参考記事
http://yu0105teshi.hateblo.jp/entry/2016/08/03/180603
https://qiita.com/masaki7555/items/d65f56958020cbca5ee0
この記事の内容を使っているサイト:薬価計算medipra
この記事で紹介すること
行数が多いCSVファイルをコマンドで分割する方法
CSVファイルを使ってDBにデータを入れる
行数が多いCSVファイルをコマンドで分割する方法
ではまずCSVの準備をします。
CSVファイルの準備
必要なCSVファイルを用意します。
今回は医薬品データベースを使用します。
ここから、「全件分ファイル」をダウンロードすると、約21,000行あるCSVファイルが手に入ります。
ターミナルを開いてCSVファイルをダウンロードしたディレクトリに移動しましょう。
そこで wc -l [ファイル名] を実行すると、指定したファイルの行数がカウントされます。

ちなみにwcコマンドの主なオプションは以下の通りです。
| 短いオプション | 長いオプション | 意味 |
|---|---|---|
| -c | --bytes | バイト数の表示 |
| -m | --chars | 文字数の表示 |
| -l | --lines | 改行の数を表示 |
| -w | --words | 単語数を表示 |
CSVファイルの分割split
それでは次にダウンロードしたCSVファイルを分割します。
そもそもなぜ分割するのかというと、
今回の場合は、使ってるherokuのAdd-onの設定によります。
今、薬価計算サイトmedipraで使用しているclearDB MySQLの有料プランが**Punch($9.99)**で、
1時間当たり18,000のクエリしか受け付けないためです。
なので、ダウンロードしたファイルをそのままDBに流し込もうとすると、クエリが足りなくなりエラーとなってしまいます。
たまに更新するDBのためにより上の有料プランを契約するのも、ランニングコストが増えるので初めの段階では不要ですよね。
また、CSVを1行流し込むのにクエリが3回飛ぶようなので、6,000行以下でファイルを分割します(今回は余裕を持って5,900行で分割してます)
さて、分割してみましょう。
分割コマンドは$ split -l [行数] [分割するファイル] [分割したファイルの接頭辞] で、行数を指定して分割できます。

赤い下線の--additional -suffix=.csvのところは、分割後のファイルの拡張子をCSVにしたくて付け足したのですが、デフォルトでマックに入っているのではこのオプションは使えないようです。
というわけで次のコマンドで分割。
$ split -l 5900 y_ALL20200825.csv medipra-
このコマンドで
medipra-aa, medipra-ab, medipra-ac, medipra-adの4つのファイルができました。
今回はcsvファイルにしたいので、名前の変更で.csvにすればCSVファイルとして使えるようになります。
分割後のCSVファイルが文字化けしていたら
分割後にVSCodeで開いてみると文字化けしていることがあります。
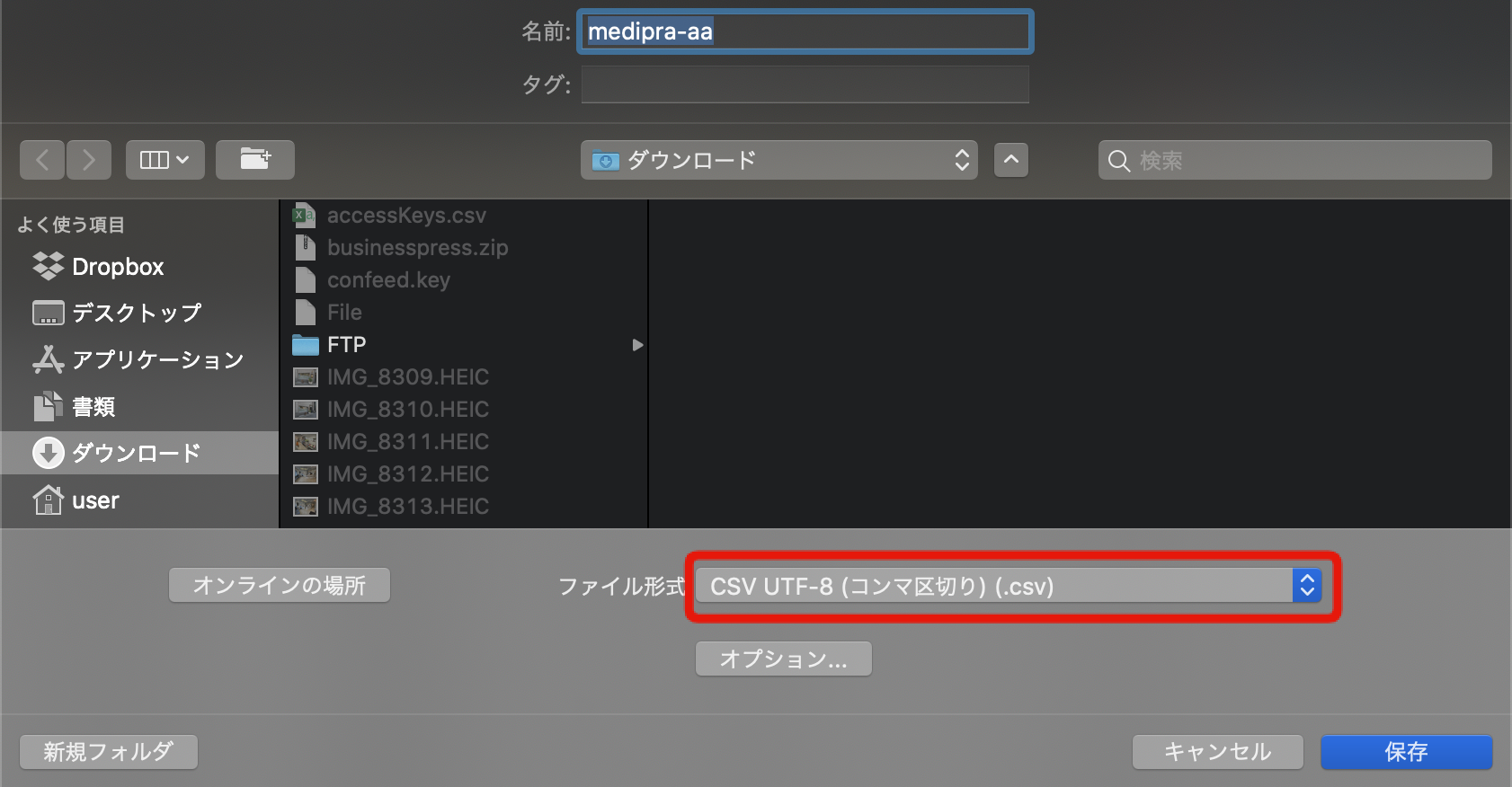
そんな時はExcelで開いて**「名前をつけて保存」をクリックして、
