はじめに
こんにちは!Fusic Advent Calendar 2023の12日目を担当します@pensuke628です。
最近AWSのお仕事でLambdaを使い始めましたが、Lambdaって便利だな〜と感じる日々です(感想が薄い)
今回は、SQLサーバーに対してSQLを実行するlambdaをTerraformを作ってみたので、記事にしたいと思います。使用したterraformのバージョンは以下になります。
$ terraform -v
Terraform v1.5.4
また、最終的なフォルダの構造は以下のようになっています。
.
├── lambda_function.py
├── lambda_function.zip
├── pyodbc.zip
└── terraform
├── backend.tf
├── main.tf
├── provider.tf
├── terraform.tfstate
├── terraform.tfstate.backup
└── variables.tf
今回構築するもの
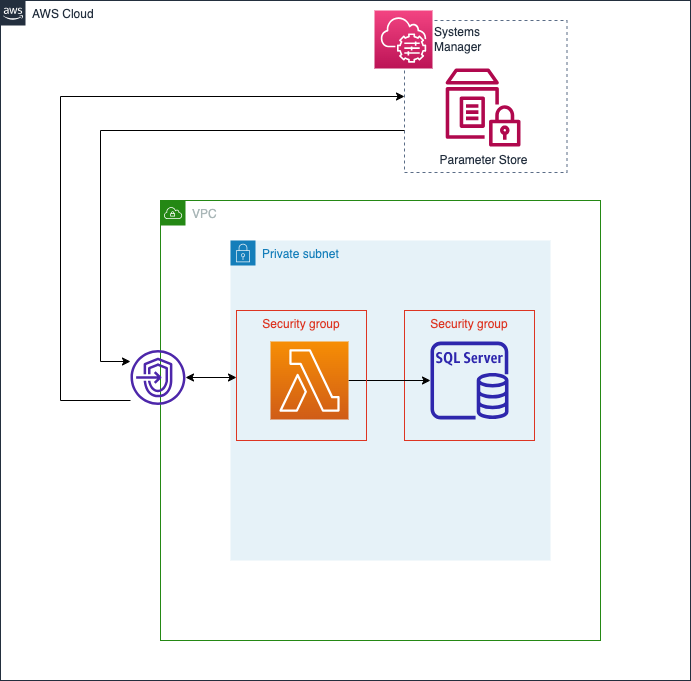
今回はこのような構成でAWSサービスを構築していこうと思います。
SQLサーバーの接続に必要なエンドポイントやpasswordなどをParameter Storeから取得してきて、それらを基にSQLサーバーに接続し、SQLを実行するといった構成になっています。
STEP1 lambdaで使用するライブラリを用意する
今回、SQLサーバーに接続するために、pyodbcというライブラリを使用します。
lambdaで標準で用意されているライブラリを使用する場合、特に気にせずlambdaのソースコード内でimportすれば良いのですが、pyodbcはlambdaに標準で用意されていないライブラリです。そのため、ライブラリをzip化したものをlambdaのlayersに追加する必要があります。以下の記事を参考にさせていただきました。ありがとうございます!
