この記事はPhysics Lab. 2022 Advent Calendar 17日目の記事です。
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$
0. はじめに
はじめまして!Physics Lab. 2022 副統括、幾何班・量子物理学班所属のシャーペンといいます。
最初にPhysics Lab. 2022の宣伝を…
Physics Lab. 2022は物理学科有志による五月祭企画(5/14(土), 15(日))で、オンライン(virtual 会場)と対面の両方で開催される予定です。
様々な方にきっと物理の面白さを感じて頂けるようなものを準備してお待ちしておりますのでぜひお越しください!
さて、今回、Advent Calendarの記事として量子誤り訂正の気持ち的な所を簡単に紹介したいと思います。では、さっそく本編に入っていきましょう!
1.目的
今回は量子コンピュータの具体的な物理的実装や量子計算の厳密な定式化などは避けて、数学パズルとしてどういったことをやっているかを説明したいと思います. 流れとしては,
2. 準備(量子状態と測定)
3. 古典誤り訂正
4. 量子誤り訂正の基本(メイン)
となります.
なお、線形代数の基礎的な所(基底, 次元, 部分空間, 射影等)を前提知識として仮定しています。
これは個人的な考え方ですが、記事や参考書には少なからず著者の解釈や物事を見る角度というものが反映されるので、同じものについても様々な教科書・記事を読んでみることをお勧めします。そのため、参考文献に挙げているようなものや、量子誤り訂正についていくらか出ている教材もぜひ参考にしてみてください。
本記事も量子誤り訂正についての理解の一助となれば幸いです。
2.準備
2.1 状態
量子コンピュータの状態や測定についてはIBMなどが提供している教材等のほか、インターネット上にも多くの記事が充実しているため、細かい説明はそちらに譲って、必要なものだけ定義していきます。
まず、量子コンピュータの情報の基本単位はqubitです。
これは古典コンピュータのビットに対応しています。
古典コンピュータのビットは$0$または$1$の状態しかとる事が出来ませんが、
qubitは$\ket{0}$と$\ket{1}$を基底とした$2$次元複素数空間の単位球面上、すなわち
$$
{ \alpha\ket{0}+\beta\ket{1},\qquad \bigl(\alpha,\beta\in\mathbb{C},\quad \lvert\alpha\rvert^2+\lvert\beta\rvert^2=1 \bigr) }
$$
と書かれる状態すべてを取る事が出来ます。ただし, 絶対値が$1$の複素数をかけて一致するものは同一の状態とみなされます。すなわち、$\ket{\psi}\sim c\ket{\psi}$ $(|c|=1, c\in\mathbb{C})$です。
なお, 厳密には物理的に取る状態は古典的な混合状態と合わせて密度行列と$1$対$1$に対応し、上記のような形で書かれるものは純粋状態と言われます。$\ket{0}$と$\ket{1}$で張られる空間を$1$qubitの状態空間と呼びます。
次に、$n$ qubit $(n\geq 2)$の状態空間はこれらのテンソル積空間で表され, 取り得る状態はその単位球面上になります。テンソル積を知らなくてもこの場合は有限次元ですし直感的に理解は難しくありません。$n$桁のビット列としてあり得る$2^n$個それぞれに対応する基底が存在してどの$2$つも互いに直交するとし、それらによって張られる空間の事です。例えば, $n=2$ならばあり得る状態は
$$
{ \alpha\ket{00}+\beta\ket{01}+\gamma\ket{10}+\delta\ket{11},\qquad \bigl(\alpha,\beta,\gamma,\delta\in\mathbb{C},\quad \lvert\alpha\rvert^2+\lvert\beta\rvert^2+\lvert\gamma\rvert^2+\lvert\delta\rvert^2=1 \bigr) }
$$
と書く事が出来ますし、$n=3$ならば状態空間は$\ket{000}$, $\ket{001}$, $\ket{010}$, $\ket{011}$, $\ket{100}$, $\ket{101}$, $\ket{110}$, $\ket{111}$の$2^3=8$つの基底によって張られる$8$次元の空間です.
2.2 測定
次に測定についてです。今回はZ測定とX測定およびそれらを複数ビットにわたって測定するもののみを考えます。測定についても測定型量子計算など様々な面白い話があるのですが、今回は割愛します。
まず、最初にZ基底, X基底とはそれぞれパウリZゲート, パウリXゲートの固有状態で、具体的には$\ket{0},\ket{1}$をZ基底、$\ket{+}=\frac{1}{\sqrt{2}}(\ket{0}+\ket{1}),\ket{-}=\frac{1}{\sqrt{2}}(\ket{0}-\ket{1})$をX基底とよびます。Z測定, X測定はそれぞれの基底についての 射影測定 です。これは次のようなものをさします。
$\ket{\psi}=\alpha\ket{0}+\beta\ket{1}$とZ基底を用いて表されるとします。
これをZ測定すると, $\lvert\alpha\rvert^2$の確率で$0$, $\lvert\beta\rvert^2$の確率で$1$が結果として得られます。確率は測定結果をみたす空間に射影したときのノルムの$2$乗値と一致します。ここで大事なのは、測定後に状態が射影$\to$ 正規化される事です。つまり、$0$を結果として得たならば、元々$\ket{\psi}$だった状態は$\ket{0}$に、$1$を結果として得たならば$\ket{1}$へと変化します。測定も状態に影響を与えるというこの性質は量子コンピュータ特有のものです。
X測定は上の$\ket{0}$, $\ket{1}$を$\ket{+}$, $\ket{-}$に変換したものです。得られる測定結果は$\ket{+}$に$0$, $\ket{-}$に$1$が対応し、X測定においても$0$または$1$の測定結果を得ます。
ここで簡単な練習問題です。$\ket{\psi}=\frac{\sqrt{3}}{2}\ket{0}+\frac{1}{2}\ket{1}$をX測定するとどうなるでしょうか?
まず, $\ket{\psi}=\frac{\sqrt{6}+\sqrt{2}}{4}\ket{+}+\frac{\sqrt{6}-\sqrt{2}}{4}\ket{-}$と書けます。これは上の$\ket{+}$, $\ket{-}$を代入すれば分かります。これより、$\left\lvert\frac{\sqrt{6}+\sqrt{2}}{4}\right\rvert^2=\frac{2+\sqrt{3}}{4}$の確率で$0$を結果として得て、その後の状態は$\ket{+}$となります。また、$\left\lvert\frac{\sqrt{6}-\sqrt{2}}{4}\right\rvert^2=\frac{2-\sqrt{3}}{4}$の確率で$1$を結果として得て、その後の状態は$\ket{-}$となります。
より一般には, 射影測定では状態空間の中である状態を表す(正規化された)ベクトルに対して, 測定演算子の固有空間への長さの $2$ 乗が測定確率となり、測定後の状態は測定結果に対応する固有空間にそのベクトルを射影したものを正規化したものとなります. (ここでは、そういう枠組みで考えると実際と一致するのでそう考える, という認識で大丈夫です. ) 特に, 測定後の状態は測定結果に応じた固有空間に含まれます.
