ABEJA Advent Calendarの7日目です。
はじめに
前回はSlack内にVIPチャンネルを作るしょーもないネタを投下しましたが、ABEJAがVIPで遊んでるだけと思われると良くないので、今回は少しだけテックに寄せることにしました。この記事では、以下の2つのネタをやってみようかと思います。分かりづらかったら、下の方に飛んでいってグラフを見ていただければ分かるかも。
- 社内のメンバーの特徴をSlackの会話履歴から作って組織内の関係性をプロット
- ある社員を、別の社員の組み合わせで表してみる
会社内のメンバー間でのコミュニケーションは、メンバー間の関係性を表しています。組織図やプロジェクト構成図を用いれば、メンバー間の部署関係や、他部署連携の状況はつかめます。しかし、どの部署とどの部署が近いかや、同じ部署でもどのメンバー間の繋がりが大きいかまでは、中々見えてきません。かといって、アンケートなどを使った所で、このような関係を気軽に可視化することは難しいものです。これに対し、Slackではメンバー間の会話ログがあり、今回はそのログを使って人間関係の可視化をやってみます。更に、機械学習(具体的にはword2vec)を用いてメンバーの特徴量を算出したり、あるメンバーを他のメンバーの組み合わせで作っちゃったりする(例:僕= 0.4 x Aさん + 0.2 x Bさん - 0.2 x Cさん)ことができます。
手法としては、Slack内の会話におけるユーザの出現列を、文章における単語列とみなして、word2vecを行うことで、ユーザの特徴を取ってやります。これにより、word2vecと同様にユーザの類似度、ユーザ間での特徴の加減算や、t-SNEを用いての可視化などが可能になります。
本記事のソースコードはこちらに公開しました。前回と違ってSlackのTOKENさえあれば動かせるので試して見てね。ついでにstarをつけてくれると嬉しいぞ。
Slackの処理
ダウンロード
まずは、自社のslackの会話履歴をダウンロードしていきましょう。各種モジュールから見ていきます。以下は現時点で登録されているユーザとチャンネルのリストの取得です。SLACK_TOKENはSlackAPIのApp CredentialsのところにのってるVerification Tokenを利用します。この辺が参考になると思います。
def get_user_list():
r = requests.get('https://slack.com/api/users.list',
params={'token': SLACK_TOKEN})
return r.json()['members']
def get_channel_list():
r = requests.get('https://slack.com/api/channels.list',
params={'token': SLACK_TOKEN})
return r.json()['channels']
次に、チャンネル毎にメッセージを取っていきましょう。channels.historyのAPIを利用します。しばしば失敗するのでリトライ処理を入れておきましょう。
def get_channel_messages(channel, from_date, to_date, retry=20):
latest = to_date
oldest = from_date
has_more = True
messages = []
while(has_more):
payload={
"token": SLACK_TOKEN,
"channel": channel["id"],
"latest": latest,
"oldest": oldest
}
for i in range(retry):
try:
r = requests.get("https://slack.com/api/channels.history", params=payload)
except BaseError as e:
t, v, tb = sys.exc_info()
print(traceback.format_exception(t,v,tb))
print(traceback.format_tb(e.__traceback__))
if r.status_code == 429:
sleep_time = int(r.headers["Retry-After"])
time.sleep(sleep_time)
continue
else:
