はじめに
本記事は、Lambda関数のコールドスタートについて調査検証した内容のまとめとなっています。
AWS Lambdaは、サーバーレスアーキテクチャの中核として多くのシステムで採用されており、高速なスケーリングや柔軟なトリガーとの連携が魅力です。しかし、応答速度が重要なAPIや、レイテンシがユーザー体験やシステム全体のパフォーマンスに影響を及ぼすシステムにおいては、「コールドスタート」に注意する必要があります。
このコールドスタートはなぜ発生するのか?そして、どのようにすれば回避・軽減できるのか?について調べて検証してみたので、備忘録がてらまとめてみようと思います。
コールドスタートとは
コールドスタートとは、Lambda関数が初めて呼び出される場合や、しばらくの間利用されていなかった関数が再び呼び出される際に発生する処理ステップのことです。
Lambda関数は、呼び出されてから処理が完了するまでに以下のようなステップで処理が進行します。
-
Lambda APIが呼び出される
イベントトリガー(API Gateway, S3, Event Bridgeなど)または手動実行により、Lambda関数が呼び出されます。 -
コードのダウンロード
関数コードは Amazon S3(ZIPパッケージ)または Amazon ECR(コンテナイメージ)から取得されます。 -
実行環境の構築
指定されたメモリサイズ・ランタイム・環境変数などに基づいて、分離された実行環境が構築されます。 -
初期化処理の実行
関数のコードファイルのうち、ハンドラー関数の外で記述された処理が実行されます。
例:ライブラリの読み込み、大量データのロード、DB接続の初期化など -
ハンドラー関数の実行
イベントデータがハンドラーに渡され、関数のビジネスロジックが実行されます。
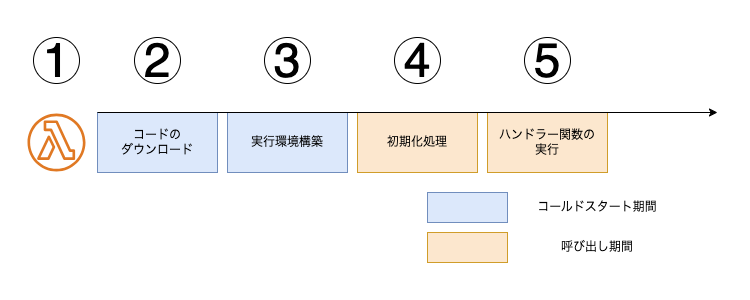
上記プロセスにおけるステップ2および3(コードのダウンロードと実行環境の構築)は、コールドスタートと呼ばれます。コールドスタート中の処理は課金対象外ではあるものの、応答速度が重要なアプリケーションにおいては大きなボトルネックとなる可能性があります。
なお、Lambda関数には、処理が完了した実行環境を一定時間保持する仕組みがあり、既存の環境を再利用して実行される2回目以降の呼び出しは、ウォームスタートと呼ばれています。ウォームスタートの場合、初期化処理が不要となり、より高速なレスポンスが実現できます。
コールドスタート、ウォームスタートについて簡単にまとめると、以下のようになります。
- Lambdaは、コードのダウンロード→実行環境の構築→初期化→実行というプロセスを経て動作する
- コールドスタートとは、Lambda関数が初めて呼び出される場合や、しばらくの間利用されていなかった場合に発生する実行環境を構築するプロセスのこと
- コールドスタート中の処理は課金対象外だがレスポンス遅延の原因になる
- ウォームスタートとは、既存の環境を再利用したLambda関数を実行すること
- ウォームスタートでは、初期化プロセスが省略されるため、高速な処理が可能になる
コールドスタートが何か分かったところで、次はLambdaが既存環境を保持する仕組みについても調べてみました。
Lambdaの実行環境のライフサイクル
Lambdaの実行環境には、関数の初期化から終了までの間にいくつかのフェーズが存在します。
初期化フェーズ(Init Phase)
初期化フェーズは、実行環境の構築直後に実行され、以下のタスクを実行します。
- すべての拡張機能を起動(Extension Init)
- 関数のランタイムをbootstrapする(Runtime Init)
- ハンドラー外の関数コードを実行(Function Init)
初期化フェーズは通常10秒以内で完了する必要があります。 完了しなければ、後続の呼び出しフェーズでも初期化フェーズの処理が再試行されます。
なお、この10秒という制限はすべてのLambda関数で固定の値で、関数に設定できるタイムアウト値とは別です。ただし、以下の場合は最大15分間まで実行可能です。
- プロビジョニングされた同時実行を有効にしている
- SnapStartを有効にしている
復元フェーズ(Restore Phase)※SnapStart専用
復元フェーズはSnapStartが有効な場合のみ発生します。
初回実行時またはスケールアウト時に、事前に保存されたのスナップショットから実行環境を復元します。
呼び出しフェーズ(Invoke Phase)
このフェーズでは、Lambda関数のハンドラーが実行されます。
