始めに
論文を英語の時間に読まなきゃいけなくなったが、どうにもモチベーションが……。
じゃあどうするか.
公開する気になったらちょっとは気乗りする気もしたので自分の言葉でもう一度構成しなおしてみる。(著作権的にもアレだし)
英弱が書いているの「ん?」ってなったら論文に行ってください。僕が間違っています(訂正リクエストお願いします。)
今回読むのはこれ
https://pdfs.semanticscholar.org/1324/80de063eeb5b39c1ed2f240b11dbfdcf455d.pdf
「Automatic Assessment of Japanese Text Readability Based on a Textbook Corpus」
論文というより正確にはカンファレンスの資料です。うちの教員の記事です。
簡単にではありますがまとめていくので、お付き合いください。
Readability 可読性に無頓着な日本
日本語はガラパゴス言語なので英語に比べていろいろ研究が遅れている(それはそう)。論文では"Readability"、可読性と翻訳しますがどのくらい読みやすいかというのを定量化しようぜって話。
英語にはいろんな可読性の指標があるのですが、日本語ではそういうことに無頓着らしく発展していない。ここでは英語の指標は省くが、Tateisi氏が提唱した式は以下。
$$RS = -0.12ls-1.37la+7.4lh-23.18lc-5.4lk-4.67cp+115.79$$
- $ls$ 1文に含まれる平均文字数
- $la$ ローマ字または記号の平均数
- $lh$ ひらがなの文字数の平均
- $lc$ 漢字の文字数の平均
- $lk$ カタカナの文字数の平均
- $cp$ 句読点の比率
使用したデータ
日本語において最もその可読性の評価がなされているのは教科書ではないか。子供の成長に合わせて厚生労働省と出版社ががんばっているに違いない。
ということで教科書を文書データとして用いた。これが小学校6年、中学校3年、高校3年の12段階になった。学年をそのまま答えとして用いる。
高校までだとそれはそれで問題なので大学の教科書も13段階目として、各大学で使われている教科書を学習データとして利用した。もちろん前の12段階とは質が異なることは忘れてはいけない。
学習
さて、ここで問題となるのが学習の仕方だ。英語の何が良いかというと単語ごとにスペースで区切られていることだ。日本語はどこからどこまでが単語なのか判別ができない。近年ではmecabをはじめとする日本語を単語に分割してくれるツールも発展してきた。しかしながら完全とはいいがたい。
そこで彼らが考えたのが、
「一文字ずつ区切ればいいんじゃね?」
そもそも日本語には素晴らしいことに表意文字である漢字が存在する。漢字に意味があるのなら、それそのまま単語みたいに扱ってしまおうというやや強引なやり方をつかった。
結果
これが上手くいく。正答率は0.9程度でRMSEもそこそこ良好。
| Case | 学習データ | 有効サンプル数 | 出力範囲 | R | RMSE |
|---|---|---|---|---|---|
| Case1 | 13-grade | 1167 | gr. 1-13 | 0.899 | 1.514 |
| Case2 | 13-grade | 1167 | gr. 1-12 | 0.907 | 1.440 |
| Normal leave-one-out | 12-grade | 1167 | gr. 1-12 | 0.905 | 1.800 |
一般的に文章が長くなれば可読性は悪くなる傾向にある為、文章が短くても正答率が出るようにしたい。
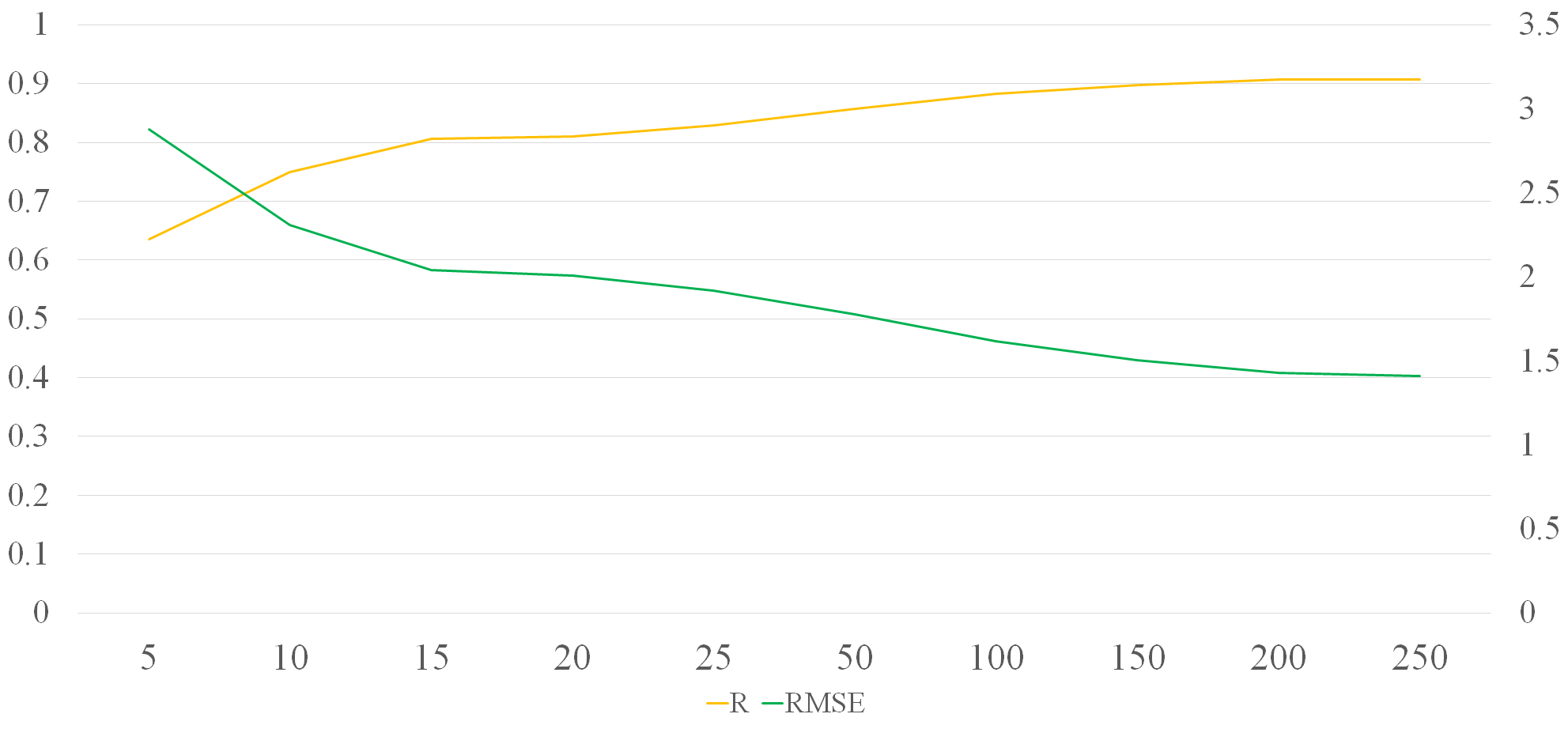
文字数が減ると正答率は下がるが、致命的までいかない。さすがに5文字しかなければ0.636でもよい方だと個人的に思う。
これがあそべるドン!!
これをツール化してwebページに上がっている。
http://kotoba.nuee.nagoya-u.ac.jp/sc/obi3/
結構楽しい。
自分の文章がどれくらいの学年なら読めるかの目安にもなる。
学校の先生とかであれば、国語の問題に使う文章を選定したりすることができるかもしれない。