大量の書き込みトラフィックを処理しなくてはならないようなWebサービス(例えばスマホゲーム向けAPIサーバー等)だとDB(RDBMSやNoSQL)を水平分割していることも多いと思います。
例えばユーザーIDで水平分割されているシステムであるユーザーのフレンド50人を一覧表示する場合、ユーザーの情報を50人分取得する必要がありますが全ユーザーが同じDBに収容されているわけではないためサブクエリやIN句で一気に取ってくることができません。
ではどのようにして取得するでしょうか?
1. シーケンシャルに一人ずつ取ってくる?
例えば50人のユーザーIDリストがあったとして、一人ひとり収容されているDBのコネクションを取得してSQLを発行してデータを取得するのはどうでしょうか
以下のようなコードになりそうです(実際に動くコードではありません)
public List<UserInfo> getUserInfo(List<UserId> friendUserIdList) {
var builder = ImmutableList.<UserInfo>builder();
for (UserId friendUserId : friendUserIdList) {
// friendUserIdに対応したDBコネクションを取得
try (DbConnection con = userDbTransactionManager.startSessionByUserId(friendUserId)) {
UserInfo userInfo = userInfoRepository.selectByUserId(con, frinedUserId); // DBからUserInfoオブジェクトを取得
builder.add(userInfo);
}
}
return builder.build();
}
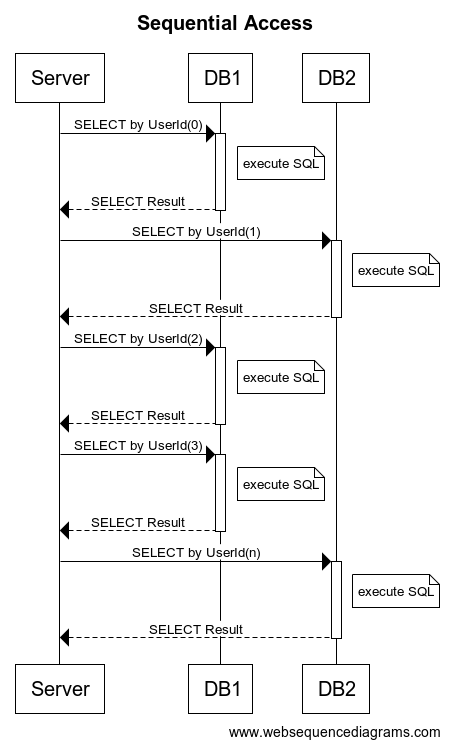
実際に動くコードを組んでやってみるとわかると思いますが、これは非常に遅いです。
50回分アプリケーションサーバーとDB間を通信が行き来してSQLの実行時間もその分累積されるためこのメソッドの実行時間は非常に長くなってしまいます。
よく考えてみると(考えなくても?)これは典型的なN+1ですよね・・・
2. 同じシャード(DB)に格納されているユーザーをまとめて取得する?
前項と同じように50人のユーザーIDリストを渡されたらまずリストをシャードごとに分割して同じシャードのユーザーをまとめて取得するようにします。
public List<UserInfo> getUserInfo(List<UserId> friendUserIdList) {
// ユーザーIDリストをシャード(DB)ごとのリストに分割する
Map<ShardId, List<UserId>> userIdMap = shardManager.groupByShardId(friendUserIdList);
var builder = ImmutableList.<UserInfo>builder();
for (Entry<ShardId, List<UserId>> entry : userIdMap.entrySet()) {
final ShardId shardId = entry.getKey();
// ShardId(DBのシャードを表すID)に対応したDBコネクションを取得
try (DbConnection con = userDbTransactionManager.startSessionByShardId(shardId)) {
// ユーザーIDリストからIN句やサブクエリを用いて効率よくUserInfoオブジェクトを取得してくる
List<UserInfo> userInfoList = userInfoRepository.selectByUserIdList(con, entry.getValue());
builder.addAll(userInfoList);
}
}
return builder.build();
}
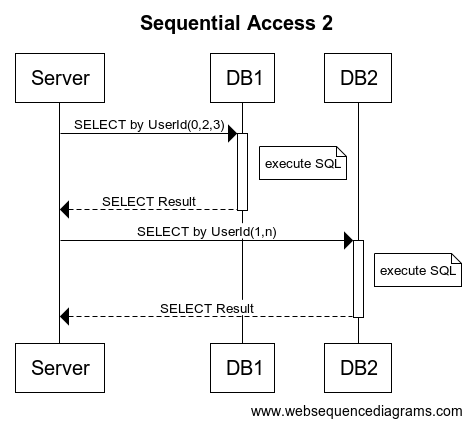
これはちょっと速くなったんじゃないでしょうか?
