社内で開催されるISUCONに出るために、予習としてやってみたことをまとめます。
いきなりパフォーマンス改善手法について学ぶのではなく、まずは何を学ぶべきか知るための下準備をするところからはじめました。
経験や知識がなく何を予習すれば良いかわからない、ISUCONの進め方のイメージが湧かないというのもありましたが、手法を学ぶ前にまずその手法の使いどころを知るべきだと考えたためです。
自分のような新人プログラマには参考になる内容かもしれません。
ISUCONの進め方を知る
出てみたブログなどを読み漁ると似たようなことが書いてあるかと思いますが、こんな感じに進めると良いと教わりました。
当日の流れ
- 各チームにインスタンス、sshのログイン方法を渡されて、よーい、どん。
- ベンチを回す。
- 渡されたインスタンスの中にレギュレーションのまとめやアプリケーションがあるので中身を確認し、アプリケーションの概要や仕様、禁則事項など必要な情報を素早く把握する。
- 使用する言語の参照実装に切り替える。
- Githubリポジトリ(よ)、デプロイスクリプトなどの準備。
(チームで出る場合はインスタンスを直接触るわけにもいかないので) - ボトルネック把握に使う計測ツールを入れる
- 計測ツールとアプリケーションのコードを並行して見て、ボトルネックを探す
- ボトルネックを見つけたらブランチを切って修正し、デプロイしてベンチを回す。
(ブランチを切って手元でやらなくても良い場合もありそうなのでその辺りは柔軟に) - スコアが改善していたら、↑の修正ブランチをmasterにマージする。
以降、7~9をいい感じに繰り返してスピードアップさせる。
重要なポイント
- とにかく時間がない。環境構築など初動に躓くとあっという間に時間がなくなるので、事前の役割分担・シミュレーションが大事。
- インパクトの大きい修正箇所を見つけることが大事。手当たり次第に修正しても、中々スコアが伸びなかったりする。
過去問をやってみる会をやる
AWSにISUCON8予選問題とベンチマーカーのインスタンスを立てて(もらって)、上記に記載した流れを一通りやってみました。
計測ツールは Datadog APMを使用しました。