複数のqubitの場合は測定した結果のxorを得ることができます。ここでxorとは排他的論理和のことをさし、$0 xor 0=1 xor 1=0$, $0 xor 1=1 xor 0=1$ となります。
今回の記事の中では扱う測定では、測定結果は $0$ または $1$ で表されます。
測定結果が $0$ の時固有値 $1$ に対応する固有状態、$1$ の時固有値 $-1$ に対応する固有状態
になるものとします。
例えば、次のようになります。
$$
{ \alpha\ket{00}+\beta\ket{01}+\gamma\ket{10}+\delta\ket{11}}
$$
と書かれた状態に対して、$Z_1Z_2$測定を行う事を考えます。
$Z_1Z_2$とはqubit $1,2$ に対してZ測定を行うという事です。これは$1$回の測定でxorした後の結果だけ得られ、個別に測定してあとでxorをとったものとは意味合いが全く異なる事に注意してください。
(得られる測定結果の確率分布は等しいですが、測定後の状態が異なります。このような場合、測定として異なると考えます。)
測定結果が$0$となる状態は$\ket{00}$, $\ket{11}$の$2$つの状態で張られた空間の状態です。
測定結果が $0$ となる確率は $\sqrt{\lvert\alpha\rvert^2+\lvert\delta\rvert^2}$ であり、測定後の状態は射影ですから、$\ket{\psi}^0_{after}=\frac{\alpha}{\sqrt{\alpha^2+\delta^2}}\ket{00}+\frac{\delta}{\sqrt{\alpha^2+\delta^2}}\ket{11}$となります。
同様に測定結果が$1$となる確率は$\sqrt{\beta^2+\gamma^2}$であり測定後の状態は$\ket{\psi}^1_{after}=\frac{\beta}{\sqrt{\beta^2+\gamma^2}}\ket{01}+\frac{\gamma}{\sqrt{\beta^2+\gamma^2}}\ket{10}$となります。
$1$qubitのときとの違いとして、$1$ qubitのときは次元が$2$に対してあり得る状態の次元を$2$分の$1$に絞った事により測定後の状態が完全に$\ket{0}$か$\ket{1}$(または$\ket{+}$か$\ket{-}$)と定まってしまい、$\alpha$や$\beta$が消えてしまったのに対して、今回は次元が$4$に対して$2$つずつの基底からなる空間に分けたため、比の形で部分的に測定前の情報が残っているというのが分かると思います。
ここで、注記ですが、$\ket{0}$, $\ket{1}$はZゲートに対する固有状態 $(Z\ket{0}=\ket{0}, Z\ket{1}=-\ket{1})$ であって、$Z$ゲートをかけるとたがいに移り合う状態ではないということに注意してください。
3.古典誤り訂正
3.1 誤り訂正とは
古典誤り訂正について、今後の話で必要になるところだけまとめます。
古典誤り訂正はそのまま量子誤り訂正に適用するにはいくつかの困難があるにもかかわらず、
その技術や考え方の多くの点が量子誤り訂正に活かされています。
まず、そもそも誤り訂正で想定している誤りとは、アルゴリズム起因などで理論的に入るものではありません。
コンピュータに物理的な実在がある以上、ビット(量子コンピュータであればqubit)の情報の担い手であるものが何らかの理由(ゆらぎや、他にも(二次)宇宙線の衝突など)によって確率的に理論的に想定されたものとは異なる挙動をしてしまう事が考えられます。こういう時にそのエラーが計算結果に影響を与える確率を抑えて実用上問題無いようにしようというのが誤り訂正です。ここで、例えば確率を$10^{-30}$とかにしようと言っているのであって、$0$にすると言っているわけでは無い事に注意してください。たとえ、どんなに注意して状態を分けたとしても、(それこそ猿がシェイクスピアの作品を打ち出すくらいの)ものすごい低確率で一方から他方に移り合う事が出来てしまうはずだからです。
3.2 多数決
さて、その具体的な手法を紹介しましょう。とてもシンプルな例としては多数決があります。
これは計算前のビットをコピーして、奇数個、例えば$3$つに分け、それぞれについて計算を行います。
そして得られた結果のうち多いものを結果として採用します。
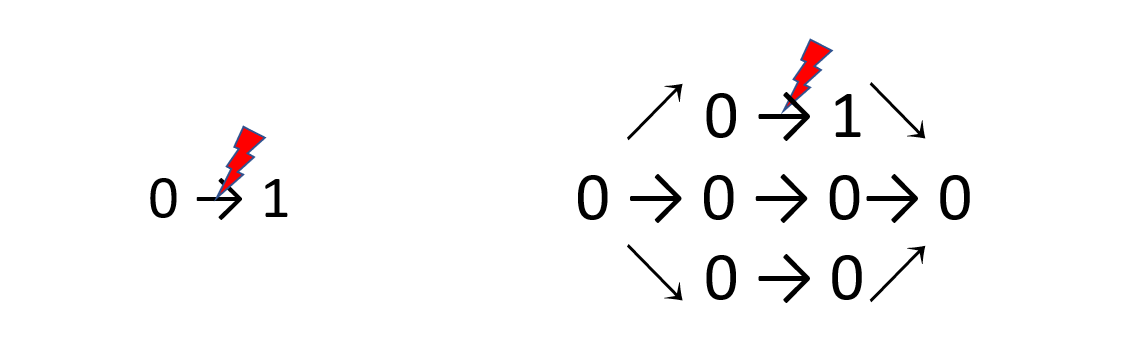
上の赤いノイズは意図的な操作ではなくエラーです。(念の為)
それぞれのビットが独立に確率$p(\ll 1)$でエラーを起こすとして、この訂正手法を使ったときと使わなかった時それぞれで計算結果が誤ってしまう確率はいくつでしょうか。過程は簡単な高校数学なので省略するとして、それぞれ$p$と$3p^2-2p^3$となります。ここで、$p\ll 1$としているので、$3p^2-2p^3<p$となります。具体的な数値を代入してみると、例えば$p\sim 10^{-5}$であれば、前者では$\sim 10^{-5}$ですが、後者では$\sim 10^{-10}$となります。
これは極めてシンプルな例ですが、誤り訂正における用語を導入するには十分良い例といえます。
その前に、この訂正について肝要な点に $1$ つ触れておきます。
ここで、この訂正は計算中に何度でも行えることが大事です。もし、複雑な計算を行う際、最後にのみこの訂正を行おうとした時、(現在の古典ビットではすでにそこまで精度は低くないのですが、)それまでに起きるエラーの確率は大きかったとするとすでに手遅れ、すなわち、$0$ と $1$ がランダムに混ざり合った状態になってしまいます。しかし、$1$ ステップ計算を行うたびに訂正を行えば、それぞれの段階でエラーが起きているビットの数は少なく、最終的なエラー率は小さくなります。
また、厳密には非自明な話ですが、訂正を行わずともどのタイミングでどこにエラーが起きたか推定までできていればそこからの影響を逆算して結果を訂正することができます。例えば $101$ 個のビットで計算を行った時、最終的に$0$ が $50$ 個, $1$ が $51$ 個 となっていたという情報だけでは $0$ と $1$ のどちらが正しい計算結果であるかはかなり怪しいです。しかし、途中過程で $0$ が $20$ 個, $1$ が $81$ 個となっており、その $20$ 個のうちほとんどが最終結果 $1$ となったとすると、途中過程の時点では明らかに正しい中間過程は $1$ である可能性が高く、まだエラーが起きていなかったと考えられる $81$ 個のうち多くが属する$0$ の方が最終結果として尤もらしいと言うことになります。