ユーザーがシャード毎にまとまった分サーバーとDBの往復が減ってメソッドの実行時間が短縮されるはずです。
でもシャード数が増えると同じシャードに入っている確率が下がる(※)ので一人ずつの場合に近い状態になってしまいます・・・
※50人がバラバラのシャードに分散されている可能性が高くなるのでuserIdMap.entrySet().size()が50に近づいてしまう
3. 2をマルチスレッドで実行してみる
さてここからが本題です上記2のfor文の中身をマルチスレッドで並列実行することで複数のサーバーとDBの往復通信時間とSQL実行時間を隠ぺいします。
public List<UserInfo> getUserInfo(List<UserId> friendUserIdList) {
// ユーザーIDリストをシャード(DB)ごとのリストに分割する
Map<ShardId, List<UserId>> userIdMap = shardManager.groupByShardId(friendUserIdList);
CompletableFuture<List<UserInfo>>[] cfs = new CompletableFuture[userIdMap.entrySet().size()];
int index = 0;
for (Entry<ShardId, List<UserId>> entry : userIdMap.entrySet()) {
final ShardId shardId = entry.getKey();
CompletableFuture<List<UserInfo> cf = CompletableFuture.supplyAsync(() -> {
// ShardId(DBのシャードを表すID)に対応したDBコネクションを取得
try (DbConnection con = userDbTransactionManager.startSessionByShardId(shardId)) {
// ユーザーIDリストからIN句やサブクエリを用いて効率よくUserInfoオブジェクトを取得してくる
List<UserInfo> userInfoList = userInfoRepository.selectByUserIdList(con, entry.getValue());
return userInfoList;
}
}, executor); // デフォルトだとForkJoinPoolが使われるので独自のExecutorを利用する(後述)
cfs[index] = cf;
index++;
}
CompletableFuture.allOf(cfs).join();
var builder = ImmutableList.<UserInfo>builder();
for (CompletableFuture<List<UserInfo>> cf : cfs) {
builder.addAll(cf.get());
}
return builder.build();
}
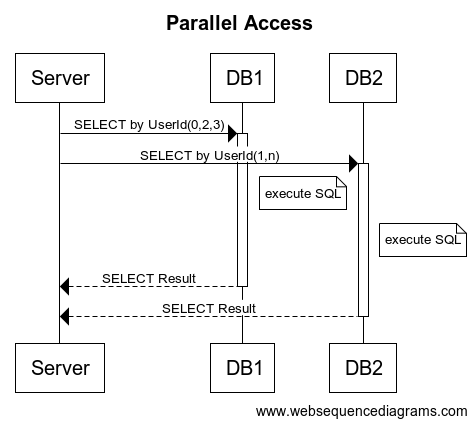
これでかなり高速になったはずです。
ちょっと複雑なように見えますが2のfor文の中身をJava8から導入されたCompletableFutureに関数として渡すことでマルチスレッド化しているだけです。(戻り値をまとめるために後ろにちょっとコードがついてますが・・・)
Appendix
CompletableFuture#supplyAsyncの第二引数にExecutorを指定している理由
Java8のマルチスレッド処理フレームワークは裏でExecutorというスレッドを制御するクラスからスレッドを取得して実行しています
デフォルトだとForkJoinPoolというJavaを実行しているCPUのコア数に合わせたスレッド数に制御してくれるクラスを利用します。
一見それでよいように思えてしまいますが、DBアクセス中はサーバー側のCPUはただDBからの戻りを待っているだけなので別の処理ができます。なのでCPUコア数にとらわれずもっと多数のスレッドで処理させた方が効率が上がります。
簡単にExecutor(もしくはExecutorを実装したExecutorService)を作るのであればjava.util.concurrent.Executorsというユーティリティクラスがあるので、例えばnewFixedThreadPool(int nThreads)というメソッドを使えばnThredsで指定したスレッド数のExecutorが簡単に作れます。(ただし実際のプロダクトにマッチするかはケースバイケース)
実際のプロダクトで使う際は負荷や用途に合わせてExecutor(ExecutorService)を自作するのもよいでしょう。
キャッシュすればいいのでは?
確かにUserInfoをRedisのような高速なKVSにキャッシュすることで高速化することも可能でしょう。
ただ、今回の例ではユーザーのフレンド一覧ということになっていますキャッシュはある程度参照の局所性がある場合は効果的ですが、ユーザーのフレンド一覧に参照の局所性があるでしょうか?
フレンドは参照の局所性がないデータなので、キャッシュミスをしてDBに取りに行く頻度が高くなります。なのでDBに取りに行った場合でも高速にレスポンスが返せるように設計しておくことが重要と考えます。