エンドポイントごとのリクエスト数やレイテンシー、合計かかった時間などを簡単にみることが出来て便利でした。
インスタンスにDatadog agentを入れる
Datadogのコンソールから Integrations > agent を開くとセットアップ手順のガイドが出てきます。
インストールに必要なコマンドをコピーし、ssh接続をして叩きます。
インストール成功したら、DOCSを参照しながらコマンドでagentを立ち上げます。
これで完了ですが、一応ダッシュボードから system metricsなどを開いてデータが取得できていることを確認しておきます。
Datadog APMを入れる
これもコンソールから APM > services > new service を開き、ほぼセットアップ手順に従うだけです。
私はNodeJSを使うことにしていたので、dd-traceというライブラリをインストールし、アプリケーションコードに以下を書き加えるだけです。
import tracer from "dd-trace";
tracer.init({ analytics: true });
これで完了ですので、今度もダッシュボードからデータが取得できていることを確認します。
計測結果をみて怪しいところを探す
なんとなくアプリケーションの概要を把握した上で、早速計測結果をみていきます。
APMタブを選ぶと、以下のようににService別の計測ダッシュボードの一覧が表示されています。
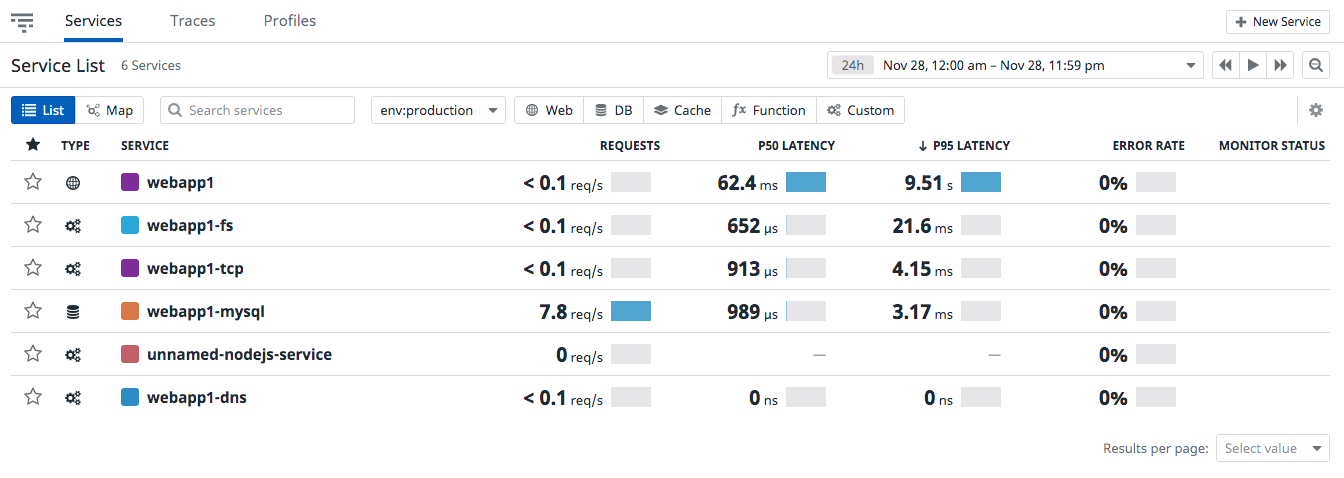
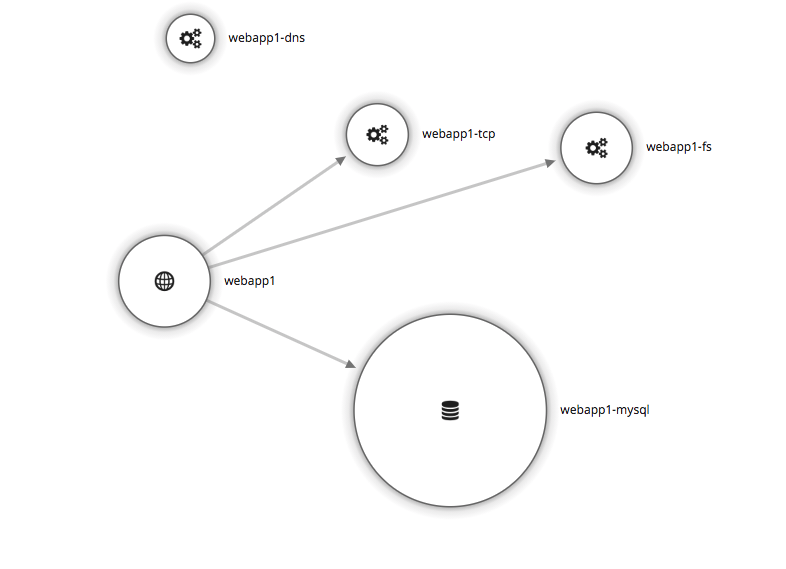
色々出てきて迷いますが、まずは本体の webapp1 を選んでみます。
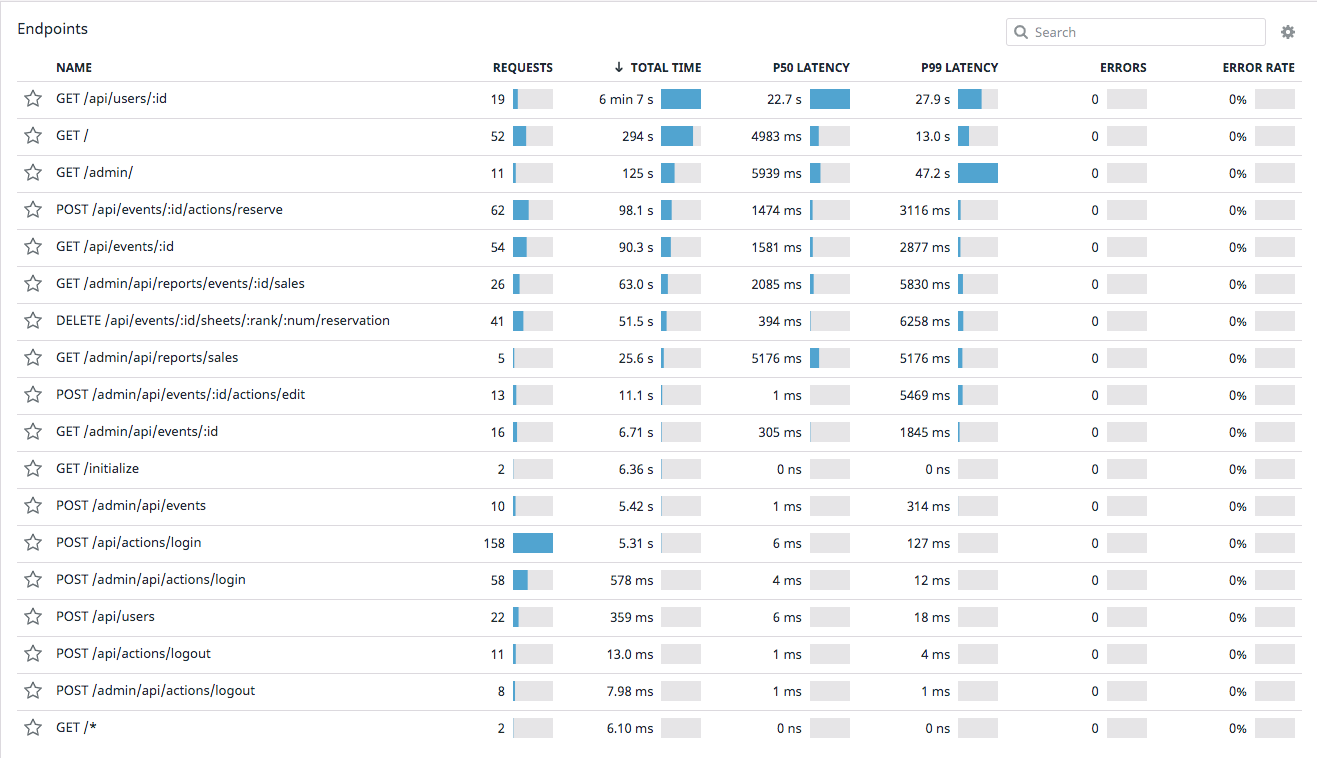
エンドポイントごとの合計所要時間をみるとどうやら GET /api/users/:id や GET /あたりが特に遅いようです。
GET /admin もレイテンシーは長いですが前者と比べるとリクエスト数が少ないですね。
GET /api/users/:id を選択して、より詳細をみていきます。
