この記事で書くこと
stable-diffusion-webuiを100時間くらい触った上で、手っ取り早くクオリティを上げるために知っといたほうがいいこと
テクニック、記事リンク、関連サービスを書きます
筆者はWebエンジニアだけどAI素人です
言葉もあやふやなので修正歓迎です![]()
この記事で書かないこと
導入方法
エンジニアはもちろんgitで導入したほうが更新が楽でよいです
❗️最新情報2024/12追記❗️
現在主流なのは以下のReForgeとv-pred対応モデルを使っての画像生成となります
凄まじい性能アップがされてる上に、GPUはSD1が動くもので全く問題なく使えるので、ぜひ触ってみてください
先に知っておきたい知識
モデル
- 絵や画風を学習させた大元の心臓部。これを変えると同じプロンプトでも全く別の絵になります
- モデルは
checkpointと言われていて 拡張子.ckpt または .safetensor で配布されてます - ckptは任意のコードを実行できる問題があるので、できればsafetensor形式のモデルを入手しましょう
vae
- 出力される絵の塗り、明るさに影響する
- 好きなモデルとvaeを組み合わせることができる
- 界隈でよく使われてるのはwaifu-diffusionのvae。発色が良いため
追加学習(ファインチューニング)
- 絵柄、シチュエーション、特定のキャラなどを追加学習させて出力しやすくする
- ぐっと表現の幅が広がります
- 最近はLoRAという手法が主流になっていて、少ないVRAMで学習させることができる
- LoRAで追加学習させたモデルが配布されているので、これを入れることでローカルで学習環境がなくても恩恵を受けることができる
- 自前で学習させるにはVRAM6GB以上が必要(6でも行けますが、LoRAで好きなキャラ学習させるのに数時間かかります)
学習法によってファイルを格納しておくところが違うので注意
(さらに最新のstable-diffusion-webuiでLoRA用のディレクトリが作られてるので注意)
- TIの場合
\stable-diffusion-webui\embeddings- 拡張子
.pt - ファイルサイズ2桁KB~3桁程度でちっちゃい
- 特定の単語に関するベクトルだけ保存しているから?(よくわかってませn
- HNの場合
\stable-diffusion-webui\models\hypernetworks- 拡張子
.pt - ファイルサイズは85,713KB~
- 特定のキャラというよりは全体に影響するような絵柄の学習によく使われてるっぽい?
- LoRAの場合
\stable-diffusion-webui\models\lora- 拡張子は
.safetensors - ファイルサイズは147MB~
- 特定のキャラ、画風、コンセプトなどを学習させているようだ
webuiの設定を変える
- 絵の出力に大きく関わる部分を変えやすくする
Settings -> UserInterfaceにある
Quicksettings list のなかに以下文字列いれて、Apply setting&Reload UIします
sd_model_checkpoint,sd_vae,CLIP_stop_at_last_layers
UIに以下のようなセレクトボックスが追加されるかと思います

これによってモデル、vaeの変更がしやすくなるのでぜひやっておきましょう
clip skipは自分もよくわかってないのですが、LoRAを使う場合などは2にしておくとよいようです
モデルによっては、この数値にしてくださいなどreadmeに書かれてたりします
モデルをさがす
モデルによって得意な画風や絵柄が変わる
同じプロンプトでもモデルによって出力される絵が変わります
モデルは checkpoint と言われていて 拡張子.ckpt または .safetensor で配布されてます
モデルは以下で探すと良いです
サムネやプロンプトつきでどういう画風かわかりやすいです
DLもすぐ出来ます
アニメ風イラストだとabyssorangemix3が人気です
https://huggingface.co/WarriorMama777/OrangeMixs#abyssorangemix3-aom3
追加学習されたモデルをさがす
これもcivitaiにたくさんあります
最新のwebuiならpromptで <xxx.. といれると、データがうまく配置できてロードできていれば補完できるようになっていて、TI,HN,LoRAともにすべてprompt上で指定できるようになりました
promptに入れると画質があがるもの
masterpiece はよく使われてますが、個人的にはあと highres があるとないのとで大きく変わるように思います
この手の全体の品質向上系のタグは1,2個いれればよいかと思います
masterpieceを入れると顔が似たようなものになるので外したほうがいいという記事もありますが、今は、顔の特徴などはLoRAを使って変えるほうがよいかと思います
promptに入れるタグはaibooruなどで探すと良いです(エロ系も多いので注意)
日本だと ちちぷい https://www.chichi-pui.com/ (要ユーザー登録)
negative promptをハックして品質を上げる
TIで悪い例を学習させて、Negative Promptでそれを呼び出す、という手法が人気です
たとえばこれ
https://civitai.com/models/4629/deep-negative-v1x
DLしてディレクトリに適切に配置したあと、Negative Promptに NG_DeepNegative_V1_75T を入れると有効になります
他にも色々あるので探して入れてみると良いと思います
ただ、少なからず元の絵柄に影響を及ぼすということで嫌ってる人もいます
追記20230216
最近の人気は EasyNegative です
https://huggingface.co/datasets/gsdf/EasyNegative
追記ここまで
余計な要素消していく手順
基本はとにかく生成していって、出力されてしまう不要な要素をnegative promptに突っ込んでいく、という手順でやって打率を上げていきます
いい感じのものが出力されたけど一部の要素だけが上手く行ってない、微調整したい
というところまで行ったら、 seed の横にあるExtraにチェックをいれてVariation seedを使います
Variation strengthが元のseedで出力される絵とどれくらい差分を生み出すかの値で、0.1くらいにしておくと微妙に要素を変えて出力してくれます。この辺は実際に出力してみて微調整します
同じseedであれば大きく絵が変わることはないので、さらにpromptでも調整するのもいいと思います(prompt変えすぎるともちろん全然違ったものになります