今回は、pyodbc.zipというファイル名でzip化しています。
STEP2 lambdaで実行する関数を記述する
lambdaで実行したい処理を記述したソースコードを用意します。
今回はSQLサーバー内のデータベース一覧を出力するSQLを実行するような簡単なコードを実装します。ランタイムは使ったことがあまりないpythonを使用してみました。
boto3の部分は以下のドキュメントを参考にしました。
import boto3
import pyodbc
def list_databases(cursor):
cursor.execute("SELECT name FROM sys.databases;")
databases = cursor.fetchall()
print("Databases on server:")
for db in databases:
print(db[0])
def lambda_handler(event, context):
ssm = boto3.client('ssm')
# SQLサーバーへの接続情報が格納されたParameter Storeのpathを取得
sql_server_endpoint_param = event.get('endpoint', '')
sql_server_username_param = event.get('username', '')
sql_server_password_param = event.get('password', '')
# ParameterStoreから値を取得
response = ssm.get_parameters(
Names = [
sql_server_endpoint_param,
sql_server_username_param,
sql_server_password_param,
],
WithDecryption=True
)
values = {param['Name']: param['Value'] for param in response['Parameters']}
driver = '{ODBC Driver 17 for SQL Server}'
server = values[sql_server_endpoint_param]
port = '1433'
username = values[sql_server_username_param]
password = values[sql_server_password_param]
connection_string = f'DRIVER={driver};SERVER={server},{port};UID={username};PWD={password}'
with pyodbc.connect(connection_string, autocommit=True) as connection:
with connection.cursor() as cursor:
list_databases(cursor)
こちらを以下のコマンドでzip化しておきます。
zip lambda_function.zip lambda_function.py
STEP3 TerraformでAWSサービスを構築する
ここからやっとこさ、terraformでAWSのサービスを構築していきます。本当はmoduleとしてサービス毎にまとめて書こうとも思ったですが、そんなに構築するリソースはないだろうと思って、main.tfにベタ書きしております。(結構多くなってしまい反省しています。。)いくつかのリソースごとに分けて書いていこうと思います。
VPCとサブネット
resource "aws_vpc" "vpc" {
cidr_block = "10.0.0.0/16"
enable_dns_support = true
enable_dns_hostnames = true
}
# SQLSeverとLambdaを設置するsubnet
resource "aws_subnet" "private_db_subnet_1a" {
