スケジュールがめんどくさい
1440分の使い方という本は知っているだろうか?
一日の時間の使い方を説いた名著であり,僕はとても感銘を受けた.
本の内容については読んでくれ,Amazon Prime会員であれば無料で読めるのでぜひ.
この本に感銘を受け,僕は1日のスケジュールを毎日30分単位で作成していた.
一か月これを続け,その間はとても効率よく課題や勉強が進んだ.
効果については僕の1サンプルしかないが,少なくとも僕はとても充実した一か月を過ごすことができた.
問題点は一つだけある.
スケジュールを立てるのがめんどくさいのである
ただひたすらめんどくさい.
毎日これを立てるのに結構な時間がかかり,その上修正するのにも時間がかかる.
てめー時間が大事って言いながら時間かかる作業勧めてるんじゃねぇよと思いました.
機械にやらせよう
1440分の使い方ではブルジョアは秘書を雇ってスケジュールの管理をやらせるらしい.
僕らにはそんな金はないが,技術がある1
テクノロジーで解決してやるぜ
スケジューリング問題
スケジューリング問題の解法として数理最適化というものがある.
が,これは数学がちゃんとできなきゃいけないし,後々なんかワガママを言うたびにその式を変更しなくちゃいけない.
もうちょっと僕が楽して書けるものを探した結果,遺伝的アルゴリズムに至った.
なにより絶対無理な,最適解がない問題になってしまったときにも柔軟に解くことができる(最適ではないがより良い答えが出る)ことが一番の魅力である.
基礎的な内容は上のリンクを参考にしました.
あとここにリンクが貼られているスライドはとても分かりやすく助かりました.本当にありがとうございました.
概要
遺伝的アルゴリズムを用いてスケジューリング問題を解く.
入力変数
SCHEDULE: 例 [5, 3, 4, 2, 3, 2]
各日に使える工数の数.僕が個人的に25分作業して,5分休むというポモドーロテクニックを使用するため,一日何ポモドーロ使えそうかのリスト.
TASKS: 例{"Japanese": [4, 3, 1], "Math": [5, 4, 2], "English": [6, 5, 3]}
辞書型で,それぞれ見込み工数,期限(SCHEDULEのどこまでに終わらせるべきか),重要度(ペナルティの重さを決定)をリストで持つ.
符号化方法
今回は各工数にtaskに番号を振り分ける.
0を作業をしないFreeの枠として,TASKSの中身を順に1から番号を割り振る.
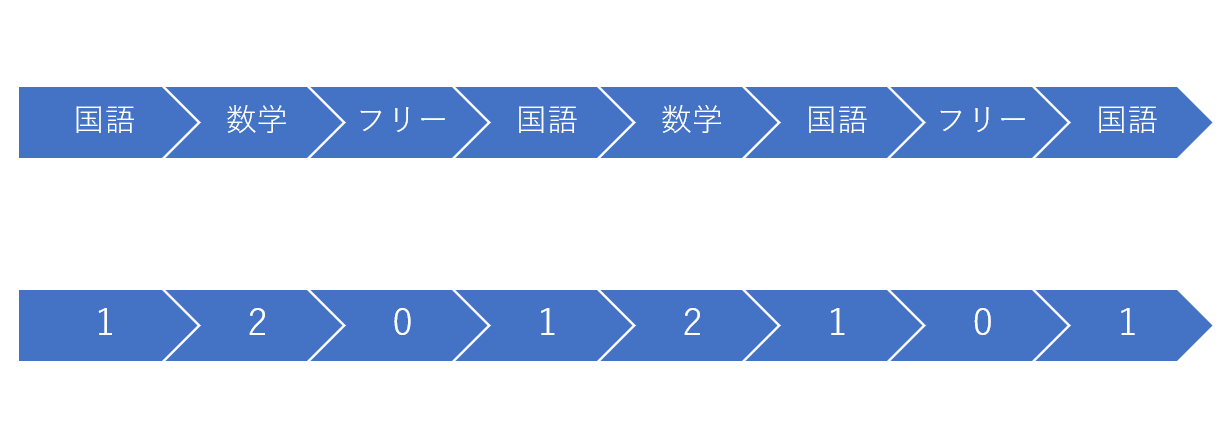
上の例であれば
[1, 2, 0, 1, 2, 1, 0, 1]
が1つの遺伝子情報となる.