sampling method, sampling steps
サンプラを変えると絵が大きく変わります
人気なのはDPM++ 2M Karras
DDIMは人物が増えたときも綺麗に描画されるらしい
DDIMはpromptでAND構文が使えない
sampling stepsを増やすと緻密さが上がっていきます
20~25くらいに設定してる人が多い
AND構文を使ったり、複雑なオブジェクトが多いともっと増やしたほうが良い印象
40くらいにしてる人もいます
出力絵の解像度をあげる
解像度は512x512~512x768あたりで出力してる人が多い
単純に解像度をあげるとメモリを食う上に謎の人物やオブジェクトが追加で描画される率があがる
stable-diffusion-webuiにはそれを発生させずに解像度を上げるためオプションがある
下にあるHires.fix にチェックをいれると、設定項目が出てくる
Denoising strengthは拡大時に元絵をどれくらい尊重するかで大きいほどズレが生じる
0.5くらいから試すといいが、結構元絵によってちょうどいい値が違うので、何度か変えてやってみたほうがよいです
Upscalerは絵によって得意不得意がある
たとえばアニメ系ならR-ESRGAN AnimeVideoだとなめらかにアップスケールしてくれる

↑でやると画質は綺麗に出力されるが、元絵と少し変わることがある
もっと単純に解像度あげるだけならExtrasからUpscaler選んでやると良い
ただし画質はあまりよくないです
さらに上級者にはmultidiffusion(Tiled Diffusion)という拡張を入れてアップスケールするというテクニックもあります
高解像度でもtext2imageで絵が崩れにくくなる、GPUがしょぼくても高解像度にできる、範囲指定してプロンプトを書けるというメリットがあります
少々複雑ですが、質がよくなるので参考までに紹介しておきます
おすすめのExtensions
- a1111-sd-webui-tagcomplete
- タグの入力補完できる
- multidiffusion-upscaler-for-automatic1111
- GPUがしょぼくても綺麗にアップスケールできる。高解像度でも絵が崩れない
- sd-webui-controlnet
- 好きなポーズをさせられる
- stable-diffusion-webui-wd14-tagger
- 絵からプロンプトを推測してくれる
- sd-webui-cutoff
- 近くに配置している色の色移りを防ぐ
VRAMが足らなくなってエラー落ちする
どうしようもない場合もありますが起動時のARGSに --medvram いれとくと改善されます
生成速度が遅くなるなど書いてあったりしましたが、自分の環境GTX1660Ti 6GBではむしろ速くなりました
こちらですが、速度を犠牲にして低メモリでも動かせるようにしているものなので、問題が発生していないのであれば、指定してはいけません
set COMMANDLINE_ARGS=--precision full --no-half --xformers --medvram
(--precision full --no-half は出力される画像が真っ黒なときに入れます)
色が移る、色が混ざる
赤い帽子を指定していたらなぜか目の色まで赤くなる、というようなことがよく起こります
stable-diffusionの 大枠の色を塗ってから徐々に詳細に仕上げていく、という仕組みが影響しているものと思われます
追記20230414
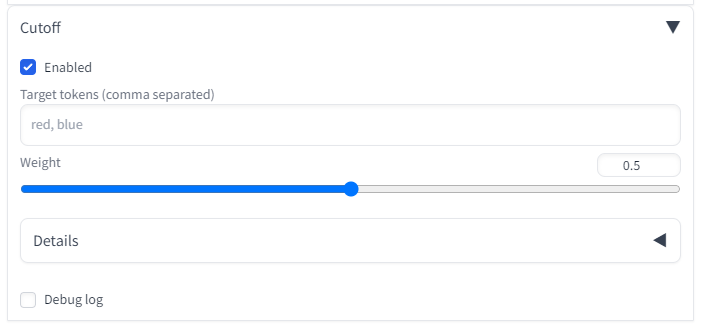
今はcutoffという拡張を使うのがより効果的なようです
プロンプトでの色指定を、プロンプトの上から順にtarget tokensに入力するだけで効果を発揮します
追記20230216
あらたに「BREAK」というキーワードに対応したようです
prompt で red hair BREAK blue eyes のように指定すると、色移りが発生しづらくなります(あくまでしづらくなる程度)
原理としてはBREAKワードが75トークン埋め尽くしてくれるので自動的にそれ以降が次のチャンクになるため、それぞれの色をわけて処理することができるようです
追記ここまで
いくつか回避策があるのですが、詳しく調査してくれている記事があるのでリンク貼っておきます
絵に好きなポーズを取らせられるようになった(ControlNet)
ControlNetという拡張によって別の画像からポージングだけを抜き出して、出力絵に適用させられるようになりました
webuiへの導入はこちら
https://github.com/Mikubill/sd-webui-controlnet
導入後は以下で棒人間(openposeの骨組み)だけ自由に操作できるツールも入れておくと、好きなポーズが作れて便利です
https://github.com/hnmr293/posex
導入法参考
https://economylife.net/controlnet-pose-image-posex/
↑で作った棒人間画像をimageに設定後、プリプロセッサnone、モデルはopenposeを指定すれば出力できます
二人以上の人物のプロンプトを個別に書き分ける
人物に限りませんが、これまでは対象を指定してプロンプトを描けないのが弱点でした
しかし画面に領域を作ってその範囲内のプロンプトを指定できるようにすることで
複数人物のプロンプトを個別に書き分ける方法が生み出されました
Latent Couple extension (two shot diffusion port)
https://github.com/opparco/stable-diffusion-webui-two-shot
webuiなら拡張で導入できます
最新の動向チェックできる場所
Twitter、なんJ、ふたば、4chanで活発に話されてます
Discordはわかりません