A/Bテストの結果の検証の際、仮説検定による差の確認や信頼区間の算出を行う。頻度主義の統計な手法に基づいて実施されることが多いと思われる。
当記事でコードとともに紹介するベイズ統計によるA/Bテストの検証をすることで、
- A > Bの確率
- AとBの差の事後分布
が確認できることを確かめていく。
従来の頻度主義の統計学におけるA/Bテストの検証はいろんなサイトにて記述されていると思うので説明を省く。
以降の文章はベイズの考えの詳細とともに解説するものではない。ベイズ統計学に関する知識は以下のURL等で確認できる。
例として、ある商品のキャンペーンで、施策としてキャンペーンAとキャンペーンBをおこなったとする。
キャンペーンを経験した消費者は、その商品を購入できるものとし、キャンペーンとしてどちらが購入に効果的かを検証したい。
過去の経験からBの方が効果が良いのではないという主観があったので、
「キャンペーンBのほうがAよりも良いはず」
という視点を分析に持ち込んだ。
以下のような結果を得たとする。
| 群 | 購入したユーザー数 | 群全体のキャンペーン数 |
|---|---|---|
| A | 20 | 50 |
| B | 20 | 30 |
この例において標本空間は、
- 購入した
- 購入してない
の2つしかない。これは、ベルヌーイ分布で表現できる。今回は、これが尤度でもある。
事後分布の解析上、共役事前分布を使う。共役事前分布を使うと事前分布と事後分布が(パラメータは違うが)同じ確率分布になるため、事後分布の解析が容易になる。
今回、尤度としてベルヌーイ分布を利用するため、事前分布と事後分布はベータ分布を利用できる。
必要なライブラリのinstall
import numpy as np
import scipy.stats
from matplotlib import pyplot as plt
キャンペーン別の事後確率を可視化する
n = 10000 # 分布からの乱数の取得数は適当
campaign_a = np.random.beta(20, 30, n) # A群
campaign_b = np.random.beta(20, 10, n) # B群
plt.hist(campaign_a, alpha= 0.5, normed=True, bins=100, label="campaign_a")
plt.hist(campaign_b, alpha= 0.5, normed=True, bins=100, label="campaign_b")
plt.title("Posterior Distribution ")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=11)
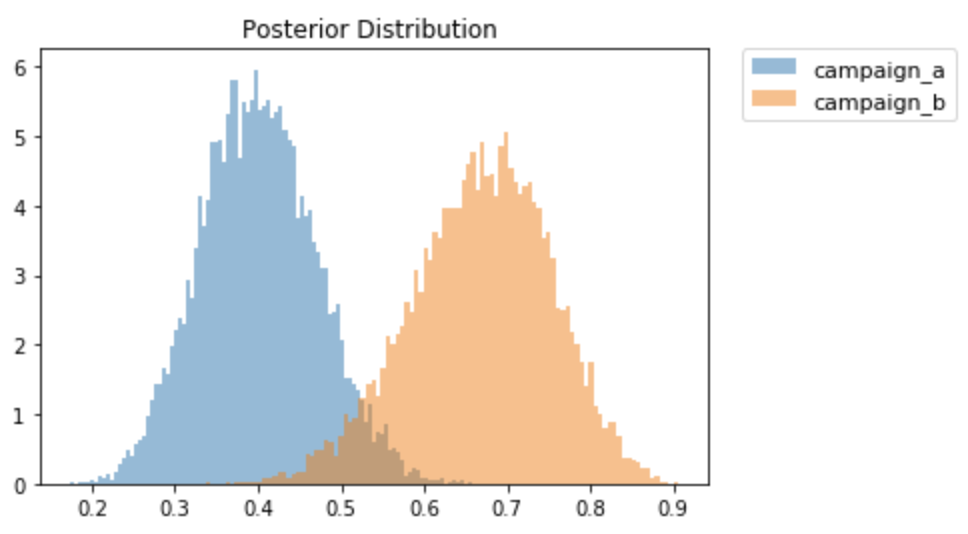
横軸は、購入確率(=θ)である。これは、キャンペーンAとBの購入率が、点推定の値としてではなく、確率分布として表現されていることを意味する。
