ネット画像の分類 をやってみた
インターネット上の画像に関連する情報から、画像が広告かどうかを予測するモデルを作成にチャレンジしてみた。
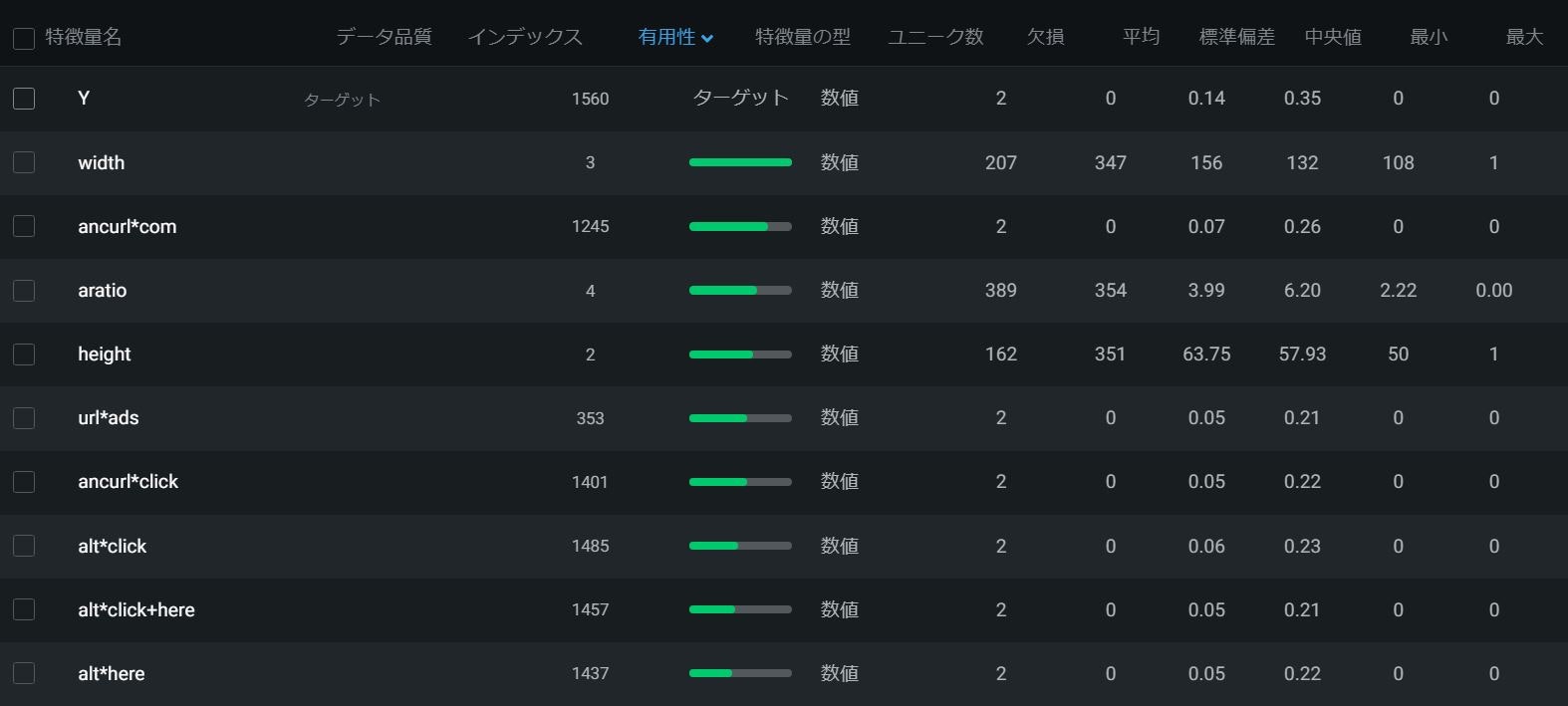
データ概要
課題種別:分類
データ種別:多変量
学習データサンプル数:1639
説明変数の数:1558
欠損値:あり
今回は特徴量が多いです。内容は省きます。1560の特徴量処理方法はどうなってしまうのか!