これをより細かく分けていけば、各ステップでどのビットがエラーを起こしたか、変化が少ない方から推定していくことができます。(一般にはエラーを起こしてしまったビットは棄却せず、そのエラーの影響を逆算して考えます)そうすれば、最終的には $0$ と $1$ が半々となったとしても、途中の推定経過からより尤もらしい結果を出すことができます。
量子コンピュータでは実際推定まで考えてこの方法で結果を変更すると言う考えもメジャーのようです。
さて、符号理論の用語の話に戻ります。
まず、符号状態とは誤りが起きていない正常な状態として考えられる状態をさし、符号状態の集合(古典の場合は基本的に有限個の要素からなる集合, 量子の場合は有限個の基底からなる複素線形空間)を符号空間と呼びます。
今回で言えば、誤りが起きていなければ $3$ つの計算結果は一致するはずですから、 000 と 111 が符号状態、符号空間は ${000,111}$ ということになります。
次に、誤りについて検出可能と訂正可能という言葉に触れておきます。符号状態のうちどの $2$ つを見ても$k$個以上のビットが異なっているとき、ある符号状態から $1$ 個以上 $k-1$ 個以下のビットがエラーを起こして元の状態にないとすれば、他の符号状態になることはできず、符号空間の外にあることになります。このとき $k-1$ 個以下の誤りが検出可能であると言います。また、このときにある符号状態から $1$ 個以上 $\lfloor \frac{k-1}{2}\rfloor$ 個以下のビットがエラーを起こしたとき、この状態に最も 「近い」(=ビットの異なりが最も少ない)符号状態が一意に定まり、この状態はその符号状態からエラーが起きた可能性が最も高いと考えられます。(通常、各ビットにエラーが起きる確率は$p\ll 1$であり、その状態になった条件付き確率で考えて元の符号状態はビットの反転が少ないものである可能性が高い$(k_1<k_2\Rightarrow p^{k_1}\gg p^{k_2})$からです)注意してほしいのは、上記の多数決による訂正という考え方もこの一例であるという事です。このように推定してエラーを訂正したとき、$\lfloor \frac{k-1}{2}\rfloor$ 個以下のビットが反転した状態をつねに正しい元の符号状態に訂正できます。よって、このとき$\lfloor \frac{k-1}{2}\rfloor$個以下の誤りが訂正可能であるといえます。
($\uparrow$ここで、さらっと書きましたが訂正すべきビットの数が最も少ない符号状態が元の符号状態として最も尤もらしいという考え方は後にも出てくる復号の極めて重要な考え方です。)
余談ですが、基本的に同じ量の情報に対してより多くの誤りを訂正するには符号を長くする必要があります。しかし符号自体が長くなったらエラーを起こすbit の期待値が比例して増えてしまうから意味がないのではと考える人がいるかもしれません。しかし、実際には、(訂正可能bit数)/(符号bit数)が一定の時、$p$ がこれより十分小さければ、符号bit数が増えるにつれて誤りを訂正できる確率は$1$に近づいていきます。これは計算によって確認できるので気になった人はしてみてください。
3.3 線形符号
この他にも様々な古典的な誤り訂正が存在します。
上の多数決は線形符号と呼ばれる符号の一例です。
ここで、線形符号をもう $1$ つ紹介しておきます。
この例を無視しても、量子誤り訂正の理解は可能ですが、
この例を通じて、より複雑な符号空間の例, また、シンドローム測定およびその測定結果のパリティと符号状態および訂正の関係を知っておくことは後で量子誤り訂正符号における、スタビライザー測定を元にした復号(エラー推定)を理解する上で役に立つはずです。
$4$ bit の情報を $7$ bit で表す符号を考えます。
以下, 列ベクトルと bit 列を対応させて考えます。
具体的には、bit列 $b_1b_2\ldots b_k$ に対して$F_2$ 上の列ベクトル $\mathbf{v}={}^t(b_1,b_2,\ldots, b_k)$を対応させます。($F_2$ がよく分からない人はベクトルの各要素が ${0,1}$ からなり、$a$ と $b$ の和が $a+b$ を $2$ で割った余りで表されるものとして考えてください。)
各要素が $F_2$ の元であるような $4\times 7$ の行列 $G\in M_{4,7}(F_2)$ を
$$
G=\left(
\begin{array}{ccccccc}
1 & 0 & 0 & 0 & 0 & 1 & 1 \
0 & 1 & 0 & 0 & 1 & 0 & 1 \
0 & 0 & 1 & 0 & 1 & 1 & 0 \
0 & 0 & 0 & 1 & 1 & 1 & 1 \
\end{array}
\right)
$$
で定めて、$4$ bit の情報 $\mathbf{x}$ に対応する符号 $\mathbf{y}$ を$\mathbf{y}={}^tG\mathbf{x}$ で定めます。
例えば、$\mathbf{x}={}^t(1,0,1,0)$であれば、$\mathbf{y}={}^t(1,0,1,0,1,0,1)$ となります。この行列 $G$ を生成行列と呼びます。
$7$ bitのbit列($2^7=128$ 個)全体に対応するベクトル空間は $F_2$ 上の $7$ 次元空間 $(F_2)^7$ として考えられます。
符号空間 $C$ はこの空間の元の部分集合であるわけですが、符号状態の定められ方から、これは、 ${}^t G$の各列を基底とした $(F_2)^7$ の $4$ 次元線形部分空間となっていることが分かります。
ちなみに、この符号は何個までの誤りをそれぞれ検出可能, 訂正可能でしょうか?答えはそれぞれ $3$ 個, $1$ 個です。直接確認しようとすると大変でしょう。比較的簡単に確認する方法があるので気になった人は線形符号の性質を調べてみてください。
ここで、符号空間は次のような空間として考えることもできます。
この視点の転換が後で出てくるスタビライザー状態という考え方のカギとなります。
次のパリティ検査行列 $H\in M_{3,7}(F_2)$ というものを考えます。
$$
H=\left(
\begin{array}{ccccccc}
0 & 0 & 0 & 1 & 1 & 1 & 1 \