ファイル形式をCSV UTF-8**と文字コードを指定して保存してみましょう。
CSVファイルを使ってDBにデータを入れる
大まかな解説
ファイル構造は以下のようになります。
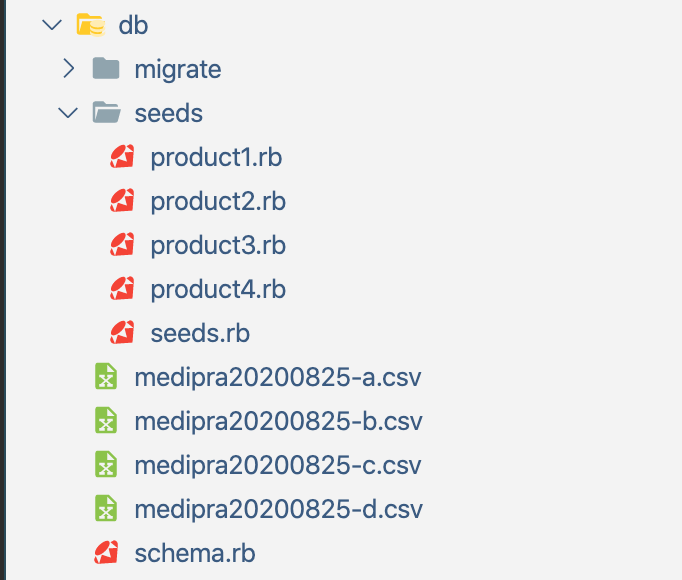
(seeds.rbは不要ファイルなので気にしないでください)
dbディレクトリの直下にCSVファイルをおき、これらをseeds>product1.rbでDBに流し込みます。
先に、今回使うコマンドはこちら。(herokuの環境を想定しています)
$ heroku login
$ heroku run bundle exec rake db:migrate:reset
$ heroku run bundle exec rake db:seed:product1
db:migrate:resetについてはこちらを参照してください。
参考記事:rake db:reset と rake db:migrate:reset の違い
seeds>product1.rbの準備
今回は、多量のCSVのデータを複数に分けて流すのでseedファイルを必要な分作ります。
今回なら、CSVファイルが4つありますので4つのseedが必要になります。
seedsディレクトリを作って、そのしたのディレクトリにファイルを作ります。
例えば以下のようにファイルを作ります。
require "csv"
date = "2020-04-01"
i = 1
CSV.foreach('db/medipra20200825-a.csv') do |info|
Product.create!(
price: info[11],
change_category: info[0],
master_type: info[1],
pharmaceutical_code: info[2],
・・・中略・・・
expiration_date: info[33],
standard_name: info[34]
)
end
db/medipra20200825-a.csvの部分をそれぞれファイル名を変えてproduct1.rb~product4.rbまで作ります。
こちらも参考にどうぞ
【Rails】rake seedコマンドでCSVファイルからDBに読み込ませる方法
seedコマンドでDBに流し込む
seedファイルを用意したら、コマンドで流し込みます。
まずherokuにログイン
$ heroku login
続いて、前の古いDBがあるならresetします
$ heroku run bundle exec rake db:migrate:reset
これで最新のマイグレーションファイルのDBが作り直すことができます。
最後にseedを実行。
product1~4まであるので、4回実行することになります。
$ heroku run bundle exec rake db:seed:product1
クエリが1時間当たり18,000までなので、
1回このコマンドをやったら、1時間開けて~:product2に変更して、
再度コマンドを実行します。
若干手間ではありますが、これ以上課金するのもまだもったいないので。(費用対効果、大事ね)
以上で完成です。
間違いのご指摘などありましたらご教示いただけましたら幸いですm(__)m
それでは今回は以上です。
最後までありがとうございます。
この記事の内容を使っているサイト:薬価計算medipra