break
else:
continue
d = r.json()
messages += d['messages']
has_more = 'has_more' in d and d['has_more']
if has_more:
latest = int(float(d["messages"][-1]["ts"]))
return messages
上記を利用して、最初にユーザリスト・チャンネルリストを取ってきて、続いて全チャンネルの履歴をダウンロードして保存します。ここではアーカイブしたチャンネルは除外しました。timedeltaの中身を減らせば早く実行できるので、そっちでテストしてから進めるのが良いと思います。
users = get_user_list()
channels = get_channel_list()
today = date.today()
messages = {}
for channel in tqdm(channels):
if channel['is_archived'] == False:
from_date = int(time.mktime((today - timedelta(60)).timetuple()))
to_date = int(time.mktime(today.timetuple()))
messages[channel['id']] = get_channel_messages(channel, from_date=from_date, to_date=to_date)
data = {'users': users,
'channels': channels,
'messages': messages}
json.dump(data, open('./log.json', 'w'))
履歴の抽出
次に、会話の履歴を抽出してみましょう。なお、後に述べるように、社員同士が似ているかどうかに「Slack上で会話をしているか」どうかを利用します。会話の内容までは見ずに、会話しているユーザIDのみ考慮します。Slackの会話はチャンネル内の会話に加え、コメントに対するスレッドがあります。メインの流れを1つの会話、スレッドを別の一連の会話としました。なお、会話抽出の際にBOTを除去(subtypeがbot_message)します。また、メインの会話かどうかはparent_user_idの有無で判定できます。メインの会話がrepliesを持っていた場合、それに含まれる情報がコメントに対するスレッドになります。
import json
with open('log.json', 'r') as f:
data = json.load(f)
sentence_list = []
channel_ids=[d['id'] for d in data['channels']]
for channel_id in channel_ids:
if channel_id in data['messages']:
messages = list(data['messages'][channel_id])
messages = list(filter(lambda x: 'parent_user_id' not in x, messages))
messages = list(filter(lambda x: 'subtype' not in x or x['subtype'] != 'bot_message', messages))
sentence = [m['user'] for m in messages]
sentence_list.append(sentence)
for m in messages:
if 'replies' in m:
sentence = [r['user'] for r in m['replies']]
if len(sentence) > 3:
sentence_list.append(sentence)
社員2vec
概要
ここまでは準備、ここからが本番です。さて、会話の履歴から社員の特徴を取るにあたり、word2vecの技術を利用します。word2vecとは、文章において前後の共起情報を学習する方法で、ある単語に対して前後にどのような単語が現れやすいかを学習します。これによって、単語同士が似ているかどうかや、単語の加減算ができるという面白い手法です。詳しくは、この辺を参考にしていただければと思います。今回は会話ログですが、一緒に会話している人を学習することで、社員の特徴を抽出する「社員2vec」を提案します。word2vec同様に社員同士が似ているかどうかや、その加減算が利用できると期待して進めていきましょう。