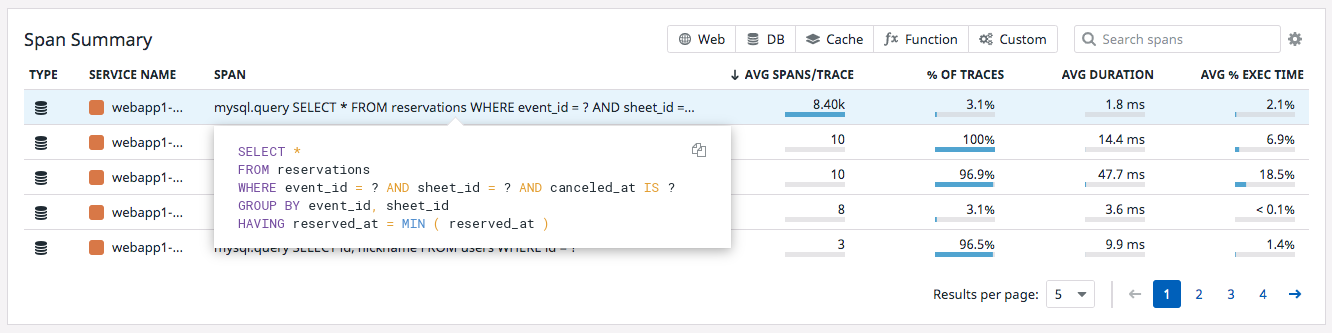
どうやらこのSQL文が怪しいです。AVG SPAN/TRACEを見るとめちゃくちゃ呼ばれていることがわかります。
Avg Span/trace
スパンが少なくとも 1 回存在する、現在のリソースを含むトレースのスパンの平均発生回数。
cf. https://docs.datadoghq.com/ja/tracing/visualization/resource/#%E3%82%B9%E3%83%91%E3%83%B3%E3%82%B5%E3%83%9E%E3%83%AA%E3%83%BC
怪しいところのコードを見てみる
怪しいところを見つけたので、このコードを改善できるか具体的に調べていきます。
該当のSQLを探し周辺コードを読むと、 getEventという関数によってループのさらにループの中で都度このSQLが実行されてしまっていたことがわかります。いわゆる N+1問題ですね。
しかもこの getEvent を呼び出す getEvents は GET / などでも呼ばれており、他のエンドポイントの遅い原因も同じく getEvent にありそうです。
コードを修正する
ボトルネックがわかったので修正をします。
getEvents が色々なエンドポイントから呼ばれていたのと、取得結果は破壊的メソッドで取り扱われていて少し読みにくかったので(型もないし)、壊さないように直せるか不安でした。
なのであまり手を加えず、ループ自体は残しつつ外側でまとめてSELECTする程度の修正にしました。
const [sheetRows] = await fastify.mysql.query("SELECT s.*, r.id as reservation_id, r.reserved_at FROM sheets s LEFT JOIN(SELECT*FROM reservations WHERE event_id=? AND canceled_at IS NULL GROUP BY event_id,sheet_id HAVING reserved_at=MIN(reserved_at))r ON s.id=r.sheet_id ORDER BY s.`rank`,s.num", [event.id]);