関数本体の処理に加え、拡張機能のすべての処理もこのフェーズに完了する必要があり、関数のタイムアウト設定値(最大900秒) 以内に収める必要があります。このフェーズの所用時間は、すべての呼び出し時間(ランタイム実行時間 + 拡張機能)の合計として計測されます。
シャットダウンフェーズ(Shutdown Phase)
実行環境が不要になったとき発生する終了処理フェーズです。このフェーズでは、登録されている拡張機能に対してShutdownイベントが通知されます。シャットダウンにかけられる時間は、登録されている拡張機能の種類に応じて異なります。
- 0ms : 登録された拡張機能を持たない関数
- 500ms : 登録された内部拡張機能を持つ関数
- 2000ms : 登録された外部拡張機能を 1 つ以上持つ関数
実行環境の再利用
関数および拡張機能の実行が完了した後、Lambdaは実行環境を即座に破棄せず、一定期間フリーズ状態で保持します。次回同じ関数が呼び出された場合、この環境が再利用されることで、次のようなメリットがあります
- グローバルスコープで定義された変数やオブジェクトが保持され、再初期化不要(例:DB接続の再利用)
- /tmp ディレクトリに最大10GBまで一時ファイルを保存可能で、次の呼び出しでも再利用可能(キャッシュ用途)
ただし、Lambdaのランタイム更新やインフラメンテナンスなどの理由で、数時間ごとに実行環境は破棄されます。
以上、実行環境のライフサイクルついてまとめると、次のようになります。
- Lambda関数の実行環境には「初期化」「呼び出し」「シャットダウン」など複数のフェーズがある
- 初期化フェーズでは関数の準備が行われ、通常は10秒以内に完了する必要がある
- 実行環境はすぐ削除されず再利用されるため、パフォーマンス向上やコスト最適化に寄与する
- ただし、再利用の保証はなく、Lambdaの内部事情で環境が破棄されることもある
ここまでで、「Lambdaは関数のコードを実行したあとも、使用した実行環境を一定時間保持することがある」ということがわかりました。
リクエストを1件ずつ処理する場合はこのようになりますが、実施には複数のリクエストが同時に処理していて、その場合どのような処理をするのかが気になりました。
そこで次は、Lambda関数のスケーリングの仕組みについてもう少し深掘りしてみたいと思います。
Lambda関数のスケーリングと同時実行数について
同時実行数とは、Lambda関数が同時に処理しているリクエスト数のことを指します。
まず、1つの実行環境がリクエストを処理する例をみていきます。
Lambdaは分離された実行環境で関数を呼び出します。リクエストを処理する際、まず実行環境を初期化してから、その中で関数の処理が実行されます。
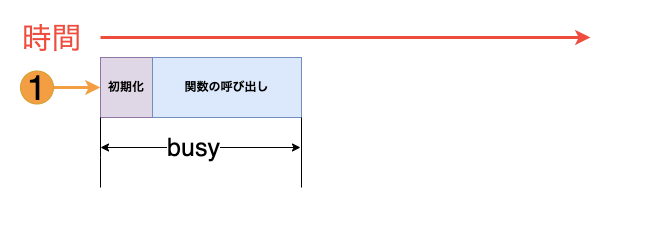
関数がリクエストを受け取ると、ハンドラー関数の処理が完了するまで、その実行環境はbusy状態となり、他のリクエストを処理できません。
処理が完了してするとその環境は再利用可能となり、次のリクエストの処理へ使用できるようになります。
その際、Lambdaは再度の初期化を行わず、既存の環境を即座に使用します。
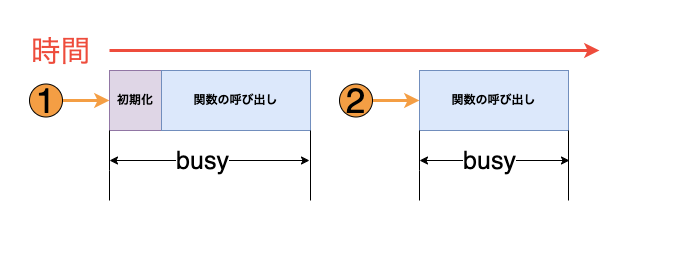
1つの実行環境でリクエストを処理する場合は上記のような流れになりますが、実際には複数の実行環境で同時に複数のリクエストを処理します。Lambda関数がリクエストを受け取ったとき、Lambdaは以下のどちらかの動作を行います
- 事前に初期化された実行環境があれば、それを再利用
- 利用可能な環境がなければ、新しい実行環境を自動でプロビジョニング
たとえば、10件のリクエストを受け取った場合の動作は以下のようになります。
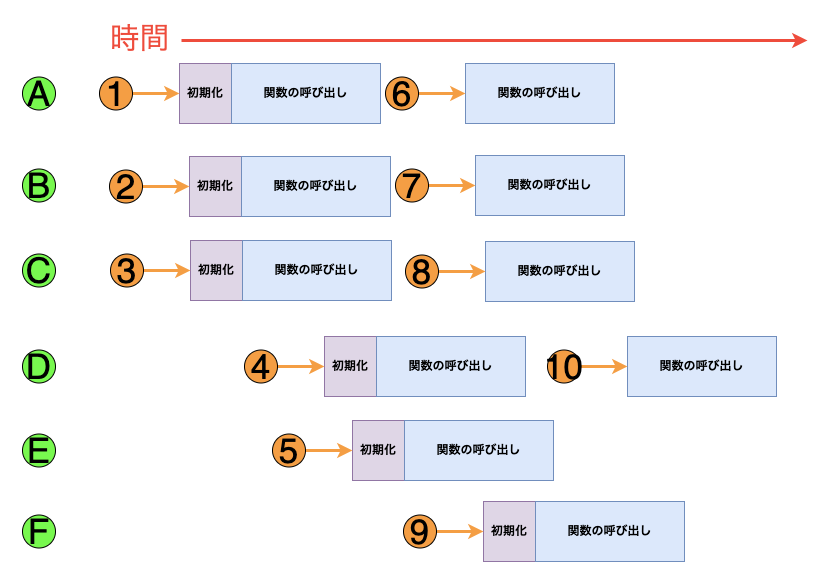
| リクエスト | Lambdaの動作 | 理由 |
|---|---|---|
| 1 | 新しい環境Aをプロビジョニング | 最初のリクエストを処理する |
| 2 | 新しい環境Bをプロビジョニング | 既存の実行環境Aがbusy |
| 3 | 新しい環境Cをプロビジョニング | 既存の実行環境AとBがどちらもbusy |
| 4 | 新しい環境Dをプロビジョニング | 既存の実行環境A、B、Cのすべてがbusy |
| 5 | 新しい環境Eをプロビジョニング | 既存の実行環境A、B、C、Dのすべてがbusy |
| 6 | 環境Aを再利用 | 実行環境Aがリクエスト1の処理を完了し、利用可能になっている |
