はじめに
あるソーシャルゲームでガチャを大量に引いて必要なアイテムか目視でチェックしていた。
とても目を酷使するのでガチャの結果を画像ファイルにして必要なアイテムかOCRで自動判別するプログラムを書いたのだが、OCRの認識結果を表示するだけのサンプルプログラムが簡単に見つからなかったのでまとめた。
環境
- EasyOCR 1.7.1
- pillow 10.3.0
- Python 3.9.13
- Windows 10 Pro (64bit) 22H2
EasyOCR, pillowモジュールのバージョンを確認するコマンド
python3 -m pip show easyocr pillow
標準で日本語に対応しているとのことでEasyOCRを今回は選択しただけで、深い理由はない。
なお、OCRライブラリによっては標準で認識結果を表示する機能もあるらしい
画像の加工はpillowを使用。opencvを利用する方法もあるようだが、今回の用途ではpillowで十分と判断した
OCR処理して認識結果を表示
import easyocr
from PIL import Image, ImageDraw
RED = (255, 0, 0)
fname = "sample.png" # 処理するファイル名
reader = easyocr.Reader(['ja','en']) # 文字の選択
img = Image.open(fname)
draw = ImageDraw.Draw(img)
# OCR処理をする
res = reader.readtext(fname)
# OCRの各認識結果を赤枠で囲う
for b in res:
(rect, txt, posi) = b # rect = [[x1, y1], [x2, y1], [x2, y2], [x1, y2]]
# txt:認識文字
(x1, y1) = rect[0]
(x2, y2) = rect[2]
xy = (x1, y1, x2, y2) # xy = ((x1, y1), (x2, y2)でもよい
# 認識したBoundary Boxを四角で囲う
draw.rectangle(xy, outline=RED, width=3)
# 認識結果を赤枠で囲った画像を表示する
img.show()
注意点としては、EasyOCRが返してくる座標情報の形式とpillowで使用する座標情報の形式が異なるので若干の変換が必要な点だけ。
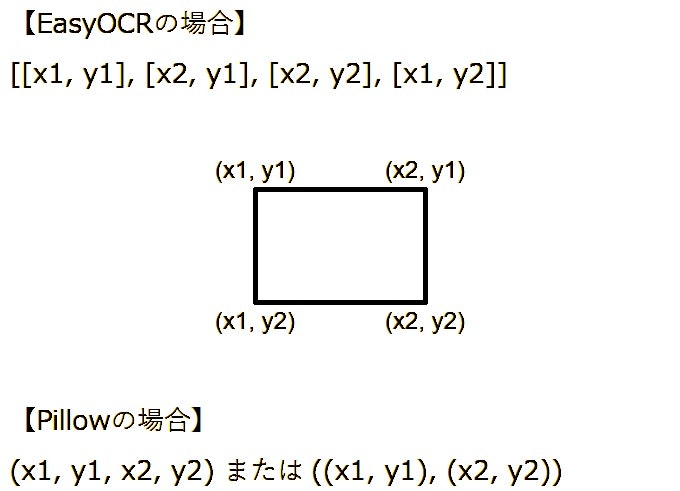
例えば、左上の座標が(x1, y1)で右下の座標が(x2, y2)の方形範囲でもEasyOCRは [[x1, y1], [x2, y1], [x2, y2], [x1, y2]]という形式(4点指定)で返してくるが、pillowでの入力パラメータでは (x1, y1, x2, y2)あるいは ((x1, y1), (x2, y2))という形式(2点指定)になる