社員2vecの実装
実装も何もなくgensimというライブラリを利用します、完。gensimとはトピック分析など様々な言語処理に利用できる機能を持つライブラリです(たぶん)。当然word2vecも簡単に利用できます。word2vecの利用には、単語ごとに区切った文章のリストを与えます。今回は、社員のユーザIDの出現リストを文章と見立てて、これをword2vecに与えることにします。コードはそのまんまですね。パラメータについては深く考えず、前後5つの会話を以て似ていると判定、32次元の特徴を学習します。
model = word2vec.Word2Vec(sentence_list, size=32, min_count=5, window=5, iter=300)
結果
まずは、word2vecでよく実行される類語の表示、今回の場合においては似ている社員リストの表示をやります。続いて、会社全体の社員の関係マップを作成してみましょう。
最も似ている人を表示する
Slackは社員ごとにユニークなユーザIDが用いられますが、それだけでは可視化した際に誰が誰かわからなくなりますので、Slack名との相互変換の辞書を先に作っておきます。
id2name = {d['id']: d['name'] for d in data['users']}
name2id = {d['name']: d['id'] for d in data['users']}
元の社員の名前を入力し、似ている社員Top10を表示します。なお、TARGET_NAMEは、Slackで用いる名前ですが、一覧は、そのリストはprint(name2id.keys())で取ってこれるかと思います。
ret = model.wv.most_similar(positive=[name2id[TARGET_NAME]])
for r in ret:
print(id2name[r[0]], r[1])
結果
大変申し訳無いのですが、個人名が出ちゃったり組織構成が見えちゃったりするので、本記事ではボカシを入れさせて下さい。。。社員名と近さが表示されているのを想像していただければと思います。比較的同じロールの人が出ることが確認できます。

社員の関係性を表示する
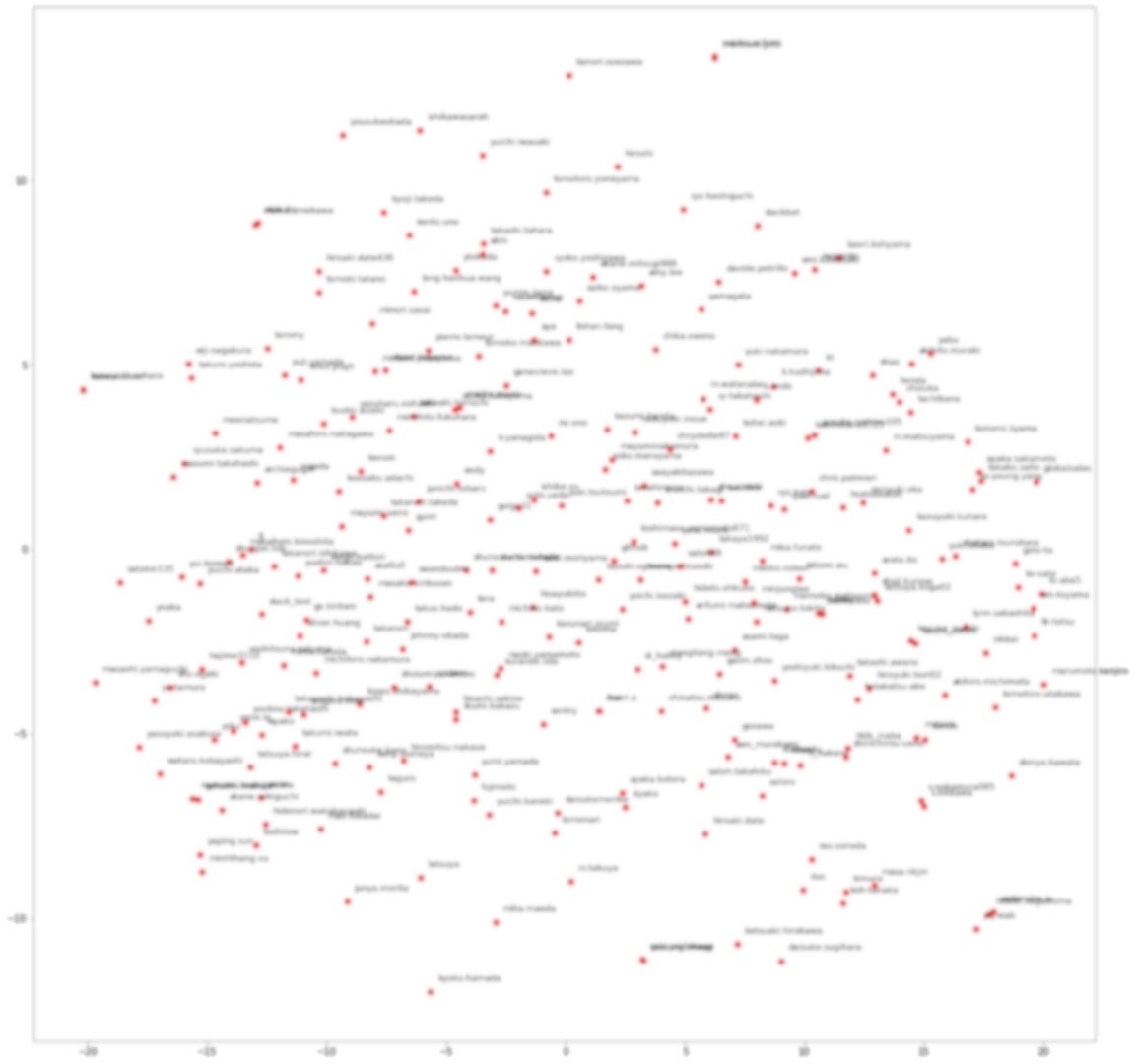
社員2vecにより、社員の特徴が出ることで、各社員に近い社員を見れるようになりました。ただし、個々の関係性をみるだけでは、全体を俯瞰した状況把握は困難です。ここでは会社全体に関して社員同士の近さを可視化するため、社員の特徴量をt-SNEを用いて2次元に圧縮します。t-SNEでは圧縮前と後でのデータ間の距離関係が大きく変わらないように気をつけながら、低次元に落とす方法です。scikit-learnのt-SNEを利用することとします。表示では各ノードが誰かを可視化するようにしております。
user_ids = list(model.wv.vocab.keys())
name_list = [id2name[id] for id in user_ids if id in id2name]
vec_list = []
for name in name_list:
v = model.wv.word_vec(name2id[name])
vec_list.append(v)
ret = TSNE(n_components=2, random_state=0).fit_transform(vec_list)
plt.figure(figsize=(20, 20))
for r, n in zip(ret, name_list):
plt.scatter(r[0], r[1], color='r')
plt.text(r[0]+0.3, r[1]+0.3, n, fontsize=9)
結果
社内の関係図がプロットされます。各点に社員の名前が表示され、近い人同士が近い位置にプロットされます。これにより、誰と誰がコミュニケーションしているか、などが可視化でします。なお、先程以上にセンシティブなので、やはりボカシますので、心の目で見て下さい。確かに、同じ部署の人同士が近くなるし、ハブ役は中心に来やすい状況になります。これを利用すれば、組織のコミュニケーション不全を評価できることで良い効果が得られるのだと考えます。
社員を組み合わせてみよう!