| 7 | 環境Bを再利用 | 実行環境Bがリクエスト2の処理を完了し、利用可能になっている |
| 8 | 環境Aを再利用 | 実行環境Cがリクエスト3の処理を完了し、利用可能になっている |
| 9 | 新しい環境 F をプロビジョニング | 既存の実行環境A、B、C、D、Eのすべてがbusy |
| 10 | 環境Dを再利用 | 実行環境Dがリクエスト4の処理を完了し、利用可能になっている |
Lambda関数が同時に処理しているリクエスト数のことを同時実行数と言います。
Lambdaは、関数が受け取るリクエストが増えると、実行環境数を自動的にスケーリングします。
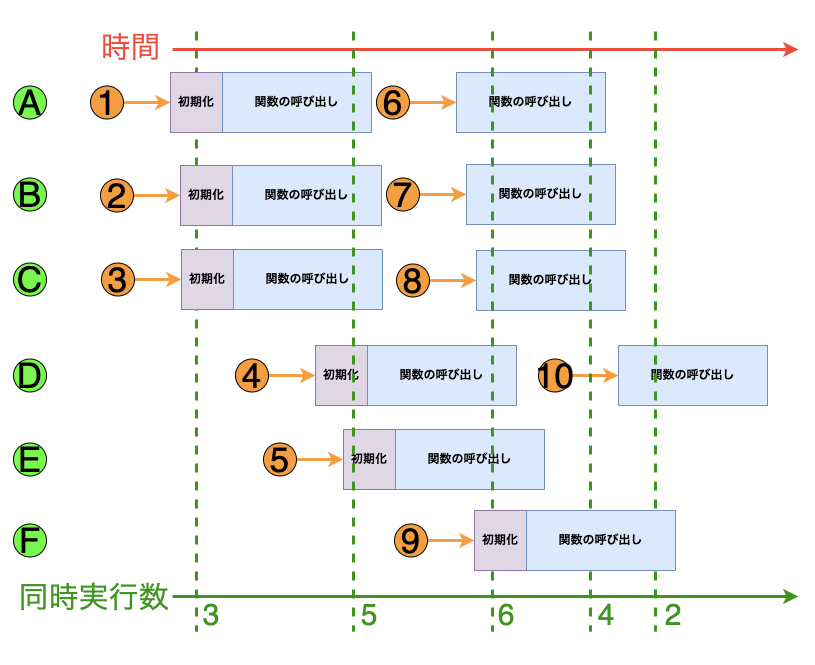
先ほどの例のときの同時実行数は上記のようになります。
なお、同時実行数のデフォルトの上限は、1アカウントに対して1つのリージョン内のすべての関数全体で1,000となっていて、アカウントの同時実行数の上限に達するまでこのスケーリングは行われます。同時実行数の上限に達すると、関数でスロットリングが発生し、リクエストがドロップされ始めます。
スロットリング発生を防止するためには、以下のどちらかを実施する必要があります。
- アカウント全体の上限を引き上げる(クォート申請)
- 重要な関数に対して同時実行数を設定する
ここまでの内容をまとめると、以下のようになります。
- Lambdaはリクエストごとに専用の実行環境を用意して処理する
- 実行環境は同時に1件のリクエストしか処理できないため、複数のリクエストを同時実行するには複数の環境が必要
- Lambdaはリクエスト数に応じて自動的にスケーリングされ、環境を再利用することで効率的に処理する
- 同時実行数には上限があり、上限に達するとスロットリングが発生するため、重要な関数には同時実行数の制御が必要
スケーリングが自動で行われるのは便利ですが、上限があることも分かりました。
特に「絶対に遅延させたくない処理」や「高頻度で実行される関数」では、確実に処理される保証が必要になってくると思います。そのようなユースケースでは、同時実行数を制御する必要があります。
予約された同時実行とプロビジョニングされた同時実行
Lambdaの関数レベルでの同時実行数をコントロールする方法は、2種類あります。
- 予約された同時実行
- プロビジョニングされた同時実行
予約された同時実行
予約された同時実行とは、特定のLambda関数に対して、アカウント全体の同時実行数の一部を占有的に割り当てる仕組みです。これにより、特定のLambda関数が常に安定して同時実行できる環境を確保することができます。この設定に対して料金は発生しません。
例えば、次のように2つのLambda関数に予約された同時実行数を設定したとします。
- 関数A : 400
- 関数B : 400
この時、リクエストが発生した時のLambda関数の同時実行数の遷移は以下のようになります。
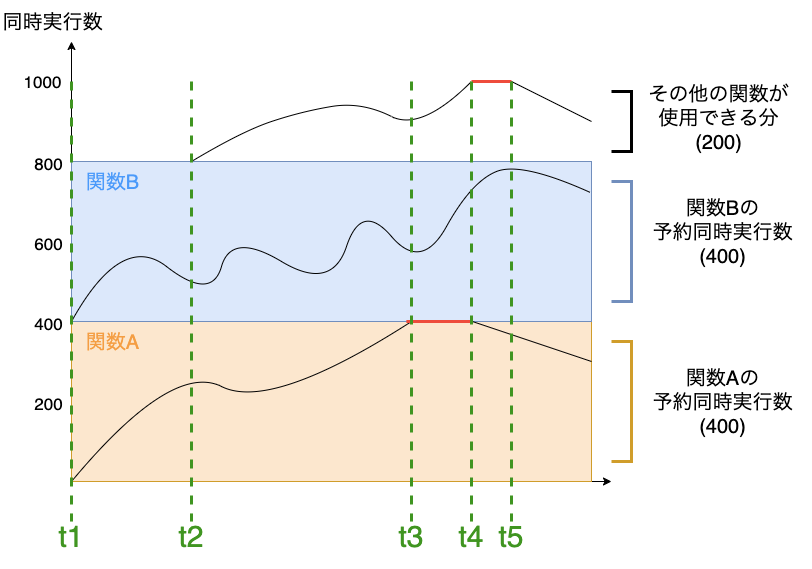
上記の図から
- t3からt4の間で、関数Aが予約された同時実行数である400に達し、アカウント全体として同時実行数に余裕があるものの、関数Aはそれらにアクセスできず、スロットリングが発生している
- t4からt5の間で、他の関数に対するリクエストが急増するが、関数A、Bの予約された同時実行数にアクセスできず、スロットリングが発生している
ということがわかります。このように、予約された同時実行は特定の関数のリソース確保に強力ですが、他の関数に対しては制限となる場合があります。予約された同時実行の特徴をまとめると以下のようになります。
- 予約された同時実行は、特定のLambda関数が同時実行できる数をあらかじめ確保する仕組み
- 予約された同時実行数を設定することで、Lambda関数はアカウント内の他の関数とリソースを取り合わずにスケーリングすることができる
- 逆に、予約された枠は他の関数からは使えないため、トラフィックの偏りによってはスロットリングの原因になることもある
- 予約された同時実行数を設定した関数は、その数でしかスケールアウトできない
注意すべき点として、
実行環境が常にウォームで保たれるわけではない(コールドスタートが発生する)ため、実行頻度が低い関数のコールドスタートは防げない
という点があります。
プロビジョニングされた同時実行