vpc_id = aws_vpc.vpc.id
cidr_block = "10.0.1.0/24"
availability_zone = "ap-northeast-1a"
map_public_ip_on_launch = true
}
resource "aws_subnet" "private_db_subnet_1c" {
vpc_id = aws_vpc.vpc.id
cidr_block = "10.0.2.0/24"
availability_zone = "ap-northeast-1c"
map_public_ip_on_launch = true
}
resource "aws_subnet" "vpce" {
vpc_id = aws_vpc.vpc.id
cidr_block = "10.0.3.0/24"
availability_zone = "ap-northeast-1a"
map_public_ip_on_launch = true
}
resource "aws_db_subnet_group" "db_subnet_group" {
subnet_ids = [
aws_subnet.private_db_subnet_1a.id,
aws_subnet.private_db_subnet_1c.id
]
}
VPCとそれぞれのリソースを設置するためのサブネットを作成しています。
SQLサーバー用のサブネットを2つ作っている理由は、サブネットグループを作成するためです。
Security Groups
# SQLServerにアタッチするSecurity Group
resource "aws_security_group" "db" {
vpc_id = aws_vpc.vpc.id
tags = {
"Name" = "SG attached DB"
}
ingress {
from_port = 1433
to_port = 1433
protocol = "TCP"
security_groups = [
aws_security_group.lambda.id,
]
}
}
# LambdaにアタッチするSecurity Group
resource "aws_security_group" "lambda" {
vpc_id = aws_vpc.vpc.id
tags = {
"Name" = "SG attached Lambda"
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = [
"0.0.0.0/0"
]
}
}
# ssmのエンドポイントのSecurity Group
resource "aws_security_group" "vpce_ssm" {
vpc_id = aws_vpc.vpc.id
tags = {
"Name" = "SG attached Endpoint"
}
ingress {
from_port = 0
to_port = 0
protocol = "-1"
security_groups = [
aws_security_group.lambda.id
]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = [
"0.0.0.0/0"
]
}
}
本当はlambdaのインバウンドルールとかも絞った方が良いのですが、DBのセキュリティグループを参照しようとした場合、循環参照になると怒られたのでこうなりました(terraform applyを分けて実行したらできると思います)。
VPC Endpoint
# ssmのエンドポイント
resource "aws_vpc_endpoint" "ssm" {
vpc_id = aws_vpc.vpc.id
service_name = "com.amazonaws.ap-northeast-1.ssm"
vpc_endpoint_type = "Interface"
subnet_ids = [ aws_subnet.vpce.id ]