0 & 1 & 1 & 0 & 0 & 1 & 1 \
1 & 0 & 1 & 0 & 1 & 0 & 1 \
\end{array}
\right)
$$
そして符号空間 $C$ は $H\mathbf{y}=\mathbf{0}$ をみたす $(F_2)^7$ の部分空間と言えます。これは次のようにも考えられます。(以下の説明は証明を与えようとしているものではありません。)
各行を $\mathbf{h}_1$, $\mathbf{h}_2$, $\mathbf{h}_3$ とすると、$(F_2)^7$ の $2^7$ 個の元のうち、ちょうど半分が $h_1\mathbf{y}=0$, もう半分が $h_1\mathbf{y}=1$ となります。
さらに前者のうちちょうど半分が$h_2\mathbf{y}=0$, もう半分が$h_2\mathbf{y}=1$ となります。最後にさらにこの前者のうち半分が$h_3\mathbf{y}=0$ となり、$2^7÷2^3=2^4$ 個の元が条件をみたし、これが符号空間の元と完全に一致します。
これを確かめるには$H{}^t G=\mathbf{O}$ である事と、$G$, $H$ の各行がそれぞれ線形独立であることを確かめればよいです。
(興味があればぜひ確かめてみてください)
ここで、$G$と$H$の行があわせて線形独立である必要はなく、実際成り立ちません。これは生成行列 $G$ の各行とパリティ検査行列$H$ の各行は行ベクトルで表記したとき見た目上は共通のものとなっていても実は本質的に異なるもの(双対空間の元)を指しており、比較すべき対象に無いことに起因しています。例えば、直交補空間のようなものとは異なります。実空間上でイメージすると、ちょうど一致するため、注意が必要です。
$H\mathbf{y}=\mathbf{0}$ならば訂正する必要はありません。
逆に言えば、そうでない場合は訂正する必要があります。
$H\mathbf{y}$ を(シンドローム)測定値(結果)と呼びます。
先にも書いたように訂正すべきビット数が最も少ないものがエラーが起きる前の状態として最も尤もらしいと考えられます。
この状態にするにはどのビットを反転させなければならないか考えてみましょう。
ここで、線形符号の面白い点はどの符号状態からエラーが起きたかによらず、測定結果だけから定まるという事です。
なぜなら $\mathbf{v}$ を元の符号状態、$\mathbf{e}$ がエラーによる反転を表すとしたとき、
このエラーが起きた後の状態 $\mathbf{v}+\mathbf{e}$ についての測定結果は、
$H(\mathbf{v}+\mathbf{e})=H\mathbf{v}+H\mathbf{e}=\mathbf{0}+H\mathbf{e}=H\mathbf{e}$
となり、$\mathbf{v}$ に依存しないからです。
どこを訂正すれば良いかは、次の手続きによって逆算できます。
まず、$7$ つのビットに対するエラーパターン $2^7=128$ 通りそれぞれに対して、
測定結果がどうなるかということから逆算すれば良いです。
その上で各測定結果に対して、その測定結果になるようなエラーパターンのうちエラーの起きているビット数が
最も少ないものが最も尤もらしいエラーパターンとして考えられます。
例えば今回の符号でいえば、測定結果が全て $0$ であれば、何も訂正しない(=訂正ビット数は $0$)パターンが最も尤もらしいと考えられます。
測定結果としてあり得るもの $2^3=8$ のうち残りの $7$ 通りについては
$7$ つのビットのうちいずれか $1$ つを訂正する訂正パターン $7$ 通りのいずれか $1$ つと対応し、下表のようになります。
| 測定結果 | ${}^t(0,0,0)$ | ${}^t(0,0,1)$ | ${}^t(0,1,0)$ | ${}^t(0,1,1)$ | ${}^t(1,0,0)$ | ${}^t(1,0,1)$ | ${}^t(1,1,0)$ | ${}^t(1,1,1)$ |
|---|---|---|---|---|---|---|---|---|
| エラー推定 | エラーなし | $1$ 番目の ビットにエラー |
$2$ 番目の ビットにエラー |
$3$ 番目の ビットにエラー |
$4$ 番目の ビットにエラー |
$5$ 番目の ビットにエラー |
$6$ 番目の ビットにエラー |
$7$ 番目の ビットにエラー |
先に上の行列で生成された線形符号は $1$ つまでの誤りを訂正可能と書きましたが、
この測定と訂正の手続きによって、その上限を達成できていることが分かります。
一般に、線形符号に対して訂正の上限はこのパリティ検査行列
(各行が独立、かつ、この行列を左から状態にかけて $\mathbf{0}$ となる事と符号状態であることが同値であるようなもの)
と上に書いたような手続きで求めたシンドローム測定値からのエラー推定(=訂正パターンの決定) によって、達成出来ることが証明できます。
すでに述べてきた事実を整理すれば、そこまで難しい証明ではありません(人によっては自明に感じるかもしれません)ので
ぜひ興味がある人はチャレンジしてみてください。
最後に練習問題を記しておきます。
先にこの章で最初に述べた多数決も線形符号の一種と述べましたが、
具体的には生成行列、パリティ検査行列、そして各測定結果から推定されるエラー推定はどのように与えられるでしょうか。
解答(クリックすると開きます)
これは解の一例ですが、
$$
G=\left(
\begin{array}{ccc}
1 & 1 & 1 \
\end{array}
\right)
, ¥quad
H=\left(
\begin{array}{ccc}
1 & 1 & 0 \
0 & 1 & 1 \
\end{array}
\right)
$$
で、推定は以下の表のようになります。
| 測定結果 | ${}^t(0,0)$ | ${}^t(0,1)$ | ${}^t(1,0)$ | ${}^t(1,1)$ |
|---|---|---|---|---|
| エラー推定 | エラーなし | $3$番目の ビットにエラー |
$1$番目の ビットにエラー |
$2$番目の ビットにエラー |
ここまでお疲れ様でした。
次の章からはいよいよ量子誤りの訂正の話に入っていきます。
古典誤りと比較した時の量子誤りの難点と特性とそれをどのように回避・利用しているか、というところにぜひ注目して読んでください。
4.量子誤り訂正
4.1 量子誤り訂正の困難
