はじめに
時系列分析を学習するために「時系列分析と状態空間モデルの基礎」を購入したが、普段業務では専らPythonを使うので、できれば全編通してPythonで学習したい。
【RでやるべきことをPythonでやるシリーズ】と題して、上記本の実装例をPythonで実装し直すのに詰まった部分を備忘録に残す。
目的
- 第2部7章「RによるARIMAモデル」より、Rのパッケージ
forcastにはARIMAモデルの次数p,q,rの次数を最適化するための関数auto.arimaが存在する。 - Pythonの時系列分析パッケージとしては
statsmodelsが有名だが、上記関数に相当する機能はない。 - 前例を探すと次数をGridsearchするFor文を書いて実行するコードが散見される。何とかして楽な書き方をしたいので、この処理をラップしたパッケージを探したい。
参考
For文でARIMAモデルの次数決定を行う例が記載
解決方法
-
statsmodelsをラップしたパッケージpmdarimaを採用する。auto.arima関数に相当する関数が提供されている。
実装例
# インストール
# !pip install pmdarima
# パッケージダウンロード
import datetime
import pandas as pd
import pmdarima as pm
import statsmodels.tsa.api as tsa
import statsmodels.api as sm
# trainデータの準備
# ~~省略~~
# モデルの定義
auto_arima = pm.auto_arima(
y=train['front'],
X=train[['PetrolPrice', 'law']],
# stepwise=False,
seasonal=True,
max_order = 5,
m = 12,
approximation = False,
information_criterion='aic')
# 実行
auto_arima.summary()
結果
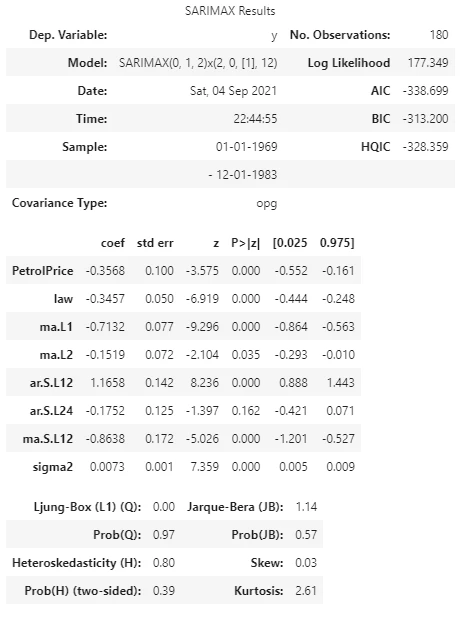
補足
- trainデータセットは下記のようなデータを保持する

- 季節性(Seasonal)及び外生変数(eXogenous)を定義しているため、正確にはSARIMAXモデルの次数決定をしている。
- パラメータ
mは季節性の周期、ここでは12(月)を指定している。 - パラメータ
max_orderは$SARIMA(p,d,q)(P, D, Q)$における$p+q+P+Q$の最大値を指定する。大きくするとより複雑なモデルを候補にモデル選択を行う。 - その他のパラメータは公式リファレンスを参照されたい。
おわりに
今後はRDatasetのPythonでの参照方法や、pystanの実行方法などを整理する予定。
参考資料