モデル作成はじめました。 現在は有効特徴量約64%で計算
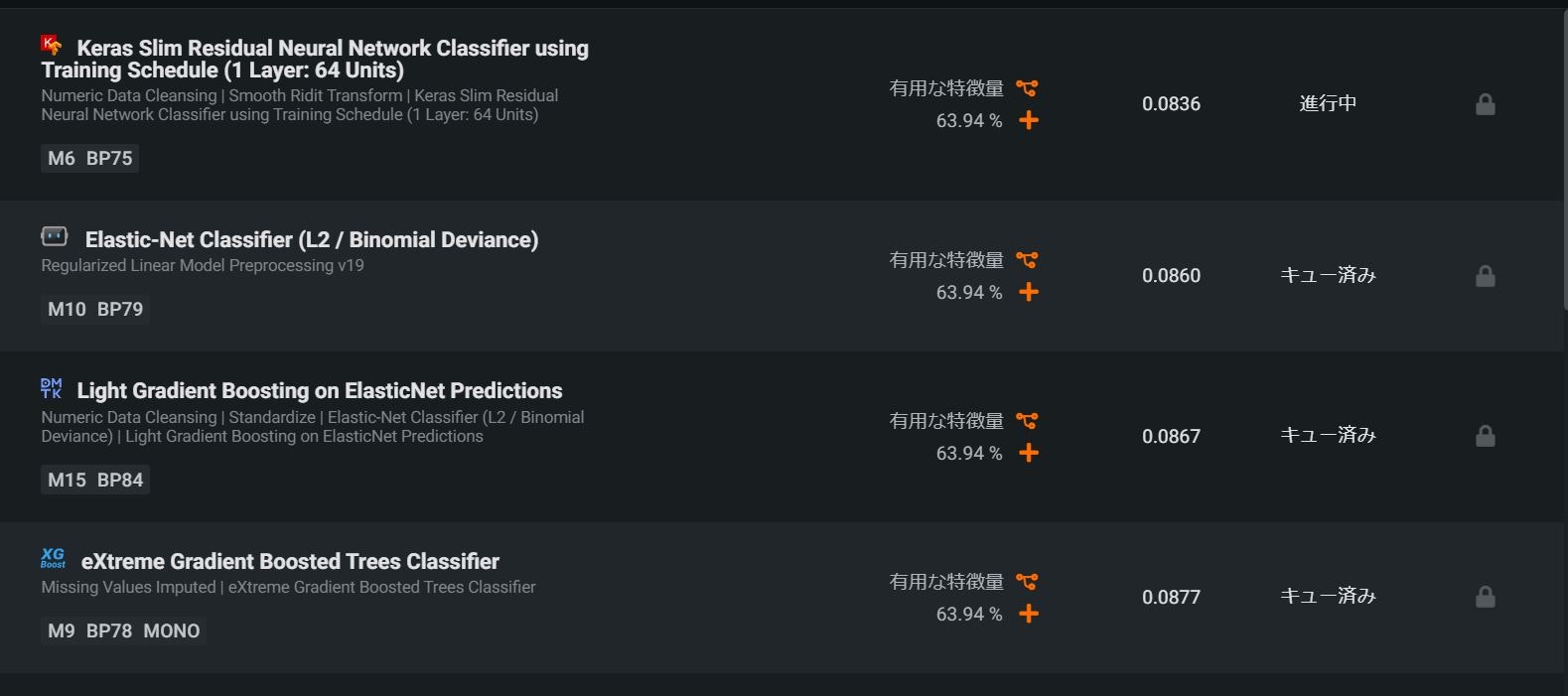
分析項目が流石に多かったので冗長な特徴量の除外を行う。
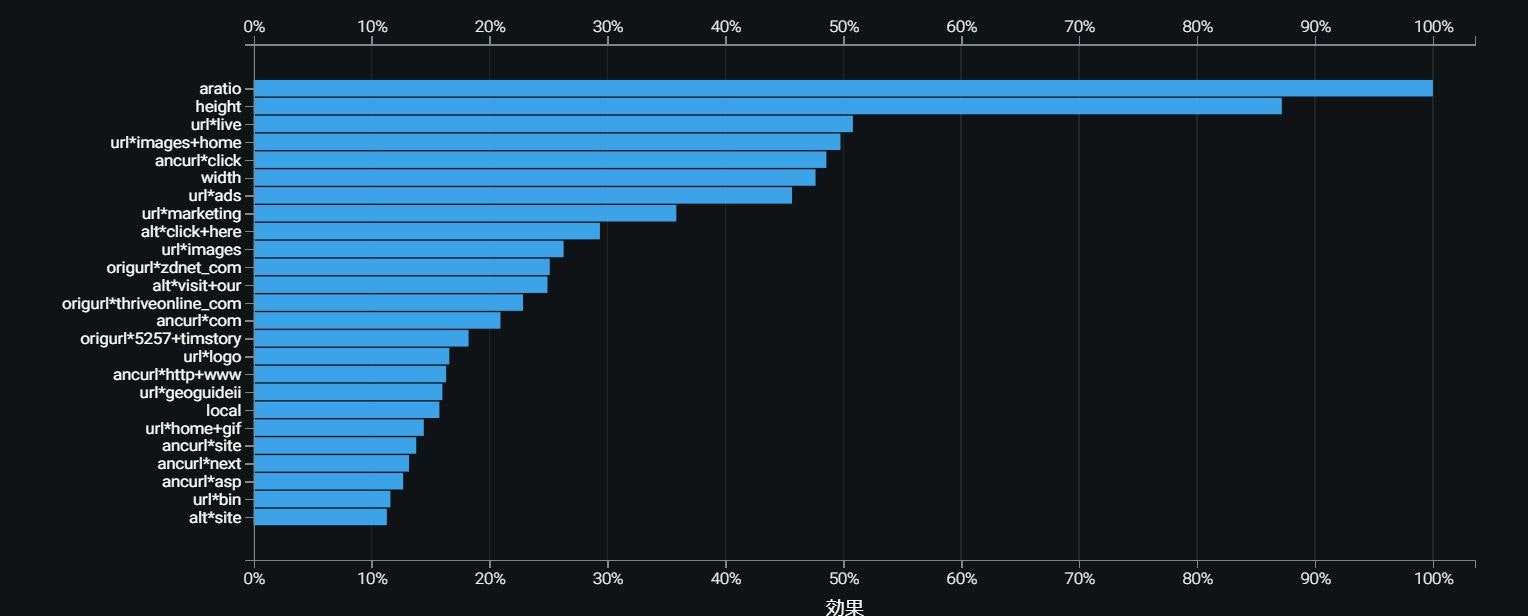
特徴量2を作成 BEST20より
備忘として 特徴量インパクトと特徴量ニューセット
モデルの特徴量のインパクトを実行する
冗長な特徴量が識別された後、冗長な特徴量を除外した新しい特徴量セットを作成できます。オプションとして、ユーザー指定のトップNの特徴量を含む新しい特徴量セットを作成する
再計算中 06:30 20200723
DataRobot 解説より引用 特徴量インパクトについて
特徴量のインパクトスコアを理解する
特徴量のインパクトを理解する方法の1つは、次のようなものです。任意列に対する特徴量のインパクトは、DataRobotがその列をランダムにシャッフルして(他の列は変更せずに)予測をした場合、モデルのパフォーマンスがどれだけ悪化するかの指標です。DataRobotは、スコアを正規化し、最重要列の値が1になるようにします。この手法は、Permutation Importance(置換重要性)と呼ばれることがあります。
特徴量のインパクトスコアを評価する際は、以下の点に注意してください。
特徴量のインパクトは、モデルのトレーニングデータの最大2500行を使用して計算されます。
時折、データに含まれるランダムノイズが原因で、負の特徴量のインパクトスコアを含む特徴量がある場合があります。極度にアンバランスなデータでは、大部分が負の値となる場合があります。
プロジェクト指標は計算で使用されるので、プロジェクト指標の選択によっては、 特徴量のインパクトの結果に大きな影響が生じることがあります。AUCなど、一部の指標はモデル出力において小さい変更に対する真陽性率が低いので、特徴量の変化がモデルの精度にどれだけ影響するかを評価するには最適ではありません。
いくつかの条件の下では、モデリングに使用するアルゴリズムの関数が原因で特徴量のインパクトの結果が変わることがあります。これは、例えば、類似する強力な信号が多く存在するデータの場合(同じケースと行に対して同じ予測値が提供される場合)などに発生します。そのような場合、L1ペナルティを使用するアルゴリズム(いくつかの線形モデルなど)の場合、インパクトは1つの信号に集中しますし、木の場合は相関する複数の信号にわたって均一に分散されます。
--
--200723 06:41 オリンピックが本当なら--