量子誤りの難点の $1$ つはそのエラーの起こり方の多様性によります。
そもそも qubit には具体的な物理的実装に由来したさまざまなエラーが考えられ、その中にはqubitの消失エラーやリークエラー($\ket{0}$, $\ket{1}$ およびその重ね合わせ以外の状態にとんでしまうエラー)等、扱いが難しいエラーもありますが、ここではそれぞれのqubitの状態が他のqubitとは独立に少しだけずれてしまうようなものを考えます。
そこまで限定しても、古典ではビットに対するエラーとして正しいか$0$ と $1$ が反転しているかという単純な $2$ 通りしか無かったものが、量子では例えば元々 $\ket{0}$ だったものが、$\alpha\ket{0}+\beta\ket{1}$ になるという
$1$ qubit 分、すなわちおおよそ $\mathbb{R}^2$ 程度の自由度があり、非可算無限個のエラーの起こり方があることになります。
これは一見、絶望的な事態に思えます。なぜなら、量子計算において系(今後時々用います、分からない人は計算に用いている qubit 全体を指してると思ってください)の情報を得るためにできることは有限回の測定であり、その結果から推定できるエラーのパターンは有限個しかないからです。また、仮に近似的な訂正を行うとしても、その測定結果のパターンからエラーの推定を個別に与えるのは至難の技と考えられるからです。
この事から、仮に先のように符号空間や測定のパターンを用いたとしても符号空間に 戻すという操作 が極めて困難だと分かります。
さらに、ここで測定について思い出すことで、もう $1$ つ困難があることに気づきます。先に、訂正においては計算過程の途中で細かく訂正、少なくとも推定する必要があると述べました。そして、訂正または推定を行うためには根拠となる情報が必要ですから、測定を行う必要があります。しかし、導入のところで述べたように測定を行うと
系の(qubitの)状態が変わってしまいます。系を変えない測定というのは情報との等価性からすでにどのような結果が出るか分かっている測定(すなわち無意味な測定)のみです。
また、No cloning theorem から系の状態を知らないままコピーするということはできず、細かく測定してそれぞれの段階での状態を知って途中過程の状態を再現して続きの計算を行う等を考えても、そもそもそのようなことができる程度の複雑さであれば、古典コンピュータでシミュレーションを行えるということになります。
4.2 量子誤り訂正
情報を得るための手段としては測定しかない、というのは事実です。
しかし、量子状態を符号空間に戻すためにできる事は測定結果をもとにこちらが指定する操作だけではありません。
測定による系の変化を、系を符号状態に戻すために使う というのが鍵となるアイデアです。(厳密には測定により変化させた後の状態を、測定結果から定まる操作によって補正する、という形になります。)
測定が系の状態を変えてしまう、というのは先ほどまで量子誤り訂正における困難でしたが、これが裏返る事で、量子誤り訂正が急に実現可能なものに見えてきます。
まず、$3$ 章の最後で述べた誤り訂正の考え方、持ちたい情報に対して過剰なビット(qubit)を与え、その余剰分で誤り訂正を行うという事を思い出します。
それは、具体的には状態空間の部分空間としての符号空間という形で現れています。
符号空間が情報を表す空間であり、状態空間がそれよりも真に大きいというのがその余剰分と言えます。
そして、測定とは何も $1$ qubit の情報を得るためのものではなく、状態を特定の空間(この空間はこちらが指定できず、測定結果に依存する)に射影するものであったことを思い出します。
すなわち、系の状態を測定によって符号空間に射影する事を目標にします。
逆に言えば、元の $n$ qubit の状態空間の中で、適当な条件(具体的には可換かつ独立)をみたすX,Z多体測定の組を指定し、
その測定全てに対して $0$ を返すような空間を符号空間として定める事を考えます。
この測定を スタビライザー測定 と呼び、このような符号を スタビライザー符号 と呼びます。
当然測定結果は指定できないのでいくらかの確率で $1$ となってしまい、誤った空間へ射影されます。
これを測定結果から正しい符号空間へ戻す手続きが先の線形符号におけるエラー推定に対応します。
(注 : 今回は測定の種類をやや限定していますが、一般にはスタビライザー符号と呼ぶ際、パウリ群のうち固有値が実数であるようなもの全体から測定を選ぶものを指します。)
中途半端にずれている状態は測定によって一定の確率で真反対の状態に押し付けてしまうと同時にそれを検出し、
線形符号と同様に検出しようという事です。
具体的には、$n$ 個の physical qubit (後述)からなる状態空間は $2^n$ 次元の複素ベクトル空間であり、
測定は $0$ または $1$ に対応する固有空間でちょうど次元が半分の固有空間を指定するため、
$n$ 個の physical qubit で $k$ 個の logical qubit(後述)の情報を表す時、
$n-k$ 個の測定によって、符号状態を指定します。
さらに、残りの $k$ 個の自由度も測定によって指定し、これを logical qubit の基底とします。
以下では、$k=1$ の場合を扱います。
$1$ qubit 分の情報を符号化できれば同じものを各qubitに対して適応すれば誤り訂正できるため、
現在多く研究されているものも 1 qubit 分の情報を表す訂正符号です。
ここで、情報を持つ実在するqubit を physical qubit,
それらのうち符号状態で表される状態を logical qubit と呼びます。
4.3 Xエラーにのみ対応する量子誤り訂正符号
まず、多数決を元にした不完全な量子誤り訂正符号を例にあげます。
ここで、以下の符号が不完全である点は対応できるエラーが部分的である点であり、
手続き自体に欠陥がある訳では無い事を先に断っておきます。
$3$ qubit からなる符号で $1$ qubit 分の情報量を表す事を考えます。
必要な測定は $2$ つとなりますが、ここでは$Z_1Z_2$ と $Z_2Z_3$ を指定します。
符号空間は$\ket{000},\ket{001},\ket{010},\ket{011},\ket{100},\ket{101},\ket{110},\ket{111}$ で張られる $8$ 次元の状態空間のうちの $2$ 次元部分空間となる訳ですが、この時具体的にはどのような基底で書かれるでしょうか?