プロビジョニングされた同時実行とは、特定のLambda関数のために、あらかじめ初期化された実行環境を常時用意しておく仕組みです。この機能を有効にすると、Lambdaは指定した数の初期化済み実行環境を常に確保された状態を維持します。この仕組みにより、コールドスタートを回避することができます。
ただし、プロビジョニングされた同時実行を利用すると追加料金が発生します。
予約された同時実行とプロビジョンニングされた同時実行の違いについて図にしてみました。
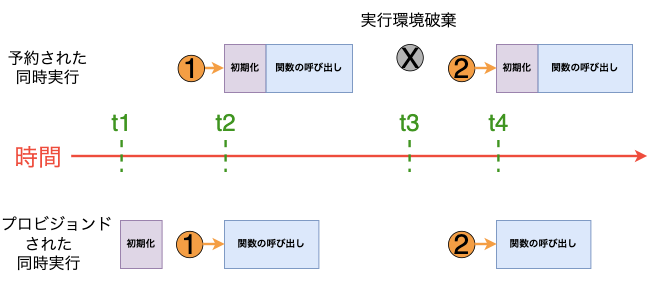
2つの同時実行の違いをまとめると、以下のようになります。
- Lambda関数は、一定時間実行されないと実行環境を破棄する
- 実行環境が存在しない状態でリクエストが来ると、新たに初期化が行われるため、コールドスタートが発生する
- 予約された同時実行では、あらかじめ初期化された環境は存在しないため、呼び出し時にリクエスト遅延が発生する可能性がある
- Lambda関数にプロビジョニングされた同時実行を設定しておく、Lambdaはその数だけ実行環境を初期化して、関数リクエストに即座に応答できるよう準備しておく
予約された同時実行とプロビジョンニングされた同時実行とは、設定した同時実行数を超えるリクエストが発生した場合の挙動にも違いがあります。下記は関数Aにプロビジョンニングされた同時実行のみを設定した場合の例です。
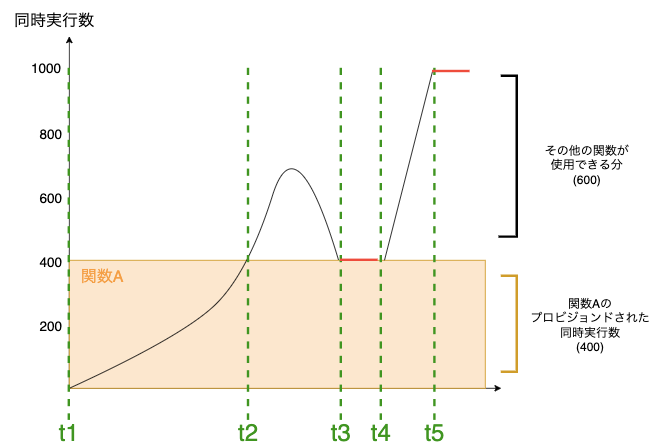
このときの処理の挙動をまとめると以下のようになります。
- t2で関数Aの同時リクエストが400件に達し、プロビジョニングされた同時実行数を使い切ります。ただし、まだアカウント内に予約されていない同時実行枠が残っているため、Lambdaはこれを使ってリクエストを処理する
- このときLambdaはこれらのリクエストを処理するために新しい実行環境を作成する必要があり、関数でコールドスタートレイテンシーが発生する可能性があります
- t3では、トラフィックが一時的に落ち着き、関数Aのリクエスト数が再び400件以内に収まるため、プロビジョニングされたの実行環境だけで処理でき、コールドスタートなしで安定稼働する
- t4で関数A以外でトラフィックが急増したため、Lambdaは残りの予約されていない同時実行枠を使って対応
- t5でアカウント全体での同時実行数が上限に到達し、これ以上リクエストは処理できずスロットリングが発生
また、同じLambda関数に予約された同時実行とプロビジョニングされた同時実行を設定したすることも可能です。その場合、次のようになります。
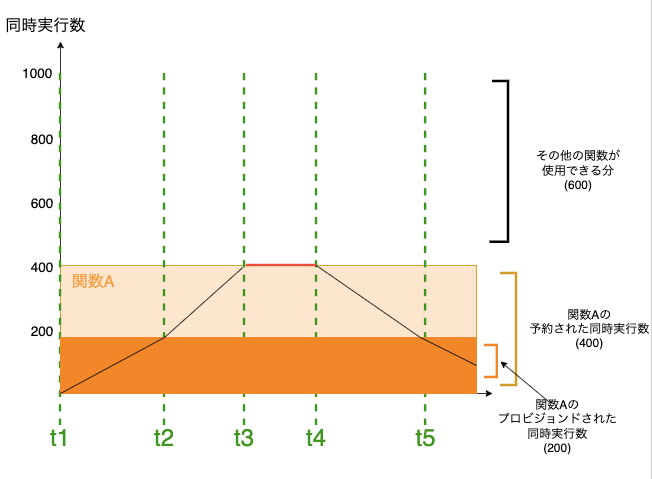
このときの処理の挙動は
- t2でリクエスト数が200件を超え、プロビジョニングされた同時実行枠が上限に到達します。以降のリクエストは、予約された同時実行枠を使用して処理されるが、新たな実行環境の初期化が必要となるため、コールドスタートレイテンシーが発生する可能性あり
- t3でリクエスト数が400件に達し、予約された同時実行枠も全て使い切ります。この時点で、関数Aは予約されていない同時実行枠を使用できない設定になっているため、スロットリングが発生し始める
- t4でリクエスト数が減少し、スロットリングが解消されます
- t5で同時リクエスト数が200件まで減少するため、全リクエストがプロビジョニングされた初期化済み環境で処理され、コールドスタートレイテンシーがなくなる
となっています。プロビジョニングされた同時実行の特徴をまとめると以下のようになります。
- プロビジョニングされた同時実行を有効化すると、あらかじめ初期化された実行環境を用意しておくができ、コールドスタートを回避することができる
- 設定したプロビジョニングされた同時実行数を超えるリクエストが発生した場合も、アカウント全体の同時実行数の制限に達していなければ、リクエストを処理することができる
- ただし、プロビジョニングされた同時実行を利用すると追加料金が発生します
予約された同時実行とプロビジョニングされた同時実行の比較
予約された同時実行とプロビジョニングされた同時実行を比較した結果をまとめます。
| 予約された同時実行 | プロビジョニングされた同時実行 | |
|---|---|---|
| 定義 | Lambda関数の実行環境の最大数 | Lambda関数用に事前にプロビジョニングされた、一定数の実行環境数 |
| プロビジョニング動作 | 新しい実行環境をオンデマンドベースでプロビジョニングする | 実行環境を事前にプロビジョニングする |
| コールドスタート動作 | コールドスタートレイテンシーが発生する可能性がある | コールドスタートレイテンシーが発生することはない |
