レーティング行列は、行がユーザー、列がアイテムになっている行列。
要素は、ユーザーがアイテムに対してつけた点数などを想定している。
それを作る前の前処理のメモ。
実際のデータというのはデータサイエンティストが入手した場合、レーティング行列担ってるわけではなく、下の「サンプルデータ」の段落にあるように、
ユーザー, アイテム, 点数
の行になったものが大量にあるものを指す。(例えばMovielens)
この記事では
- ある回数以上のユーザーやアイテムに絞りたい
- ユーザー、アイテムにindexをつける
をやるときのコードを示す。
データの読み込み
import pandas as pd
df = pd.read_csv('./rating.csv')
df.head()
出力
| user | item | rating | |
|---|---|---|---|
| 0 | A | a | 1 |
| 1 | A | b | 2 |
| 2 | B | a | 1 |
| 3 | B | b | 3 |
| 4 | B | d | 4 |
特定の出現回数以上のデータのみに絞る方法
users = df['user'].value_counts() # user別に集計
items = df['item'].value_counts() # item別に集計
usersの中身
C 5
D 5
B 4
A 2
Name: user, dtype: int64
itemsの中身
a 4
b 3
d 3
e 2
c 2
g 1
f 1
Name: item, dtype: int64
出現頻度の下限をもうける
min_user = 5
min_item = 2
users_filtered = users[users >= min_user] # 2
items_filtered = items[items >= min_item] # 5
reduced_df = df.merge(pd.DataFrame({'user': users_filtered.index})).merge(pd.DataFrame({'item': items_filtered.index}))
reduced_dfには、元のデータから
「5回以上評価したユーザーまたは2回以上登場したアイテム」
のみを抽出した。
ユーザーとアイテムにindexをつける
users = reduced_df['user'].value_counts()
items = reduced_df['item'].value_counts()
import numpy as np
user_index = pd.DataFrame({'user': users.index, 'user_id': np.arange(users.shape[0])})
item_index = pd.DataFrame({'item': items.index,
'item_id': np.arange(items.shape[0])})
reduced_df2 = reduced_df.merge(user_index).merge(item_index)
print(reduced_df2.shape)
reduced_df2.head(10)
出力
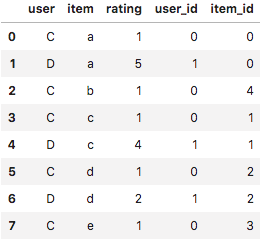
indexをつけるというのは、元のユーザー、アイテムを
ユーザー
- user C -> 0
- user D -> 1
アイテム
- item a -> 0
- item b -> 4
- item c -> 1
- item d -> 2
- item e -> 3
という対応させる操作にあたる。
おまけ
n
table = pd.pivot_table(reduced_df, values='rating', index=['user'],
columns=['item'])
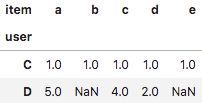
レーティング行列で、要素がある部分の割合を計算
reduced_df.shape[0]/(len(reduced_df.user.unique()) * len(reduced_df.item.unique()))
=> 0.8
サンプルデータ
user,item,rating
A,a,1
A,b,2
B,a,1
B,b,3
B,d,4
B,e,4
C,a,1
C,b,1
C,c,1
C,d,1
C,e,1
D,a,5
D,c,4
D,d,2
D,f,3
D,g,4