期待値について、
上記で生成した乱数から、以下のように計算ができる。
campaign_a.sum()/n
# -> 期待値: 0.4006264924245904
campaign_b.sum()/n
# -> 期待値: 0.6680427209856055
一方、事後分布はベータ分布に従うため、各キャンペーンの期待値(=購入者率)は以下のようにも計算できる。
\ E(X) = \frac{α}{α + β}\\
したがって
| 群 | 期待値 | 導出式 |
|---|---|---|
| A | 0.4 | = 20 / ( 20 + 30 ) |
| B | 0.67 | = 20 / ( 20 + 10 ) |
生成させる乱数を増やせば、上記の理論値に近づくことが期待される。
可視化と期待値計算により、キャンペーンBの方が効果が良さそうだとわかる。
B > Aとなる確率
実際に、「キャンペーンBのほうがAよりも良いはず」を確率で表現する。
campaign_diff = campaign_b - campaign_a
diff_prob = (campaign_diff > 0).sum() / n
# 0.9896
B > Aとなる確率は、99.0% だとわかる。
補足だが、仮にAとBの結果が逆だった以下の場合
| 群 | 購入したユーザー数 | 群全体のキャンペーン数 |
|---|---|---|
| A | 20 | 30 |
| B | 20 | 50 |
上記を計算すると
diff_prob = 0.0103... のような値が1%程度の確率値になる。
これは、B > Aである確率が、0.01と極めて小さいと解釈する。
B > Aである方が蓋然性が高い、ということである。
キャンペーン間の差の事後分布
キャンペーンAとBでの購入の比率の差の事後分布を可視化してみる。これによりキャンペーンの効果がどの程度の差を生んだのかがわかる。わかりやすさのために、0のところに赤の垂線を引いた。
plt.hist(campaign_diff, normed=True, alpha= 0.5, bins=100)
plt.axvline(0, c= 'r')
plt.title("Probability distribution of difference between A and B")
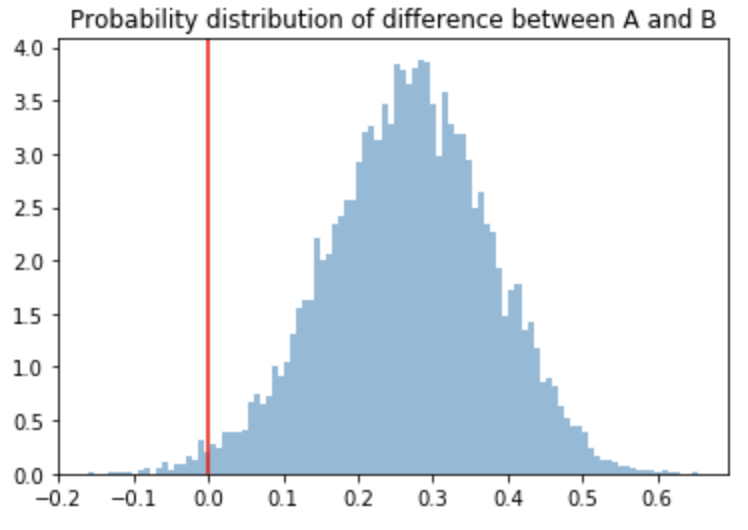
点推定での値は以下のように算出できる。
campaign_diff.sum()/n
# -> 0.2674162285610151
95%信頼区間は以下のように算出される。
numpyのpercentileを利用する。
np.percentile(campaign_diff, q=[2.5, 97.5])
# -> array([0.04569289, 0.4731627 ])
キャンペーンBの方が購入確率が高く、その差は95%の確率で4.57% ~ 47.3%の間にあると言える。