この場合は分かりやすく$\ket{000},\ket{111}$ によって張られる空間となります。
以下では、logical qubit , すなわち $3$ つの physical qubit で表される $1$ qubit分の情報のその基底を
$\ket{0}_L=\ket{000}$, $\ket{1}_L=\ket{111}$とします。
すなわちlogical qubit の基底を定める測定を $Z_1Z_2Z_3$ とします。
この$2$ つの状態が$Z_1Z_2,Z_2Z_3$ 両方の固有値 $1$(測定結果$0$) に対応する固有状態であることは明らか(これが分からない人はもう一度 2.2 測定について確認してください。)
具体的な手続きは次のようになります。
0. (計算を行う。)
- $Z_1Z_2$, $Z_2,Z_3$ 測定を行う。
- 測定結果を元に訂正を行う。
- (次の計算を行う)
本来、0.の計算の結果として$\ket{\psi}=\alpha\ket{0}+\beta\ket{1}$ になるはずが
エラーが起き、
$\ket{0}{error}=\left(1-\frac{\epsilon}{2}\right)\ket{0}+i\sqrt{\epsilon}\ket{1}$,
$\ket{1}{error}=\left(1-\frac{\epsilon}{2}\right)\ket{1}+i\sqrt{\epsilon}\ket{0}$
として
$\ket{\psi}=\alpha\ket{0}{error}+\beta\ket{1}{error}$ (ただし、$\epsilon\ll 1$)となってしまった場合を考えます。
(これは微小角度のX回転エラーの近似的表記です。)
もちろん符号が無かったとすると、このままとなります。
もし $3$ qubitの符号にこのようなエラーが起きると、
本来は$\ket{\psi}L=\alpha\ket{0}L+\beta\ket{1}L=\alpha\ket{000}+\beta\ket{111}$ となるはずが、
$\ket{\psi}=\alpha\ket{0}{error}\ket{0}{error}\ket{0}{error}+\beta\ket{1}{error}\ket{1}{error}\ket{1}_{error}$
となります。
測定前の各状態の係数はそれぞれの項及び $\alpha, \beta$ について $\epsilon$ の次数が最も低い項のみを採用して
$$
\ket{\psi}=(\alpha-i\epsilon^{\frac{3}{2}}\beta)\ket{000}
+(i\epsilon^{\frac{1}{2}}\alpha-\epsilon\beta)(\ket{001}+\ket{010}+\ket{100})
+(i\epsilon^{\frac{1}{2}}\beta-\epsilon\alpha)(\ket{011}+\ket{101}+\ket{110})
+(\beta-i\epsilon^{\frac{3}{2}}\alpha)\ket{111}
$$
となります。このうち測定後の状態は、近似的に正規化して、大まかに
$Z_1Z_2,Z_2Z_3$測定の結果がそれぞれ$0,0$であった時、$\ket{\psi}{after}=(\alpha-i\epsilon^{\frac{3}{2}}\beta)\ket{000}
+(\beta-i\epsilon^{\frac{3}{2}}\alpha)\ket{111}$,
$Z_1Z_2,Z_2Z_3$測定の結果がそれぞれ$0,1$であった時、$\ket{\psi}{after}=(\alpha+i\epsilon^{\frac{1}{2}}\beta)\ket{001}
+(\beta+i\epsilon^{\frac{1}{2}}\alpha)\ket{110}$,
$Z_1Z_2,Z_2Z_3$測定の結果がそれぞれ$1,0$であった時、$\ket{\psi}{after}=(\alpha+i\epsilon^{\frac{1}{2}}\beta)\ket{010}
+(\beta+i\epsilon^{\frac{1}{2}}\alpha)\ket{101}$,
$Z_1Z_2,Z_2Z_3$測定の結果がそれぞれ$1,1$であった時、$\ket{\psi}{after}=(\alpha+i\epsilon^{\frac{1}{2}}\beta)\ket{100}
+(\beta+i\epsilon^{\frac{1}{2}}\alpha)\ket{011}$,
となります。ちなみにそれぞれの結果となる確率はおよそ、$1-3\epsilon$, $\epsilon$, $\epsilon$, $\epsilon$です。
この時、訂正、すなわち測定結果を受けての補正としては次のようなものが適切なことがわかると思います。
| $Z_1Z_2$ | $0$ | $0$ | $1$ | $1$ |
| $Z_2Z_3$ | $0$ | $1$ | $0$ | $1$ |
|---|---|---|---|---|
| 操作 | 何もしない | $3$ 番目のqubit にXゲート |
$1$ 番目のqubit にXゲート |
$2$ 番目のqubit にXゲート |
この結果として、誤り訂正を何も用いないで $1$ qubit で計算を行った時と比較して、$1-3\epsilon$ の確率でエラーが緩和($\sim \epsilon^{\frac{1}{2}}\to \sim \epsilon^{\frac{3}{2}}$)されていることが分かると思います。
なお、よりシンプルなエラーモデルとして一定確率でqubitが反転するものを考えた時、
($1$つ以上)$2$ つ以下の qubit が反転したときに 測定値が全て $0$ となることはないという意味で$2$つまでのXエラーが訂正可能
$1$ つ以下のqubit が反転したときにこの補正がうまくいくと言う意味で、$1$つまでのXエラーが訂正可能であるといいます。
(あくまで Xエラー が検出・訂正可能であることに注意してください。)
これが量子誤り訂正の例となります。
一方で、これは Z エラーに対して無力です。
例えば、元の状態$\ket{\psi}_L=\alpha\ket{000}+\beta\ket{111}$から$1$ 番目のqubitがZ反転エラーを起こしたとすると
$\ket{\psi}_L=\alpha\ket{000}-\beta\ket{111}$ となってしまい、状態として異なりますが、スタビライザー測定からは誤りを
検出できません。
量子誤り訂正において$a$個までの誤りが検出可能・訂正可能とは Xエラー、Zエラーが足して$a$個以下であるとき常に検出・訂正できることを言います。
4.4 量子誤り訂正符号と符号距離
逆にX,Zの両エラーに対応できれば、$Y=iXZ$と書けることと、$X,Y,Z$方向の回転の合成で全ての回転エラーは書けることから
測定によってこれらの誤りに対応できれば十分です。(少し非自明)
その上で各qubit が独立にエラーを起こすとした場合、それをどれくらいの確率で検出できるかという精度($\epsilon$の指数部にあたるもの)は
いくつのqubitが反転エラーを起こしたときに一方の符号状態から他方の符号状態へ動くかということに依存します。
ここで、$Y$ エラーは(全体位相を無視して)$XZ$と書けるため、あるqubit が X,Z 両方向のエラーを同時に起こす確率はどちらかのみを起こす確率と等しい事に注意すると、スタビライザー符号が与えられたときその性能は結局次のような(ある種ゲームのような)手続きで求まる値に強く関連します。
符号に用いるスタビライザー符号、特にスタビライザー測定が与えられたとします。
今考えているのは $1$ qubit 分の符号であることに気をつけると、
これは$n$ qubitからなる符号であるとき $n-1$ 個のスタビライザー測定が与えられます。
そして、これらはそれぞれ $X_i,Z_i$ $(1_leq i_leq n)$ の積で書かれています。
このとき次の問題を考えます。
最初、全ての測定値は $0$ であるとします。
- $1$ 以上 $n$ 以下の相異なる $d$ 個の整数 $i_1,i_2,\ldots,i_d$ を選びます。
- $j=i_1,i_2,\ldots,i_d$ について、$X_j$ を含む測定の値を全て反転($0\leftrightarrow 1$)するか何も変えないか選びます。
- $j=i_1,i_2,\ldots,i_d$ について、$Z_j$ を含む測定の値を全て反転($0\leftrightarrow 1$)するか何も変えないか選びます。
2.3.合わせて少なくとも$1$回は反転させることを選んだ(実際に反転するような測定が存在しなくても良い)上で、全てのスタビライザー測定の値を $0$ であるようにしたいです。
これを達成できる最小の $d$ はいくつですか?