評価方法
評価の軸は3つ挙げた.
- タスク超過ペナルティ
- 〆切超過ペナルティ
- 同一タスク連続ペナルティ
である.
タスク超過ペナルティは見込み工数以上の工数をスケジュールに割り付けてしまったときに発生する.これはスケジュールとして参考にならなくなるので最も大きなペナルティを課している.
〆切超過ペナルティは〆切の期日までに見込み工数のタスクを割り当てられなかったときに発生する.ペナルティの重さは重要度に比例する.
同一タスクペナルティは同じタスクが連続して続いてしまう場合に発生する.同一タスクが続くとモチベーションが下がるので,基本的に1ポモドーロやったらタスクを変えるようにしたい.
世代交代のアルゴリズム
子孫作成のアルゴリズム
最初はQiitaの記事に倣って二点交叉のエリート主義でやっていたが,ペナルティが0になるスケジュール案が複数ほしいなぁということになり,もっと多様性が持てて初期収束がしにくいアルゴリズムに変更した.
交叉の方法は一様交叉.
各遺伝子情報を50%の確率で入れ替えて子孫を作る.
世代交代は世代間最小ギャップモデルを採用した.
ランダムに取得した2つの親遺伝子から2つの子遺伝子を作り出しこの4つの遺伝子を一つの家族とする.
この家族の中から適応度の高い2遺伝子を次世代に残す.
自分でやっててめちゃくちゃ残酷なモデルだなぁと思った.
仕様
遺伝子集団の個数:100
突然変異の発生率:1%
各遺伝子の突然変異率:10%
コードの中身
class schedule_genom:
task_plan = None
penalty = None
def __init__(self, task_plan, penalty):
"""
:param task_plan こなすタスクのリスト
e.g.) [3, 2, 1, 0, 1, 2, 3, 2, 2, 3, 1]
:param penalty 評価関数の値
"""
self.task_plan = task_plan
self.penalty = penalty
def GetPlan(self):
return self.task_plan
def GetPenalty(self):
return self.penalty
def SetPlan(self, task_plan):
self.task_plan = task_plan
def SetPenalty(self, penalty):
self.penalty = penalty
クラスを作っておいてまぁなんかいい感じにする.
import GeneticAlgorithm as ga
import random
SCHEDULE = [5, 3, 4, 2, 3, 2]
GENOM_LENGTH = sum(SCHEDULE)
# {教科: [見込み工数, 期限, 重要度]}
TASKS = {"Japanese": [4, 3, 1], "Math": [5, 4, 2], "English": [6, 5, 3]}
MAX_GENOM_NUM = 1000
PROBABILITY_MUTATION = 0.01
PROBABILITY_GE_MUTATION = 0.1
MAX_GENERATION = 100
今回はTASKSとSCHEDULEをそのままグローバル変数として扱う.
毎回変数に食わせるのがめんどくさいから楽をしようとした結果です.ごめんなさい.
def create_genom(length):
"""
引数で指定された桁のランダムな遺伝子情報を生成し,格納したgenomClassで返す
:param length 使用可能な工数
:return schedule_genom
"""
task_plan = [random.randint(0, len(TASKS)) for _ in range(GENOM_LENGTH)]
return ga.schedule_genom(task_plan, penalize(task_plan))
最初の世代を作るための関数.タスクが全部期日までにこなせることが確定していれば順列な符号化ができたがそういう問題ばかりではないと思ってランダムからのスタートにした.