security_group_ids = [ aws_security_group.vpce_ssm.id ]
private_dns_enabled = true
}
こちらは特に言うことはなさそうです。
RDSとパラメータストア
# SQLServerのインスタンス
resource "aws_db_instance" "sql_server" {
allocated_storage = 20
engine = "sqlserver-web"
instance_class = "db.t3.small"
username = "admin" # 任意のusername
password = "password" # 任意のpassword
skip_final_snapshot = true
db_subnet_group_name = aws_db_subnet_group.db_subnet_group.id
vpc_security_group_ids = [ aws_security_group.db.id ]
}
# DBの秘匿情報をParameterStoreに保存する
resource "aws_ssm_parameter" "sql_server_endpoint" {
name = "sql_server_endpoint"
type = "SecureString"
value = aws_db_instance.sql_server.address
}
resource "aws_ssm_parameter" "sql_server_username" {
name = "sql_server_username"
type = "SecureString"
value = aws_db_instance.sql_server.username
}
resource "aws_ssm_parameter" "sql_server_master_password" {
name = "sql_server_password"
type = "SecureString"
value = aws_db_instance.sql_server.password
}
SQLサーバーのusernameとpasswordは任意の値をセットします。
作成したRDSのaddressとusername、passwordをParameterStoreに保存しています。
instance_classは使用するengineによって選択できるものが決まっているため、以下を参照しています。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/CHAP_SQLServer.html#SQLServer.Concepts.General.InstanceClasses
IAMロール
# LambdaにアタッチするIAMロール
resource "aws_iam_role" "lambda_role" {
name = "lambda_role"
assume_role_policy = data.aws_iam_policy_document.lambda.json
}
resource "aws_iam_role_policy_attachment" "rds_full_access" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonRDSFullAccess"
}
resource "aws_iam_role_policy_attachment" "ssm_full_access" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSSMFullAccess"
}
resource "aws_iam_role_policy_attachment" "lambda_vpc_access" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole"
}
data "aws_iam_policy_document" "lambda" {