| スロットリング動作 | 予約された同時実行の上限に達すると、関数がスロットルする | プロビジョニングされた同時実行の上限に達すると、予約されていない同時実行を使用する |
| 料金 | 追加料金は発生しない | 追加料金が発生する |
プロビジョニングされた同時実行の検証
検証環境構築
プロビジョニングされた同時実行を設定することで、Lambda関数の応答速度がどの程度改善されるのかを実際に検証してみます。
今回は、API Gateway をトリガーとしてLambda関数を呼び出す環境をAWS CDKを使って構築します。
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as iam from 'aws-cdk-lib/aws-iam';
import * as lambda from "aws-cdk-lib/aws-lambda";
import * as path from 'node:path';
import * as apigateway from 'aws-cdk-lib/aws-apigateway';
export class LambdaStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// Lambda関数の実行ロールを作成
const lambdaRole = new iam.Role(this, 'LambdaExecutionRole', {
assumedBy: new iam.ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole'),
iam.ManagedPolicy.fromAwsManagedPolicyName('AmazonS3ReadOnlyAccess'),
],
});
// lambda関数の作成
const fn = new lambda.Function(this, 'TestFuncton', {
functionName: 'TestFunction',
runtime: lambda.Runtime.PYTHON_3_12,
handler: 'index.handler',
code: lambda.Code.fromAsset(path.join(__dirname, 'lambda-handler'), {
bundling: {
image: lambda.Runtime.PYTHON_3_12.bundlingImage,
command: [
'bash', '-c',
'pip install -r requirements.txt -t /asset-output && cp -au . /asset-output'
]
}
}),
role: lambdaRole,
timeout: cdk.Duration.seconds(60),
environment: {
TIMESTAMP: new Date().toISOString(), // deployするごとに新しいバージョンを発行
},
});
const alias = new lambda.Alias(this, 'TestFunctionAlias', {
aliasName: 'test',
version: fn.currentVersion,
});
// API Gatewayの作成
const api = new apigateway.RestApi(this, 'TestApi', {
restApiName: 'Test API',
deployOptions: {
stageName: 'test',
},
});
// API GatewayとLambda関数の統合
api.root.addMethod('GET', new apigateway.LambdaIntegration(alias));
}
}
Lambda関数のハンドラーには、以下のようなコードを用意しました。
あえて初期化に時間がかかるような処理を記述し、コールドスタート時の影響を明確に観測できるようにしています。
import boto3
import json
import time
print("初期化の実行")
time.sleep(5)
def handler(event, context):
s3 = boto3.client('s3')
# S3バケット一覧を取得
response = s3.list_buckets()