if (sheet.reservation_id) {
if (loginUserId && sheet.reservation_id === loginUserId) {
sheet.mine = true;
}
sheet.reserved_at = parseTimestampToEpoch(sheet.reserved_at);
eventごとに sheetsを取得しており、1 sheetsに有効な reservationは1つしかないはずなので、このSELECT分で事足りるはずです。
修正後、ベンチを回すと 580 → 4514 ~ 7842 くらいにスコアが伸びていました ![]()
(本家ISUCONより大きいインスタンスのサイズを使うなどしているので、本家のスコアとは比較できない気がします)
過去問をやってみる会は初動の動きを確認するところまでがゴールでしたので、他にもまだやれることはあるはずですが一旦ここで終了します。
講評を読んで振り返る
初動の動きは躓くことなくスムーズに修正が出来た点は良かったですが、もっと点を伸ばすには何ができたかを知るために講評を読みます。
大体こんな感じの視点で読みます。
- 他の修正ポイントを知り、どのような思考・調査でその課題に気づくことが出来そうか考える
→これが本番での戦略に繋がる - 単純に足りない知識をインプットする
ロック地獄とか聞いたことはあるけど、実際にどう解消するかとか知識がなかったので。 - 自分の行った修正をもっといい感じに修正出来そうか知る。
1段階分のループをなくすだけの弱腰の修正をしてしまったが、 この修正は2段階分のループを外してとても点数が伸びたよう
終わりに
「とにかく時間がないので限られた時間内で環境を用意して、効果の大きい修正を効率的に行うこと」が大事なんだなぁという感想が得られ、また苦手なインフラ周りや計測ツール周りについて勉強していくための足掛かりを作ることが出来ました。
社内ISUCON本番までの予習としてやるべきことがわかったのはもちろん、開発者としてスキルアップするための知識に触れることが少し出来た気がするので実りの多い予習が出来た気がします。