statement {
effect = "Allow"
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
}
}
本当はよくないのですが、今回はRDSとSSMのFullAccess権限をIAMロールに与えています(ごめんなさい)。実際には必要なアクションやリソースに限定したポリシーの設定が求められます(ごめんなさい)。
lambdaのレイヤーと関数
resource "aws_lambda_layer_version" "pyodbc" {
filename = "../pyodbc.zip"
layer_name = "pyodbc"
compatible_runtimes = [ "python3.11" ]
}
resource "aws_lambda_function" "execute_sql" {
filename = "../lambda_function.zip"
function_name = "db_create"
runtime = "python3.11"
handler = "lambda_function.lambda_handler"
role = aws_iam_role.lambda_role.arn
layers = [aws_lambda_layer_version.pyodbc.arn]
timeout = 10
vpc_config {
subnet_ids = [ aws_subnet.private_db_subnet_1a.id ]
security_group_ids = [ aws_security_group.lambda.id ]
}
environment {
variables = {
"ODBCINI": "/opt/python/odbc.ini",
"ODBCSYSINI": "/opt/python"
}
}
}
STEP1で作成したライブラリのzipファイルをlayerとして読み込みます。
STEP2で作成したソースコードはfilenameの箇所に記載しています。
今回はlambdaをVPC内で実行するため、vpc_configでVPCやsubnetの情報を記述しています。
また、環境変数が必要な場合は、environmentで定義します。
Terraformで作成したリソースは以上になります。
terraform planでリソースの差分を確認し、terraform applyで構築します。
テストイベントを作成して実行
最後に、作成したlambdaがSQLサーバーにアクセスし、SQLを実行してくれるのかテストします。
lambdaのサービスのページにアクセスし、作成した関数を選択します。
作成したlambdaのページのタブのうち、「テスト」をクリックすると、下記のようなページが表示されます。こちらではlambdaを実行するときに引数として渡す値を設定することができます。今回はSQLサーバーと接続するために必要な情報を格納したParameterStoreのpathを記載します。
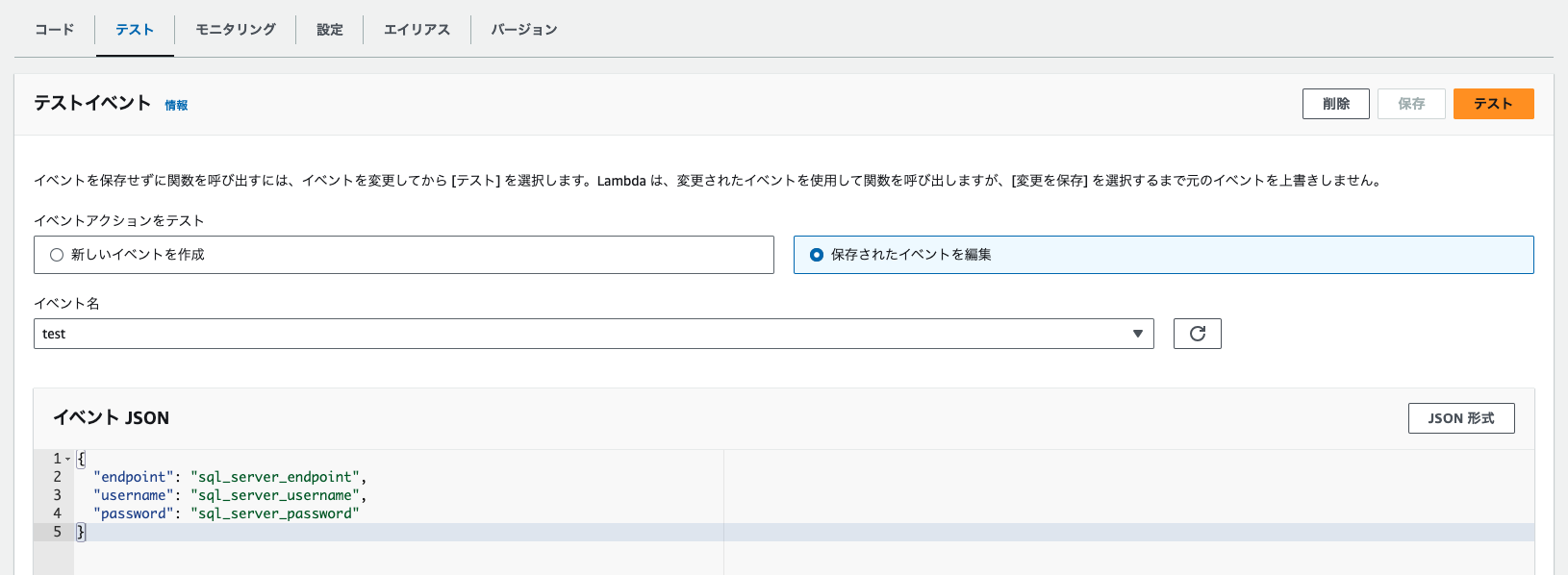
イベント記載ができたら、右上の「テスト」をクリックしてLambdaを実行します。
処理の内容にもよりますが、今回の場合は1~2秒で処理は終わりました。
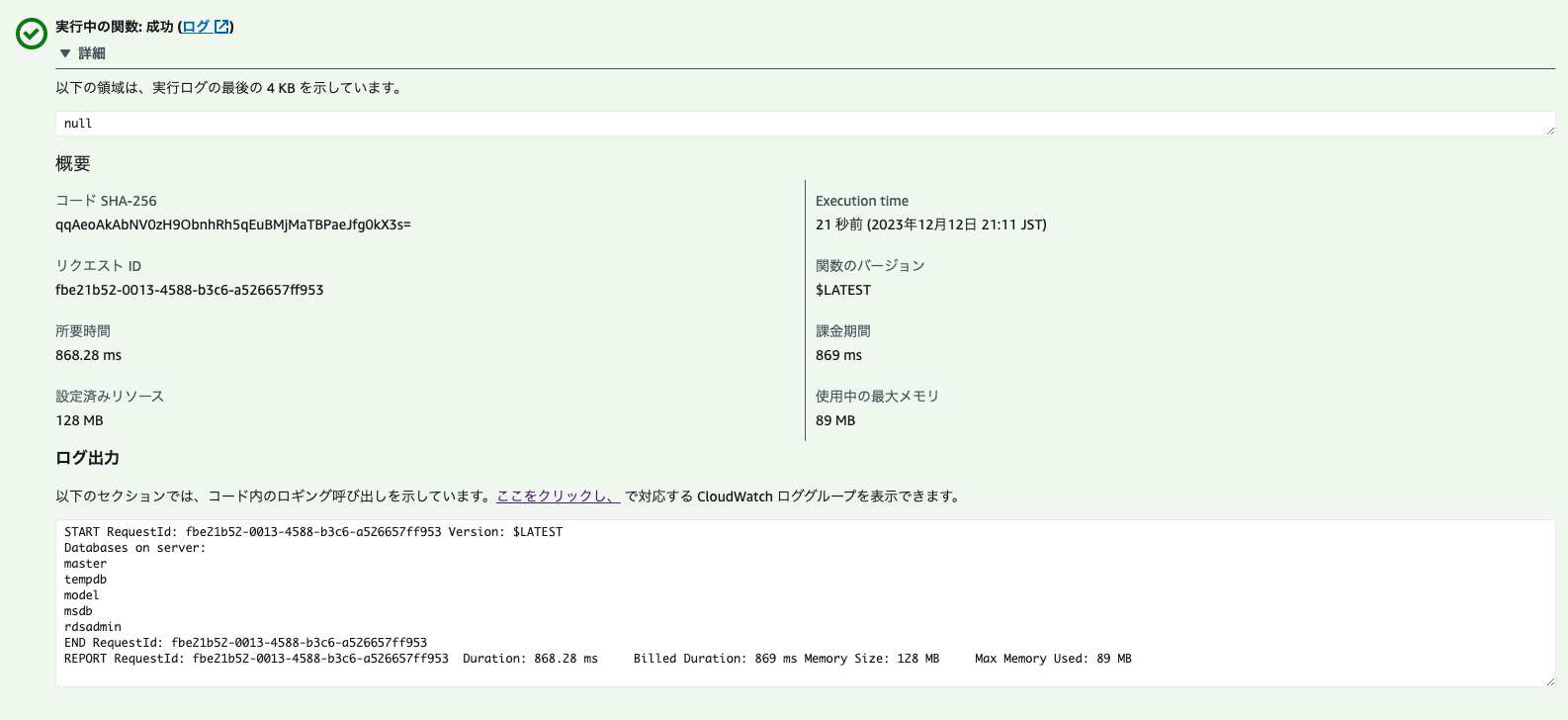
実行したログを見てみると、SQLサーバーのデータベース一覧が表示されていそうです。
できました!万歳!
まとめ
SQLサーバーに接続してSQL分を実行するLambdaをIaCで作成できました。
これをベースに、S3から実行するSQL分を取得したり、作成したデータベースの情報を格納したりできるLambdaも作っていけそうなので、改めて便利なサービスだなと感じました。
これからもAWSのサービスをいろいろ触ってみて、知見を深めていければと思っています。
Fusic Advent Calendar 2023はまだまだ続きますので、皆さんの記事も楽しみです!
参考