buckets = [bucket['Name'] for bucket in response.get('Buckets', [])]
return {
'statusCode': 200,
'body': json.dumps({'buckets': buckets})
}
AWS X-Rayの有効化
検証にあたっては、AWS X-Rayを使って関数実行時の各フェーズの所要時間を可視化します。
AWS X-Rayとは
AWS X-Ray は、分散トレーシングサービスで、以下のような機能を使用できるサービスです。
- LambdaやAPI Gatewayなどのアプリケーションコンポーネントの処理経路を可視化
- 上記を利用して、処理の遅延やボトルネックの特定が可能となる
- 各処理ステップがどのくらい時間を要しているかを直感的に把握できる
CDKでAWS X-Rayを有効にする
CDKでX-Rayを有効にするのはとても簡単で、Lambda関数の定義に1行追加するだけです。
これにより、実行ロールに必要なIAMポリシーも自動で付与されるため、手間なくトレーシングを開始できます。
// snip
const fn = new lambda.Function(this, 'TestFunction', {
// snip
timeout: cdk.Duration.seconds(60),
environment: {
TIMESTAMP: new Date().toISOString(),
},
tracing: lambda.Tracing.ACTIVE, // X-Rayを有効にする
});
}
}
AWS X-rayで確認できるトレースデータ
AWS X-Rayを有効にした状態で、API Gateway経由でLambda関数を複数回呼び出し、その挙動を確認してみます。
呼び出しが完了したら、X-Rayコンソールから該当のトレースデータを確認してみます。
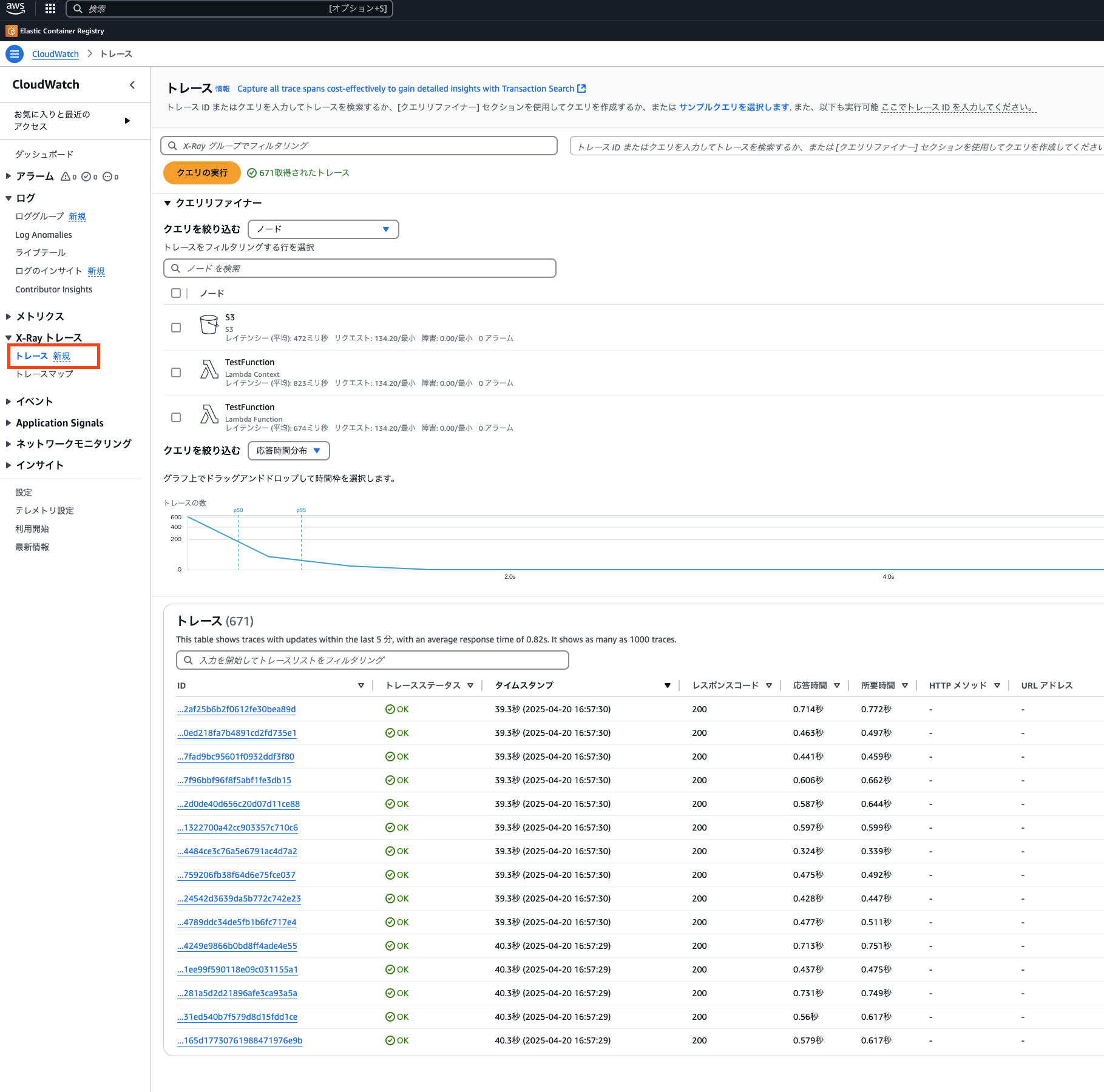
X-Rayのトレースでは、Lambda関数の実行に関わる複数のコンポーネントが視覚化されます。
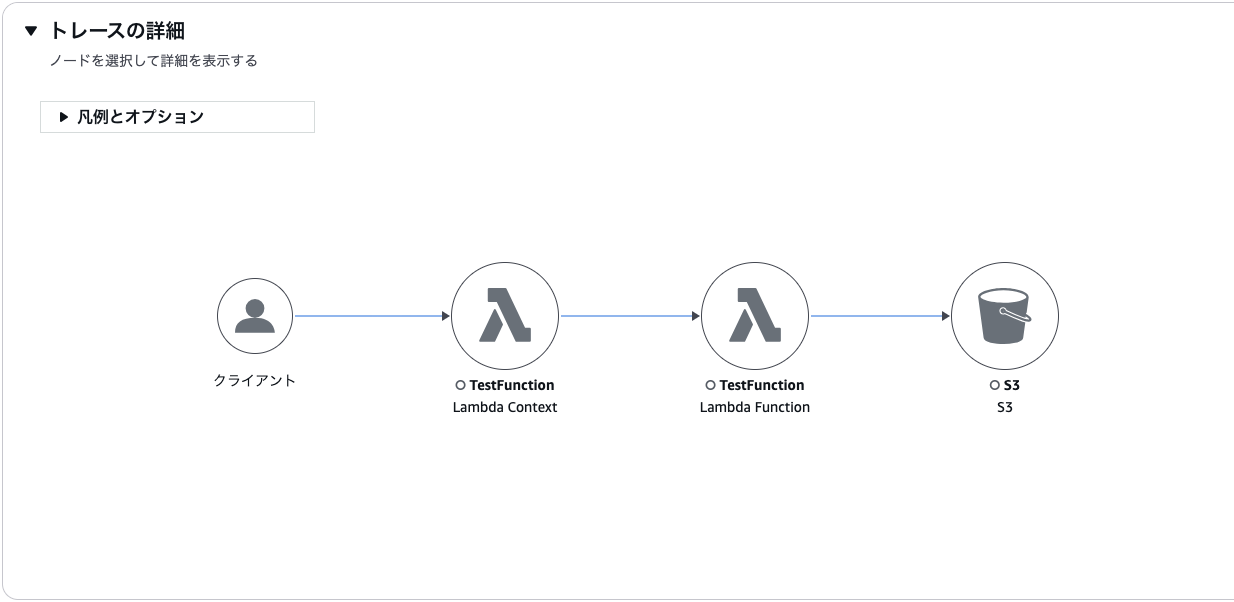
上記の図から次のことがわかります。
- Lambdaが2つ表示されて、前段のLambdaは、リクエストを受け取るAWSLambdaサービスそのものを表していて、後段のLambdaは、実際に処理を行っている対象のLambda関数を表している
- リクエストが発生すると、まずAWSのLambdaサービスが受信し、その後で目的のLambda関数へ処理が渡されるという構造が可視化されている
- Lambda関数がS3にアクセスしていることも視覚的に確認できる
続いてX-Rayのタイムラインビューを見てみます。ここでは、Lambda関数の実行にかかる各処理の時間を詳細に把握できます。以下は、初回呼び出し時のトレースデータです。
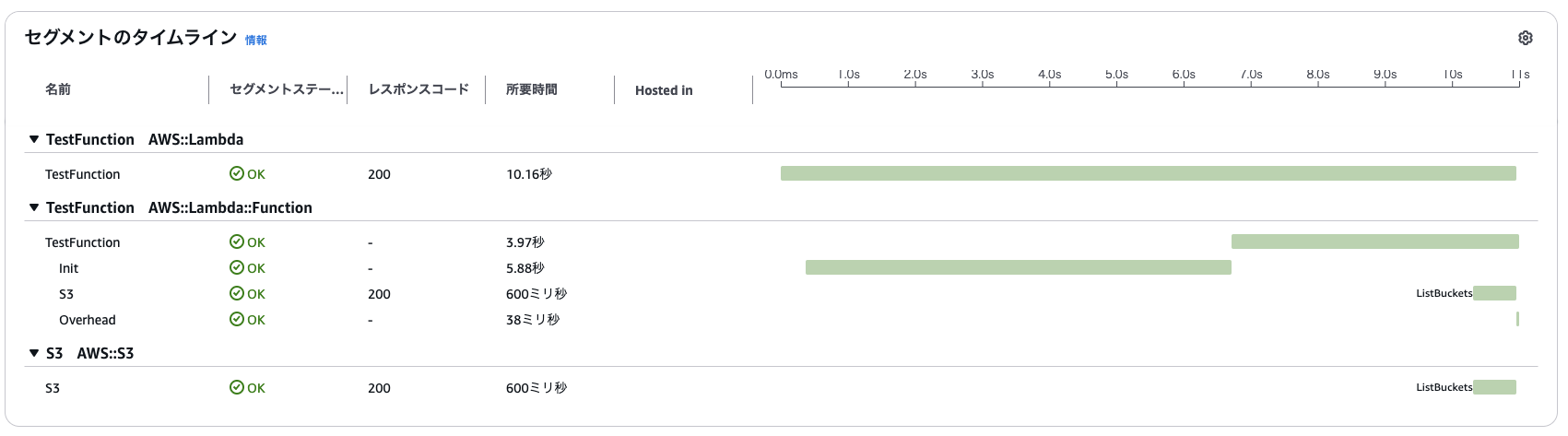
上段がAWS Lambdaサービス、下段がLambda関数本体となっています。
タイムライン上で見ると、初期化処理に約5.88秒かかっていることが確認できます。
続いて同じ関数を再度呼び出した時のトレースデータも確認してみます。
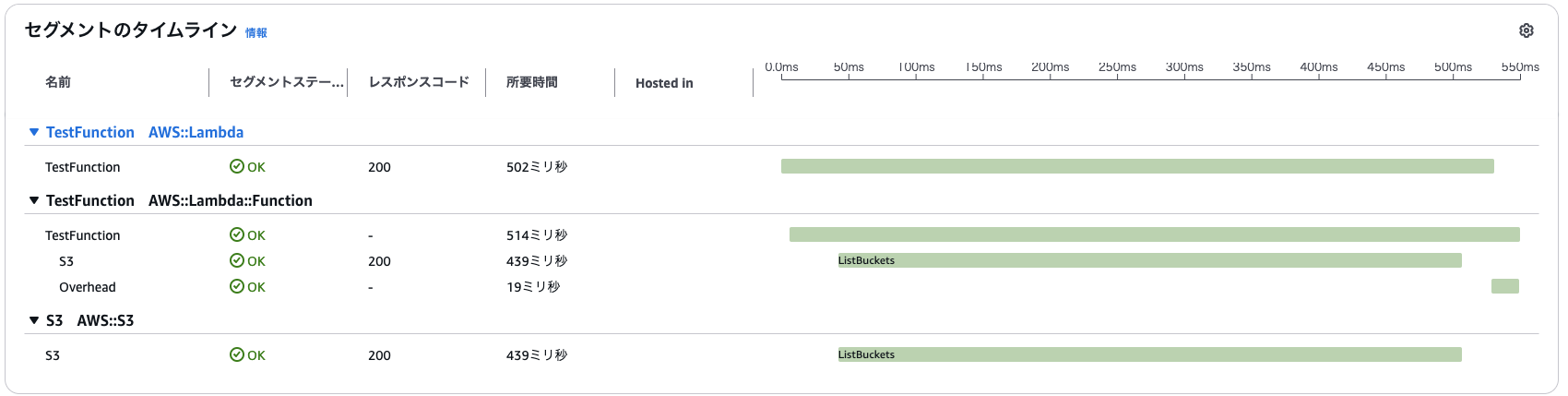
2回目以降の実行では初期化処理が発生しておらず、すぐに関数の処理が行われていることがわかります。
このことから、Lambda関数が前回の実行環境を再利用する場合、コールドスタートが発生していないことがわかります。
同時実行数の遷移の検証
Lambdaのスケーリング挙動とコールドスタートの発生タイミングを観察するため、負荷テストツールである「Locust」を使って同時アクセスを発生させてみます。
本記事ではlocustの詳細な使い方については、割愛します。気になる方は、以下公式ドキュメント等をご参考ください。
ローカルマシンでLocustを起動し、API Gateway経由でLambdaを呼び出すシナリオを実行します。
from locust import HttpUser, task, constant_pacing
class HelloWorldUser(HttpUser):
host = "API Gatewayのエンドポイント/test"
wait_time = constant_pacing(1)
@task
def test(self):
self.client.get("/")
Locustで負荷をかける際には以下の値を設定値とし、徐々にリクエスト数を増やしながら、Lambdaの挙動を確認していきます。