def penalize(plan):
"""
評価関数
:param plan:genomClassのスケジュールリスト
:return penalty
"""
penalty = 0
last_hour_of_the_day = []
# 〆切超過penalty rate:1000 * 重要度
# タスク超過penalty rate:10000
for i, key in enumerate(TASKS):
task = TASKS[key]
i += 1 # 0はFreeに充てるので一つずらす
remaining_hour = task[0] - plan.count(i)
if remaining_hour < 0:
penalty += -10000 * remaining_hour
deadline_over_hours = task[0] - plan[:sum(SCHEDULE[:task[1]])].count(i)
if deadline_over_hours > 0:
penalty += 1000 * task[2] * deadline_over_hours
# 同じタスクが続くpenalty rate:1
tmp = -1
sep_day = []
for hour_ in SCHEDULE:
tmp += hour_
sep_day.append(tmp)
for i in range(len(plan)-1):
if plan[i] == plan[i+1] and i not in sep_day and plan[i] != 0:
penalty += 1
return penalty
ここが一番厄介だった.スケジュールに基づき,日にちを跨いだら同一タスクが続いても良いことにしたりしたのでコードが汚い.
def crossover(ga_fst, ga_snd):
"""
交叉関数
:param ga_fst: 一つめの個体
:param ga_second: 二つ目の個体
:return progenies: 2つの子孫のリスト
"""
tmp = random.randint(0, GENOM_LENGTH)
cross_point = (tmp, random.randint(tmp,GENOM_LENGTH))
fst_plan = ga_fst.GetPlan()
snd_plan = ga_snd.GetPlan()
progeny_fst = []
progeny_snd = []
for fst_ge, snd_ge in zip(fst_plan, snd_plan):
if 0.5 >= random.random():
progeny_fst.append(fst_ge)
progeny_snd.append(snd_ge)
else:
progeny_fst.append(snd_ge)
progeny_snd.append(fst_ge)
return [ga.schedule_genom(progeny_fst, penalize(progeny_fst)),
ga.schedule_genom(progeny_snd, penalize(progeny_snd))]
一様交叉で子孫を作成している.子孫を作成する際,同時に適応度を計算している.
def next_generation_create(genoms):
"""
世代交代処理
: param genoms: 現行遺伝子集団
: return next_genoms: 次世代遺伝子集団
"""
next_genoms = []
random.shuffle(genoms)
for i in range(int(MAX_GENOM_NUM/2)):
fa = genoms.pop()
ma = genoms.pop()
family = crossover(fa, ma)
family.extend((fa, ma))
family = sorted(family, reverse=False, key=lambda u: u.penalty)
next_genoms.extend(family[:2])
return next_genoms
世代間最小ギャップモデルで家族を作り,適応度の高い2個体を残している.
popを使っているのでそのままこの関数にcurrent_genomsのアドレスを渡してしまうとぶっ壊して返すのでcopyメソッドを使うことを忘れない.
def mutation(genoms):
"""
突然変異関数
: param genoms:対象GenomClassのリスト
: return ga: 突然変異処理後のGenomClass
"""
mutated_genoms = []
for ga_ in genoms:
if PROBABILITY_MUTATION > random.random():
genom = []
for i_ in ga_.GetPlan():
if PROBABILITY_GE_MUTATION > random.random():
genom.append(random.randint(0, len(TASKS)))
else:
genom.append(i_)
ga_.SetPlan(genom)
ga_.SetPenalty(penalize(ga_.GetPlan()))
mutated_genoms.append(ga_)
else:
mutated_genoms.append(ga_)
return mutated_genoms
ランダムに置換型の突然変異を起こす.
if __name__ == '__main__':
# susus第一世代の生成
current_generation_genoms = []
for _ in range(MAX_GENOM_NUM):
current_generation_genoms.append(create_genom(GENOM_LENGTH))
for count_ in range(1, MAX_GENERATION + 1):
# 次世代の作成
next_generation_genoms = next_generation_create(current_generation_genoms.copy())
# 突然変異
next_generation_genoms = mutation(next_generation_genoms)
# 評価
fits = [ga_.GetPenalty() for ga_ in current_generation_genoms]
print("-------第{}世代-------".format(count_))
print("Min:{}".format(min(fits)))
print("Max:{}".format(max(fits)))
print("Avg:{}".format(sum(fits)/MAX_GENOM_NUM))
current_generation_genoms = next_generation_genoms
next_generation_genoms = sorted(next_generation_genoms, reverse=False, key=lambda u: u.penalty)
# print("最も優れた個体")
for i in range(fits.count(0)):
keys = ["Free"] + list(TASKS.keys())
prev = 0
next = 0
best_ = [keys[i] for i in next_generation_genoms[i].GetPlan()]
transformed_plan = []
for hour_ in SCHEDULE:
next += hour_
transformed_plan.append(best_[prev:next])
prev = next
print(transformed_plan)
元記事よりかなり短いコードとなった世代交代とかをすべて関数に任せた結果ですね.