どの会社でもコアとなっている人物がおり、その人が会社を辞めたら困る!なんてものもあるかと思います。さて、ここでは、word2vecが特徴の加減算が出来ることを利用し、社員同士の加減算を用いて、上記コア人材を別の人で表現するという取り組みをやってみましょう。異論は認める。
定式化
ターゲットの特徴を、別の特徴の組み合わせで実現しつつ、組み合わせる人数は少なくなるようにします。これを実現するために、L1正則化を行いLasso回帰の問題とします。式としては以下のようになります。
\min \bigl({\bf y} - {\bf Au}\bigr)^2 + \lambda \Sigma|u_i|
yがターゲットの社員のベクトル、Aがターゲット社員を除いた社員の特徴を並べたもの、uはどの社員の特徴をどのくらい利用するかをそれぞれ示します。これにより、社員の特徴量の線形和でターゲット社員を表すことが出来ます。
実装
まずターゲットの社員の情報を抽出し、その後他の社員の特徴を積み上げた行列を作成します。最後にscikit-learnに実装されたLasso回帰によって、社員の組み合わせを計算します。
target_name = TARGET_NAME
target_idx = name_list.index(target_name)
target_vec = model.wv.word_vec(name2id[target_name])
menber_dict = np.array(vec_list).T
# 対象者のベクトルを辞書から削除
idx = list(range(0,target_idx)) + list(range(target_idx+1,len(name_list)))
tmp_menber_dict = menber_dict[:,idx]
tmp_name_list = np.array(name_list)[idx]
clf = linear_model.Lasso(alpha=0.9)
clf.fit(tmp_menber_dict, target_vec)
計算結果から、どの社員がどのような組み合わせで表せるかを以下のように抽出します。
selected_idx = np.where(np.array(clf.coef_) != 0)[0]
selected_names = tmp_name_list[selected_idx]
selected_coef = clf.coef_[selected_idx]
for n, c in zip(selected_names, selected_coef):
print('{}: {}'.format(n, c))
結果
例によって結果を見せられない・・・。これをやることによって、線形和に用いる社員リストと、その係数を得ることが出来ます。左がターゲットの社員を構成するのに必要な人物、右が係数となっています。

社内の反応
面白がってくれた。なお、名前出しても怒らなさそうなお二人には実名で登場してもらおう。

こんなネタも・・・。向きは決めの問題であって、引いたから悪いわけではないのですけどね。ただ、結果としては笑ってしまう。
Discussion
今回の取り組みではSlackで会話をしている人が同じ特徴を持つという前提で、それを抽出してみました。一方で、同じ会話をしているからと言って、その人たちが同じような特徴を持つとは言えないと思います。そのため、今回の結果により、組織のコミュニケーション図は表せますが、安直には社員の機能的な部分について正しく抽出できないとは思います。まぁ、word2vecも似たような物であるにも関わらず、加減算はできているようなので、ある程度は正しいものが作れていると期待はしているんですけど。
また、所定のスレッドで少人数で会話をし続けると、そのグループ内での高速は強くなる反面、他のグループとの距離がより極端に大きくなると考えられます。この回避のためには、会話の密度が高くなりすぎたら重みを弱くするなどが出来ると良いかもしれません。
今回はL1最適化によって社員の近似を行いました。実際のところはL1よりもL0の方が高い精度の結果を出せると思いますが、実装が面倒だったので今回はパスしました。
おわりに
Slackの会話履歴を使って、組織の状態可視化と、社員の組み合わせ問題を解いてみました。組織の構造を知ることで、例えば部署の配置換えをした際に、想定通りのコミュニケーションが出来ているかの仮説検証などを回すことが出来ます。流石に他の社員で賄うというのは難しいですが、面白いという観点で遊んでいただければ幸いです。
あと、これを社内Slackに投稿してみたら、社内にいる双曲空間の猛者たちが反応し始めたので僕は全力で逃げましたとさ。
おしまい。