こんにちは、齋藤です。
今回は、Python3とscikit-learnを用いたシンプルな機械学習のサンプルコードを紹介します。
今回のサンプルでは、Irisデータセットを用いて以下の2点を行います。
- 全特徴量を使用したロジスティック回帰による分類と正解率の評価
- 可視化のため、最初の2特徴量のみを用いて決定境界をプロット
1. はじめに
機械学習では、データからパターンを学習し、未知のデータに対して予測や分類を行います。
Irisデータセットは、機械学習入門用の定番データセットです。
今回のサンプルコードでは、全4次元の特徴量を使って分類モデルを構築し、
さらに視覚的に理解しやすいよう、最初の2特徴量に着目した決定境界のプロットも行います。
2. 環境準備
以下のライブラリがインストールされていることを確認してください。
- Python 3.x
- numpy
- scikit-learn
- matplotlib
必要なライブラリは、以下のコマンドでインストールできます。
pip install numpy scikit-learn matplotlib
以下の記事でPython3の機械学習に用いるライブラリに関して説明をしています。
3. サンプルコード
以下のコードは、Irisデータセットを用いてモデルの学習および評価、そして可視化(決定境界の表示)を行う例です。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# === Part 1: 全ての特徴量を用いた学習 ===
# Irisデータセットの読み込み
iris = datasets.load_iris()
X = iris.data # 特徴量(4次元)
y = iris.target # ラベル
# データセットをトレーニング (80%) とテスト (20%) に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ロジスティック回帰モデルの作成と学習
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# テストデータに対する予測と正解率の出力
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("全特徴量使用時のテスト正解率:", accuracy)
# === Part 2: 最初の2特徴量を用いた可視化 ===
# 可視化のため、最初の2特徴量のみを使用
X_vis = X[:, :2]
X_train_vis, X_test_vis, y_train_vis, y_test_vis = train_test_split(X_vis, y, test_size=0.2, random_state=42)
# 2特徴量を用いたロジスティック回帰モデルの作成と学習
model_vis = LogisticRegression(max_iter=200)
model_vis.fit(X_train_vis, y_train_vis)
# 特徴空間上のメッシュグリッドの作成
x_min, x_max = X_vis[:, 0].min() - 1, X_vis[:, 0].max() + 1
y_min, y_max = X_vis[:, 1].min() - 1, X_vis[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200),
np.linspace(y_min, y_max, 200))
# メッシュグリッド上での予測を実行し、決定領域を求める
Z = model_vis.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 決定境界とテストサンプルのプロット
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X_test_vis[:, 0], X_test_vis[:, 1], c=y_test_vis, edgecolor='k', cmap=plt.cm.Paired)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title("Decision Boundary (First Two Features)")
plt.show()
4. コードの解説
Part 1: 全特徴量を用いた学習と評価
-
データの読み込みと分割
datasets.load_iris()によりIrisデータセットを読み込み、全4次元の特徴量をX、ラベルをyに格納しています。その後、train_test_split()を使い、80%をトレーニングデータ、20%をテストデータに分割しています。 -
モデルの作成と学習
LogisticRegression(max_iter=200)でロジスティック回帰モデルを作成し、model.fit()によりトレーニングデータで学習を行います。 -
予測と評価
学習済みモデルでテストデータのラベルをpredict()し、accuracy_score()を使って正解率を算出。コンソールに正解率が表示されます。
Part 2: 可視化(決定境界のプロット)
-
特徴量の選択
可視化のため、元の4次元データから最初の2特徴量のみを抽出し、X_visとして利用します。同様にデータを分割して、モデルmodel_visを作成・学習します。 -
メッシュグリッドの作成
2次元平面上の各点に対して予測を行うため、np.meshgridを用いてグリッドを作成します。xxとyyは各軸の範囲をカバーする配列です。 -
決定境界の予測とプロット
作成したグリッドに対して、model_vis.predict()で予測を実行し、その結果をZに格納。plt.contourfで決定領域を色分けして表示し、テストデータを散布図として重ね合わせることで、学習済みモデルの決定境界を以下の図のように視覚的に確認できます。
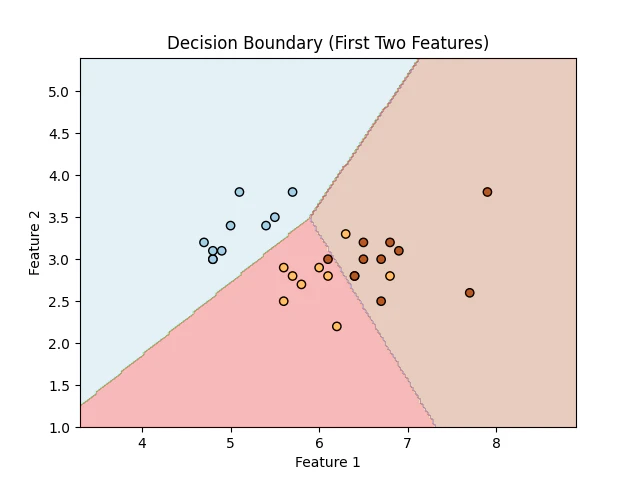
5. まとめ
本記事では、Python3とscikit-learnを使用してIrisデータセットによるロジスティック回帰モデルの学習と評価、そして可視化(決定境界のプロット)を行うサンプルコードを紹介しました。
このコードを基に、他のアルゴリズムやデータセットにもチャレンジしてみてください。