ループとしては,次世代作成と突然変異を繰り返すだけになりました,
最後はペナルティが0になったスケジュールを吐き出すようになっている.
走らせた結果
-------第100世代-------
Min:0
Max:12003
Avg:301.74
[['Japanese', 'Math', 'Japanese', 'English', 'Free'], ['Japanese', 'Free', 'Japanese'], ['Math', 'English', 'Math', 'English'], ['Math', 'English'], ['Math', 'Free', 'English'], ['Free', 'English']]
[['Math', 'Japanese', 'English', 'Japanese', 'Math'], ['Japanese', 'Math', 'Free'], ['Japanese', 'Math', 'English', 'Free'], ['English', 'Math'], ['English', 'Free', 'English'], ['Free', 'English']]
[['Japanese', 'English', 'Math', 'English', 'Math'], ['Japanese', 'Math', 'Japanese'], ['English', 'Free', 'Free', 'Math'], ['Japanese', 'English'], ['Free', 'English', 'Math'], ['English', 'Free']]
[['Math', 'English', 'Math', 'English', 'Math'], ['Japanese', 'English', 'Japanese'], ['Math', 'English', 'Japanese', 'Free'], ['Math', 'Japanese'], ['English', 'Free', 'Free'], ['English', 'Free']]
[['Japanese', 'English', 'Math', 'Japanese', 'English'], ['Free', 'Math', 'Japanese'], ['English', 'Math', 'Free', 'Free'], ['Japanese', 'English'], ['Math', 'English', 'Math'], ['English', 'Free']]
[['Japanese', 'English', 'Math', 'Free', 'Free'], ['Japanese', 'English', 'Japanese'], ['English', 'Math', 'Free', 'Math'], ['Japanese', 'English'], ['Math', 'English', 'Math'], ['Free', 'English']]
[['Math', 'Japanese', 'Math', 'English', 'Free'], ['Japanese', 'English', 'Japanese'], ['Japanese', 'English', 'Free', 'Math'], ['Math', 'English'], ['English', 'Free', 'Math'], ['Free', 'English']]
[['Math', 'English', 'Math', 'English', 'Math'], ['Japanese', 'English', 'Japanese'], ['Japanese', 'English', 'Free', 'English'], ['Japanese', 'Free'], ['Math', 'English', 'Math'], ['Free', 'Free']]
[['Math', 'Japanese', 'English', 'Math', 'English'], ['Japanese', 'Math', 'Japanese'], ['Math', 'Japanese', 'English', 'Free'], ['English', 'Math'], ['English', 'Free', 'Free'], ['Free', 'English']]
[['Japanese', 'English', 'Math', 'Japanese', 'English'], ['Free', 'Math', 'Japanese'], ['English', 'Free', 'Free', 'Math'], ['Japanese', 'English'], ['Math', 'English', 'Math'], ['English', 'Free']]
10個体が吐き出されました.
意外と多様性のある結果になりました.
〆切を考えて英語を後ろにうまく残す感じができているのが良いですね.
それでいて一日目に英語のタスクをやっている日もあってバランスもとれている.
毎回結果が変わってしまうので毎回10個体も出てくるかどうかはわからないのですが,まぁ一個くらいは出てくるでしょう.
今後はこのロジックを使ったアプリケーションとかの開発をしていきたいです.
使いたい方はここからクローンしてください.
https://github.com/KesukeSakai0222/scheduling_by_ga
-
多分技術があるはずです.突っ込まないでください ↩