これの答えの $d$ に対して、$d-1$個までの誤りが検出可能で$\lfloor \frac{d-1}{2}\rfloor$ 個の誤りが訂正可能であるといいます。
基本的に、エラー訂正符号によって訂正された後のエラーの精度は$\sim \epsilon^{\lfloor \frac{d-1}{2}\rfloor+1}$となるため、
これが大きいほど性能の良い符号であると言えます。ただし、性能の良い符号ほど $1$ qubit 分の情報を表すために多くの physical qubit を利用するため、その点はトレードオフの関係にあります。
先ほど考えたXエラーにのみ対応する量子誤り訂正符号で考えてみましょう。
X エラーしか考えない、というのは Z 測定の値のみ反転する、すなわち 2. では反転を常に行えず、3. においてのみ選択肢がある場合といえます。
$Z_1Z_2$, $Z_2Z_3$ がスタビライザー測定として与えられていますから、$Z_1,Z_2,Z_3$のうち少なくとも $1$
つの値を反転させた上で スタビライザー測定の値をともに $0$ にする必要がありますが、これは$Z_1,Z_2,Z_3$すべてを反転させた時のみであり、
$d=3$ と言えます。よって、$2$個以下のXエラーが検出可能であり、$1$個以下のXエラーが訂正可能です。
一方で、一般に誤り、すなわち2.3.の両方を考えたとき、 $d=1$, $i_1=1$ として、$X_1$ を含むものを反転させると
そのようなスタビライザー測定は存在しないため全ての測定値は$0$のままであ流ので条件をみたしています。
よって、先ほどの符号は$0$個以下の誤りが検出可能、すなわち量子誤り訂正符号としては欠陥があると言えます。
4.4 $1$ つまで誤り検出可能な誤り訂正符号
では、どのようなものが条件をみたすでしょうか?
まず、$d=2$の例を挙げます。
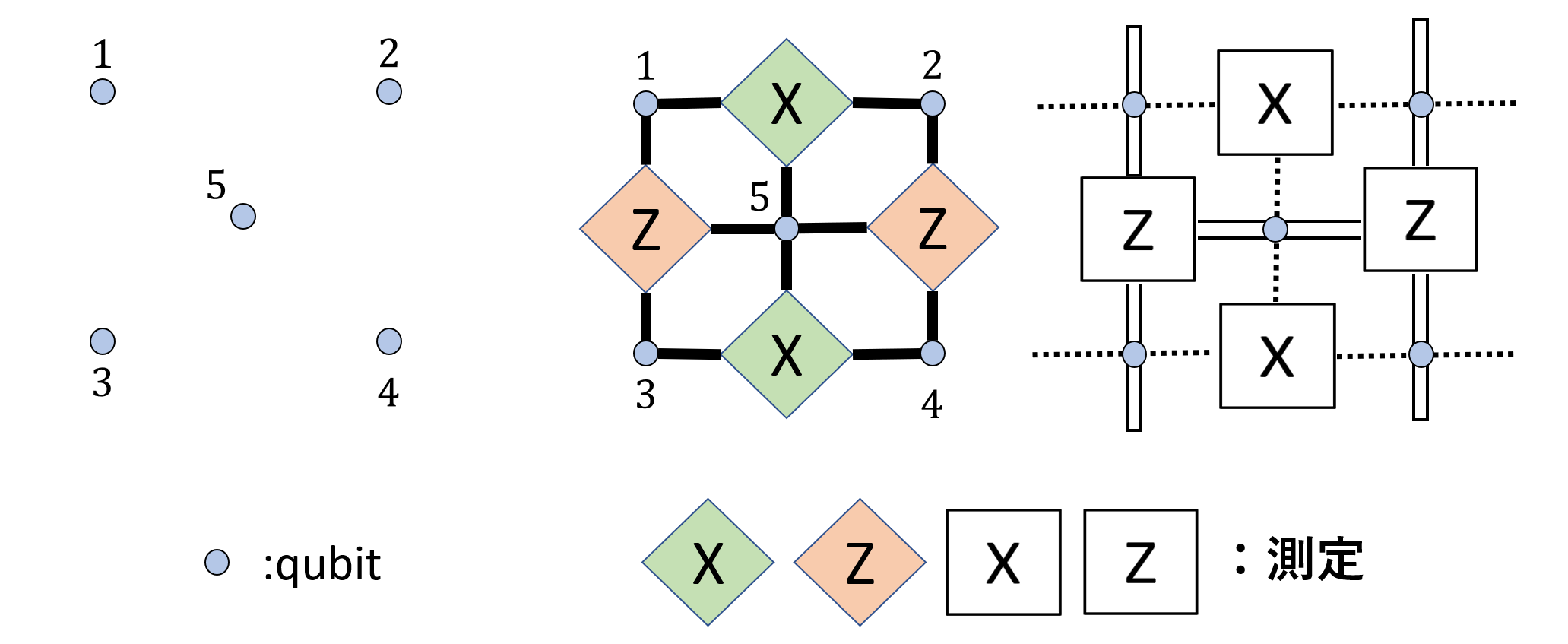
$n=5$, スタビライザー測定が $X_1X_2X_5$, $X_3X_4X_5$, $Z_1Z_3Z_5$, $Z_2Z_4Z_5$ であるようなものを考えます。
これは可換かつ独立です。(定義が分かる人は確認してみてください。)
このとき、ある$i$ を $1$ つ選んで $X_i$, $Z_i$ を含む測定の結果を反転させても全てを $0$ にすることができないことが分かるでしょう。
逆に、$Z_1$, $Z_3$ を含むものを(含んでいる個数だけ)それぞれ反転させると、全てを $0$ にすることができてしまいます。
よって、この符号では $1$ つまでの誤りが検出可能、ただし訂正は $\lfloor \frac{2-1}{2}\rfloor=0$ 個のためできないと分かります。
実はこの符号は表面符号と呼ばれる符号の$d=2$ のときにあたり、qubit と測定は下図のような関係があります。
4.5 $1$ つまで誤り訂正可能な誤り訂正符号
最後に、$d=3$の例をあげます。