- max_users(同時接続数の上限):20
- Ramp up(立ち上げ速度):1 user/sec
トレース結果の観察
locustで同時アクセスを発生させた後のトレーズデータを確認してみます。
負荷をかけ始めてすぐのトレースを見ると、最初のいくつかのリクエストはすべて初期化処理が発生しており、レスポンスに10秒近くかかっていることが確認できます。
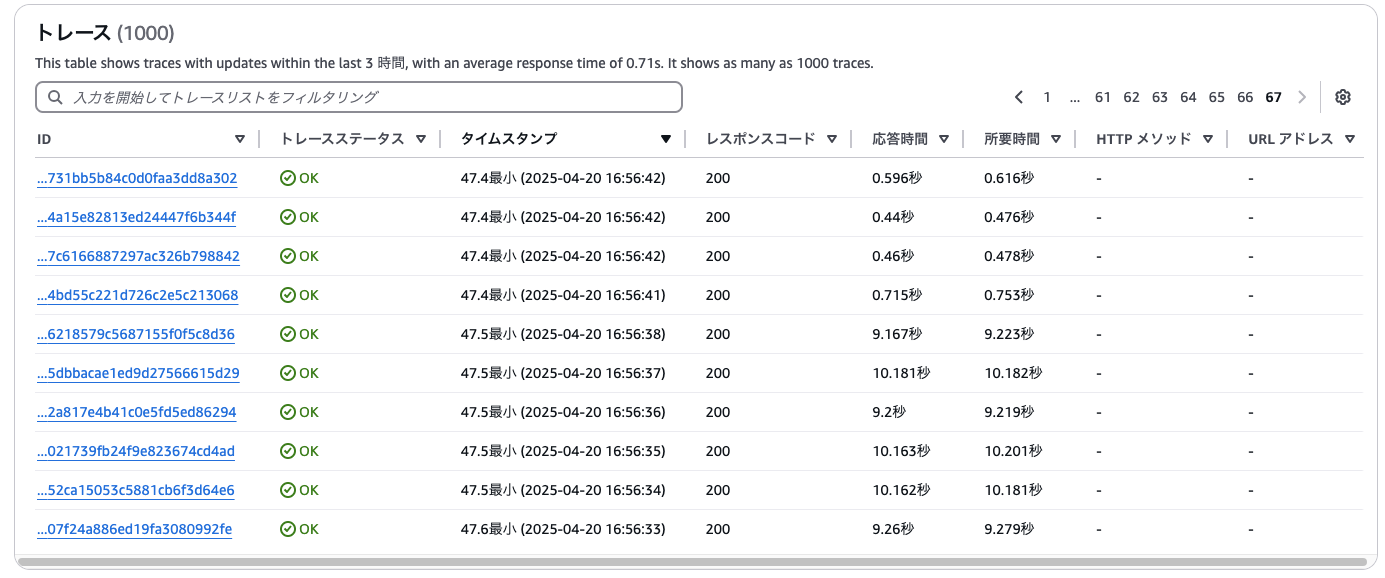
その後、一度処理に使われたLambda実行環境が再利用されるようになり、処理時間の短いトレースが混ざり始めます。この段階では、一部リクエストではまだ新しい実行環境の初期化が行われているため、コールドスタートが発生していることがわかります。
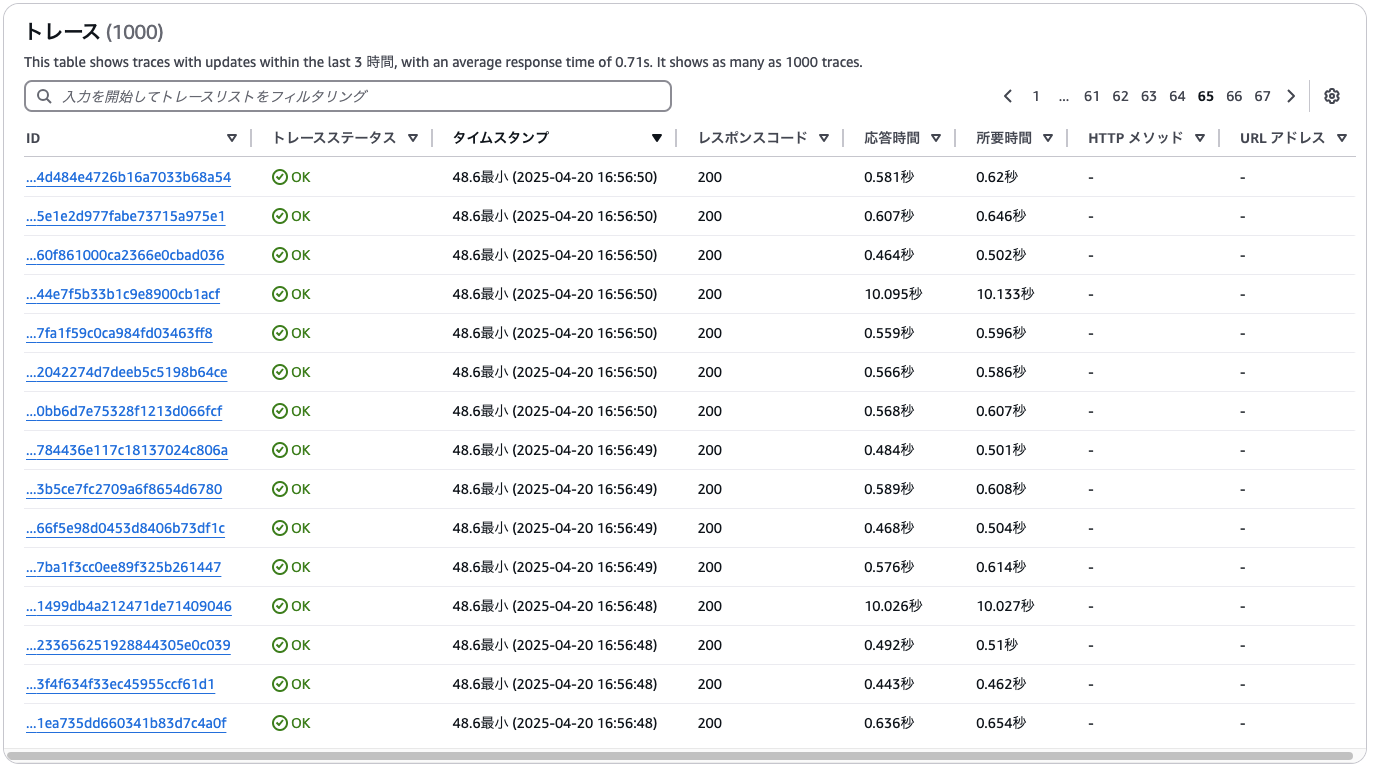
リクエストの後半になると、実行環境の数がリクエスト数に追いつき、すべての処理がウォームスタートで行われていることがわかります。この状態では、初期化処理は一切発生しておらず、Lambdaは安定した低レイテンシで稼働しています。
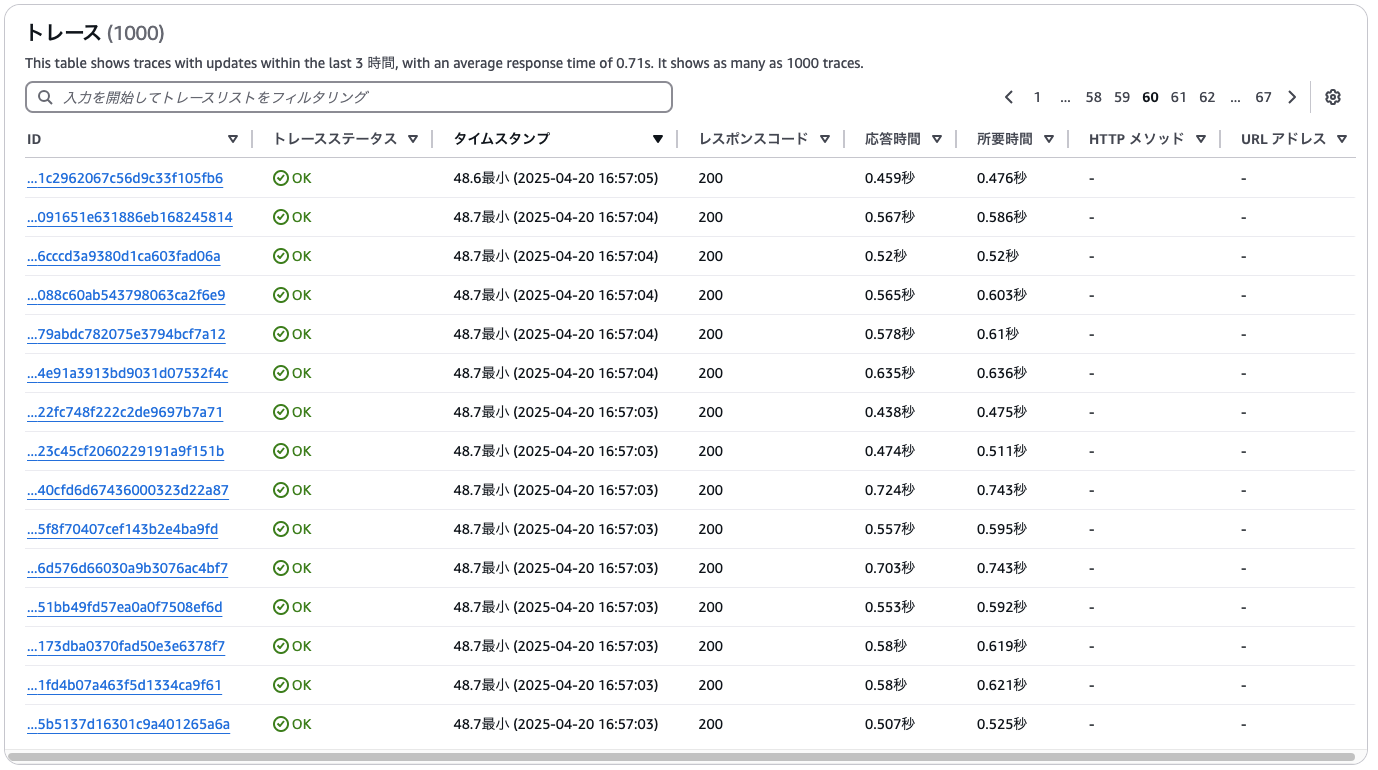
上記の結果から、
- 最初のリクエストではほぼすべてがコールドスタートとなり、処理時間が大幅に長くなる
- 負荷の増加に応じてLambdaがスケーリングし、徐々にウォームスタートによる高速処理へ移行
- 実行環境の数が十分に確保されると、全リクエストがウォームで処理され、コールドスタートが発生しなくなる
ということを確認できました。
プロビジョニングされた同時実行の設定
CDKでプロビジョニングされた同時実行を設定する
プロビジョニングされた同時実行を有効にするには、Lambda関数の「バージョン」または「エイリアス」を対象に設定する必要があります。
export class LambdaStack extends cdk.Stack {
// snip
// Aliasの作成
const alias = new lambda.Alias(this, 'TestFunctionAlias', {
aliasName: 'test',
version: fn.currentVersion,
provisionedConcurrentExecutions: 20 // プロビジョニングされた同時実行数を設定
});
}
}
デプロイ後、マネジメントコンソール上でも設定が反映されていることを確認できました。
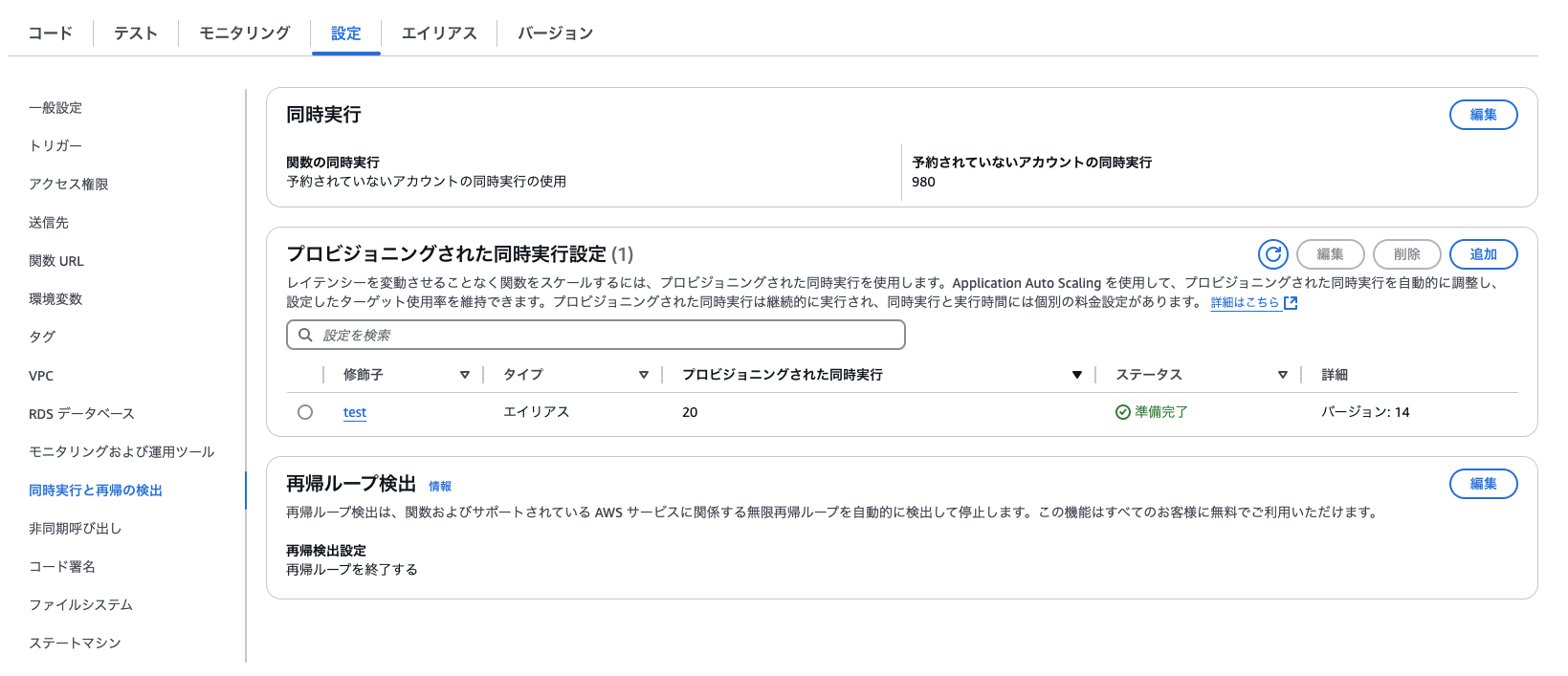
この状態で再度locustを使ってLambda関数に同時アクセスして、X-Rayでトレースデータを確認してみます。
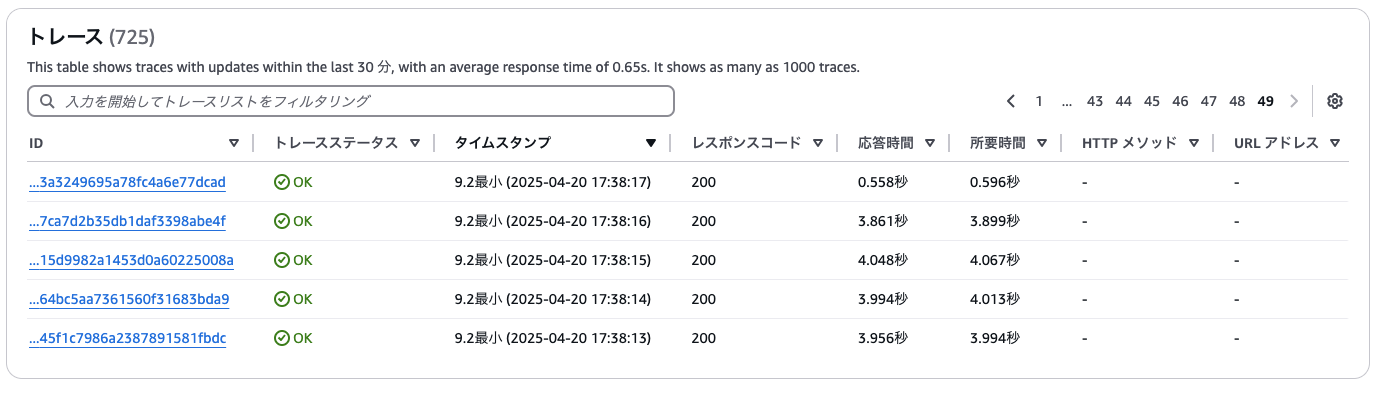
負荷をかけた最初の数件のリクエストは、おおよそ4秒前後で処理が完了しており、初期化フェーズにかかる時間(約6秒)が発生していないことがわかります。
X-Rayの詳細トレースを見ても、初期化フェーズが発生していないことが視覚的に確認できます。
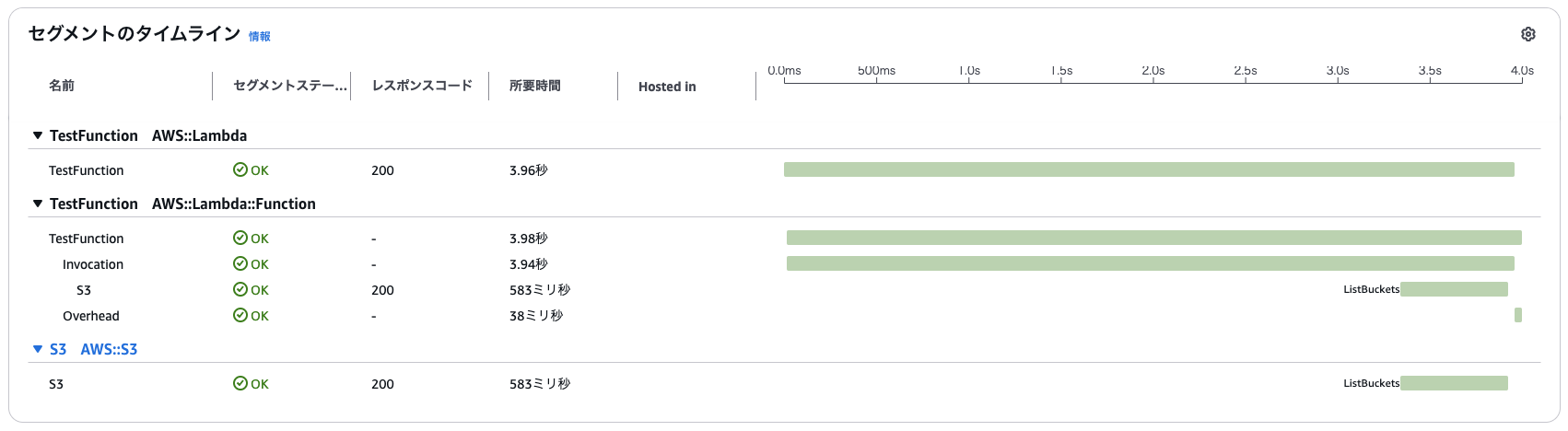
上記の結果から、
- プロビジョニングされた同時実行を設定することで、最初のリクエストでもコールドスタートが発生せず、安定して高速にリクエストを処理することができる
ことを確認できました。
Snapstart
Lambdaにおけるコールドスタートの遅延を軽減するためのもう一つの仕組みとして、SnapStartと呼ばれるものもあります。
SnapStartでは、関数を初期化した際の実行環境のメモリ・ディスクの状態をスナップショットとして保存しておき、関数が呼び出された際には、このスナップショットから実行環境を復元し、関数を実行します。LambdaのランタイムとしてJavaを利用している場合、追加料金なしで利用できるのが大きな特徴です。
サポートされているランタイムとリージョン
| ランタイム | 対応バージョン | 対応リージョン |
|---|---|---|
| Java | Java11以降 | 全てのリージョン |
| Python | Python3.12以降 | 一部リージョンのみ |
| .NET | .NET8以降 | 特定のリージョン |
Javaは全てのリージョンで使用することができますが、Pythonと.NETについては、特定のリージョンでのみ利用可能となっています。(2025/4/21現在)
SnapStartの動作検証
