はじめに
SVMを使って、世界合計のGDPを年度から予想します。
今回の予想は2つのことを仮定をしています。
・世界経済は成長し続けるものとする。
・今後予想できないような、急激な経済成長は考えないものとする。
データをゲットする
IMFが世界経済の推移をcsvで配布していますのでそれをダウンロードします。
データ
①最新年度を選んで、By Country Groups (aggregated data) and commodity pricesをクリック。
②worldのみチェックを入れる
③Gross domestic product, current prices U.S. dollarsにチェックを入れる
④下のほうの所からエクセルファイルをダウンロード。
⑤データを加工する。(そこそこ、大変でした)
出来れば、加工後を載せたいのですが、再配布していいのかちょっと微妙なのでIMFのサイトからダウンロードしてください。
注意
上記のファイルのGDPの単位は10億米ドルです。
よって、上記のファイルをそのまま使うとGDPの単位が10億米ドルとなります。
ソースコードを書く
さて、pythonとscikit-learnでソースコードを書きたいと思います。
import sys
from sklearn.svm import LinearSVC
from sklearn import svm
import numpy as np
import copy
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from sklearn.kernel_ridge import KernelRidge
from sklearn.metrics.pairwise import rbf_kernel
from sklearn.linear_model import Ridge
args = sys.argv
def regression_main():
# model = svm.SVR(kernel='rbf', C=1e3, gamma=0.1)
data=[]
with open(args[1],"r",encoding="utf-8") as f:
data=[e.replace("\n", "") for e in f.readlines()]
data=[[float(e) for e in e.split(",")] for e in copy.deepcopy(data) ]
in_data=[e[:-1] for e in data]
label_data=[e[-1] for e in data]
print(in_data,label_data)
tuned_parameters = [
{'kernel': ['rbf'], 'gamma': [10**i for i in range(-4,5)], 'C': [10**i for i in range(-3, 8)]}#,
# {'kernel': ['linear'], 'C': [1, 10, 100, 1000]}
]
model = GridSearchCV(svm.SVR(), tuned_parameters, cv=5, scoring="mean_squared_error")
model.fit(in_data,label_data)
plt.scatter([e[0] for e in in_data], [e for e in label_data])
plt.plot([e[0] for e in in_data], model.predict(in_data))
plt.show()
while True:
user_input=input("end?>")
if user_input=="end":break
user_in_data=[]
for i in range(len(in_data[0])):
t=float(input(">"))
user_in_data.append(t)
print(model.predict([user_in_data])[0])
def main():
print("1:label\n2:回帰")
n=int(input(">"))
if n==1:
#label_main()
if n==2:
regression_main()
main()
種も仕掛けもない普通のソースコードです。
ただ、パラメーターを色々微調整するのが面倒くさいのでGridSearchCVで自動的に最適化しています。
実行する時は
python main.py 学習ファイル
です
学習データのフォーマット
データの加工の行い方を載せてないので代わりに学習データのフォーマットを載せておきます。
引数1,引数2,引数3...,出力
引数1,引数2,引数3...,出力
...
こんな感じですので今回の場合は
年度,世界合計GDP
年度,世界合計GDP
...
です。
実行する
実行してみたいと思います。
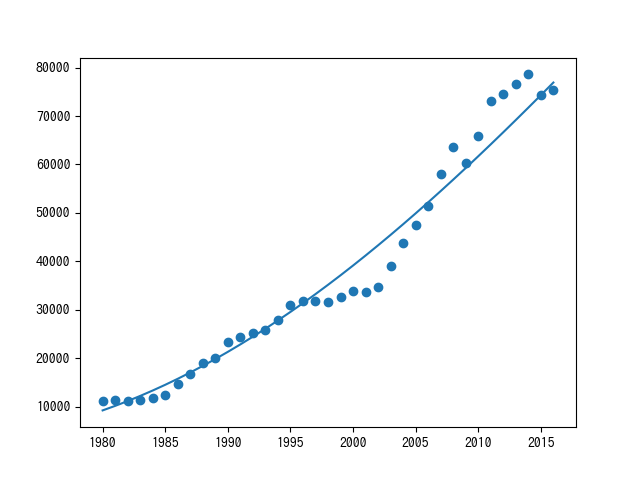
青い丸が実際の世界のGDPで青い線がSVMの予想値です。
ほぼ、一次関数ですね...
わざわざ、SVMを使った意味がない気もします。
とにかく、このモデルを使って、予想してみたいと思います。
予想してみる。
では早速、2022と入力して2022年を予想してみたいと思います。
出力は929482.95366億米国ドルでした。
IMFの予想は1032009.94億米国ドルでしたので、
一応予想が出来ました。
まとめ
今回のデータは一次関数が当てはまったので余りSVMの恩恵が得られませんでした。