$n=7$, スタビライザー測定が $X_1X_3X_5X_7$, $X_2X_3X_6X_7$, $X_4X_5X_6X_7$, $Z_1Z_3Z_5Z_7$, $Z_2Z_3Z_6Z_7$, $Z_4Z_5Z_6Z_7$ であるようなものを考えます。
これは $d=3$ となります。$d=1,2$ の時全ての測定結果を $0$ にできないことは3.3 線形符号をヒントにぜひ確かめてみてください。
$d=3$のとき、$X_1,X_2,X_3$ を含むものを反転させると、全てを $0$ にすることができ、
この符号では $2$ つまでの誤りが検出可能、$1$ つまでの誤りが訂正可能ということがわかります。
4.6 展望
今回紹介するのはここまでですが、さらに先の符号を少しだけ紹介します。
毎回このような手続きで符号に対して符号距離 $d$ を求めていては大変です。そこでしばしば、トポロジー的な性質を用いた符号が現れ、それらはトポロジカル符号とよばれます。
例えば、X測定、qubit、Z測定を面、辺、頂点にこの順に対応させて$\partial\partial D=0$ の性質から測定の可換性を保証するようなものです。
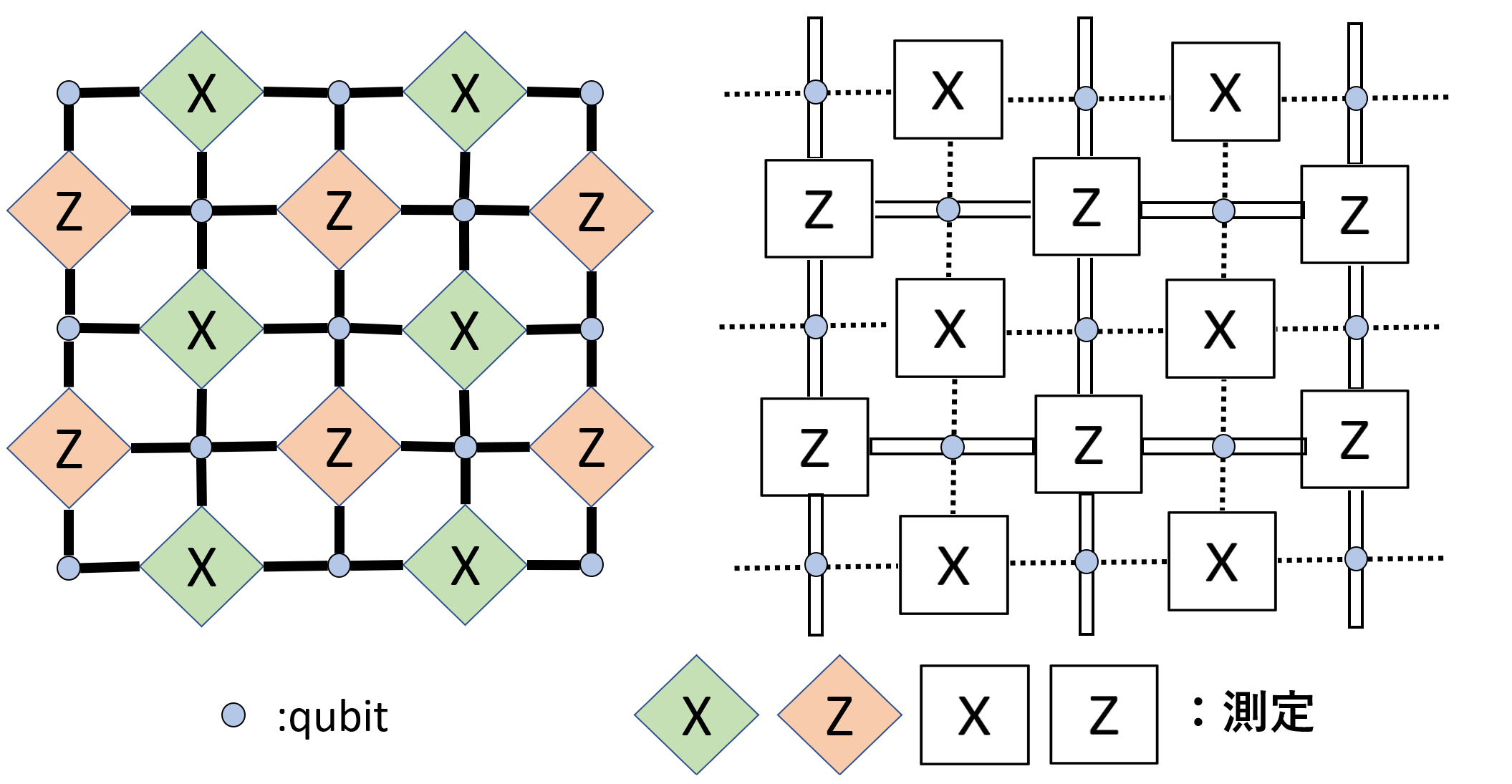
例えば、表面符号と呼ばれる符号はトーラスの性質からきています。
表面符号の例は実は $4.4$ に登場しています。以下に$d=3$ の例も貼っておきますが、この一辺の長さを伸ばしていくことで
符号距離をいくらでも大きくすることができます。
他にも color codeと呼ばれるものもあります。
表面符号は正方格子のような形をしていますが、他にもハニカム構造のような符号などもあります。
実は測定の際にはあまり多くのqubitに渡らない測定で行えるものが都合が良く、表面符号はいくら符号長を伸ばしても高々 $4$ つのqubitにわたる測定しか行われない点で優れています。(他にも優れている点は多くあります。)
ハニカム構造のものは高々 $3$ つのqubitにわたる測定しか行われません。(六角格子を思い浮かべてみてください。)
符号やその復号アルゴリズムは現在も主要な研究対象であり、現在開発されている符号の中には
面白い見た目のものや、その符号や復号のアルゴリズムが面白い符号が多く存在します。
ぜひ興味があれば調べてみてください。
最後まで読んで下さった方々、ありがとうございました。
少しでも誤り訂正の雰囲気や面白さが伝われば幸いです。
続編(表面符号とその復号アルゴリズム等)は気が向いたら書こうと思います
所々説明を端折ったり省略しているところもあるので分からないこともあるかもしれません。
この記事はQiita上でも公開していますので、そちらのコメント等で質問を頂ければと思います。
参考文献
"Quantum Computation and Quantum Information" M.A.Nielsen, I.L.Chuang
"Quantum Error Correction for Beginners" S.J.Devitt, K.Nemoto, W.J.Munro. (arXiv:0905.2794 [quant-ph])