CDKでの有効方法SnapStart
PythonでSnapStartを有効化する機能は、CDK v2.167.0以降でサポートされています。
以下は、SnapStartを有効にしたLambda関数のCDKでのコード例です。
export class LambdaStack extends cdk.Stack {
// snip
// lambda関数の作成
const fn = new lambda.Function(this, 'TestFunction', {
// snip
timeout: cdk.Duration.seconds(60),
environment: {
TIMESTAMP: new Date().toISOString(),
},
tracing: lambda.Tracing.ACTIVE, // X-Rayを有効にする
snapStart: lambda.SnapStartConf.ON_PUBLISHED_VERSIONS, // SnapStartを有効にする
});
}
}
デプロイ後、マネジメントコンソールでもSnapStartが有効になっていることを確認できます。
X-Rayでのトレースデータの確認
SnapStartを有効にしたLambda関数をAPI Gateway経由で複数回呼び出し、X-Rayでトレースデータを確認しました。

最初のいくつかのリクエストでは約5秒程度の応答時間がかかっていました。同じ条件で試したプロビジョンニングされた同時実行の方が高速に動作することがわかりました。
さらにX-Rayの詳細トレースを確認すると、SnapStart有効時には初期化フェーズが発生しておらず、代わりにRestoreフェーズが発生していることも視覚的に確認できます。
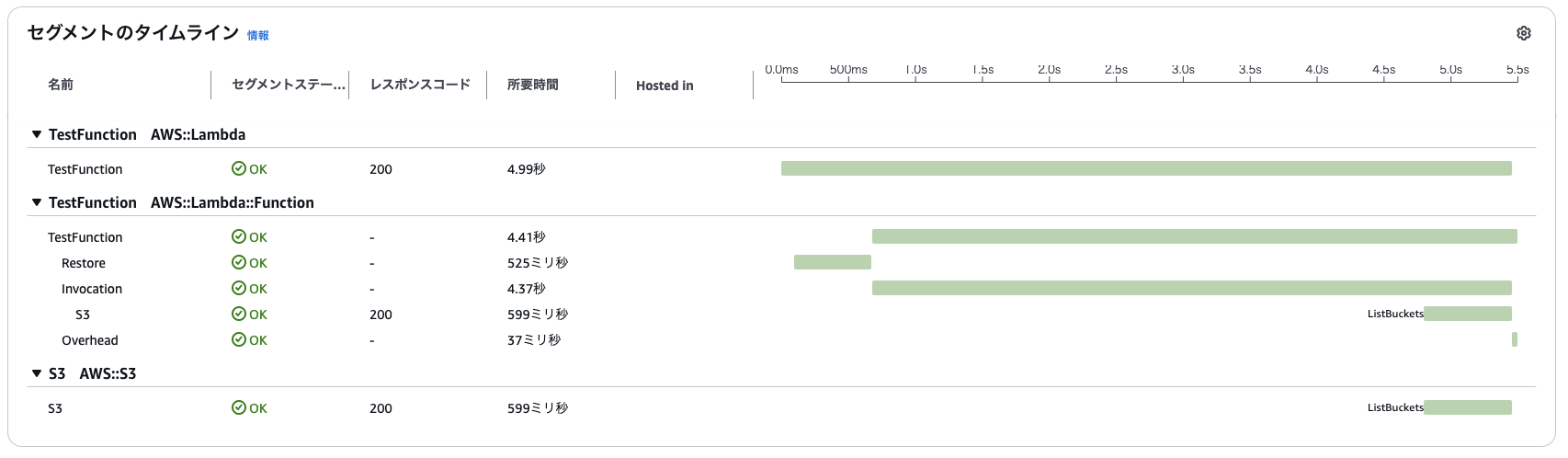
上記検証により以下のことがわかりました。
- SnapStartを有効化した関数では、初期化をスキップして迅速に関数実行が開始されていること
- Restoreフェーズが発生するため、プロビジョニングされた同時実行の方が高速に動作すること
プロビジョンドされた同時実行と SnapStart の比較
最後にプロビジョンドされた同時実行とSnapStartの2つの機能についての違いをまとめます。
プロビジョンドされた同時実行
特徴
- 初期化済みの実行環境を常時保持する
- すべてのランタイム、リージョンで利用できる
応答速度とコスト
- 初期化やリストアを実行する必要がないため、高速
- 常に実行環境を維持するため、リクエストがない時間帯も課金される
- 高速性と引き換えに、コストはやや高め
その他の制約
- Lambda関数のバージョンもしくはエイリアスに対して設定する
SnapStart
特徴
- 初期化した実行環境のスナップショットを復元する
応答速度とコスト
- スナップショットをリストアする必要があるため、プロビジョンドされた同時実行に比べて時間がかかる
- 使用していない時間帯のコストが比較的安価。Javaに関しては無料
その他の制約
- 特定のランタイム(Java,Python、.NET)でのみ利用可能(バージョンの制約もあり)
- 特定のリージョンでしか利用できないランタイムもある
まとめ
AWS Lambdaにおけるコールドスタートの仕組みとその対策について、動作検証を含め調査しました。
特に重要なポイントとしては以下の点が挙げられます。
- Lambdaは同時実行数に応じてスケーリングするが、1つの実行環境では1リクエストしか処理できないため、リクエスト数が急増するユースケースでは適切なリソース確保が不可欠
- 予約された同時実行は特定関数にリソースを確保できるが、コールドスタートは回避できない
- プロビジョニングされた同時実行はコールドスタートを回避できる強力な手段だが、コストが発生する
- SnapStartは主にJava/Pythonなどで利用でき、スナップショットの復元によりコールドスタートのレイテンシを抑える選択肢として有効
用途や実行頻度、コスト要件に応じて、これらの機能を適切に組み合わせることで、Lambdaのパフォーマンスと信頼性を最大限に引き出すことができます。プロビジョニングされた同時実行についても、Auto Scalingと組み合わせることで、最適なコスト&高いパフォーマンスを実現できるそうなので、その検証もやってみたいなと思っています。
コールド対策を調べるにあたり、Lambdaの実行環境のライフサイクルや同時実行の仕組みなども知ることができ、ちょっとLambdaと仲良くなれたような気がします。
参考