り上げるには、
ノードを削除するか接続するエンドポイントを変更するかになってくるのですが、今回は後者を選択しました。
また、クラスタモードOFFなので、今回はスケールイン・アウトのテストは省略しました。
| 対象システム | 手順 | 想定挙動 |
|---|---|---|
| Ealstaicache | 接続できない状態にする <方法> パラメータストアの値を変更し、 その後デプロイを行う。 |
【アプリ挙動】 HTTPステータスコード503が返る。 【インフラ状態】 APIサーバからはRedisへの接続ができない状態。 |
| Ealstaicache | フェールオーバーを実行する | 【アプリ挙動】 レプリカノードが昇格するまで HTTPステータスコード503が返る。 【インフラ状態】 一時的にRedisのプライマリーノードへの 接続ができない状態。 |
| Ealstaicache | ノードタイプを変更する。 | 【アプリ挙動】 新しいノードタイプのノードが起動するまで、 HTTPステータスコード503が返る。 【インフラ状態】 Redisを一時的にデストロイするので、 新たに立ち上がってくるまでは Redisへ接続できない状態。 |
このキャッシュサーバの障害試験を実施して初めて知ったのですが、Elasticacheのスケールアップ・ダウンはオンラインでできるので、アプリケーションに影響が発生しませんでした。
こういうところに気付けるのも障害試験のいいところですね。
その他
その他、マネージドサービスで用いた各種機能です。中でもこちらで作成したVPCにとらわれないパブリックなサービスです。
これらに対して障害を擬似的に起こすには、接続できない状態を作り上げることしかできません。
| 対象システム | 手順 | 想定挙動 |
|---|---|---|
| Secrets Manager (DB接続情報) |
シークレット参照できない状態にする。 <方法> 参照するシークレットIDの名前を変更 |
【アプリ挙動】 HTTPステータスコード503が返る。 【インフラ状態】 APIサーバからSecrets Managerへ 接続できない状態。 |
| System Manager Parameter Store (Redis接続情報) |
パラメータ参照できない状態にする。 <方法> 参照するパラメータの名前を変更 |
【アプリ挙動】 HTTPステータスコード503が返る。 【インフラ状態】 APIサーバからParameter Storeへ 接続できない状態。 |
| CloudWatch Logs (ログ格納先) |
擬似的に接続できない状態にする <方法> 存在しないロググループ指定してデプロイする。 |
【アプリ挙動】 HTTPステータスコード503が返る。 【インフラ状態】 タスクで指定しているロググループが 存在しない状態。 |
実際に試験を実施して改めてわかったことなのですが、当アプリケーションのデプロイフロー内では、DBマイグレーションやECSのタスク定義の更新など、これらに何かしらの接続が行くようになっているので、デプロイが途中で失敗してしまいます。
現時点で稼働しているAPIサーバではすでに正常な接続情報やログ出力先などがコンテナ内にキャッシュされた状態で稼働しているので、今回上記の試験ではデプロイフローの試験としては確認できたのですが、稼働中のシステムに対する障害試験にはなりませんでした。
今後の改善点としては、現構成で稼働中システムに対する試験をするために、外部から意図的にコンテナ内キャッシュをクリアする機構が別途必要になってきます。
まとめ
マネージドサービスを使用すれば、こちらの運用コストを減少させることが可能ですが、こちらでハンドリングできる部分も少なくなります。
今回紹介した障害試験の項目はごく一部なのですが、他にもS3やCodePipelineなどマネージドサービスを使用した部分はたくさんあり、それごとに擬似的な障害の起こし方などを考える必要があります。
また、実際に想定した挙動とは全く別の挙動が発生することも多々あり、それらはなぜ想定挙動と違うのかを深掘る作業も必要です。
AWSに限らず、マイクロサービス化がどんどん進むと、フルマネージドなサービスがどんどん増えていくと思うのですが、自身が手掛けるアプリケーションにはどの部分にどのようなウィークポイントを持っているかを把握するために障害試験は不可欠だと思いますので、マネージドだからと疎かにせずに、一つずつしっかり検証していきたいですね。
明日は @shimizu_toshihiko さんの記事です。