ご挨拶
新年あけましておめでとうございます。ものづくり小児科医のうえだです。
現在ぽちずかんという小さいお子さん向けのLINEアプリを公開しています。
もう年は明けちゃいましたが、昨年1年の振り返りがしてみたくなり、Xのポスト履歴からWordCloudを生成しました。
まずは結果から

私いまだに「笑」ってつけるタイプなのでこうなったんでしょうね。
としても、ど真ん中に「笑」めっちゃいいなと満足しております。
皆さんもぜひやってみてください(最後にコードを載せています)。
初心者向け記事です。
必要な手順
- Xのアーカイブリクエスト
- フォントのダウンロード
- GoogleColaboaratory立ち上げ
- X履歴ファイルをアップロード
- コード貼り付け
これだけでPython触ったことない方でも生成可能です。
Xのアーカイブリクエスト
まずはご自身のXアカウントの全ツイート履歴をダウンロードするために、リクエストを送りましょう。
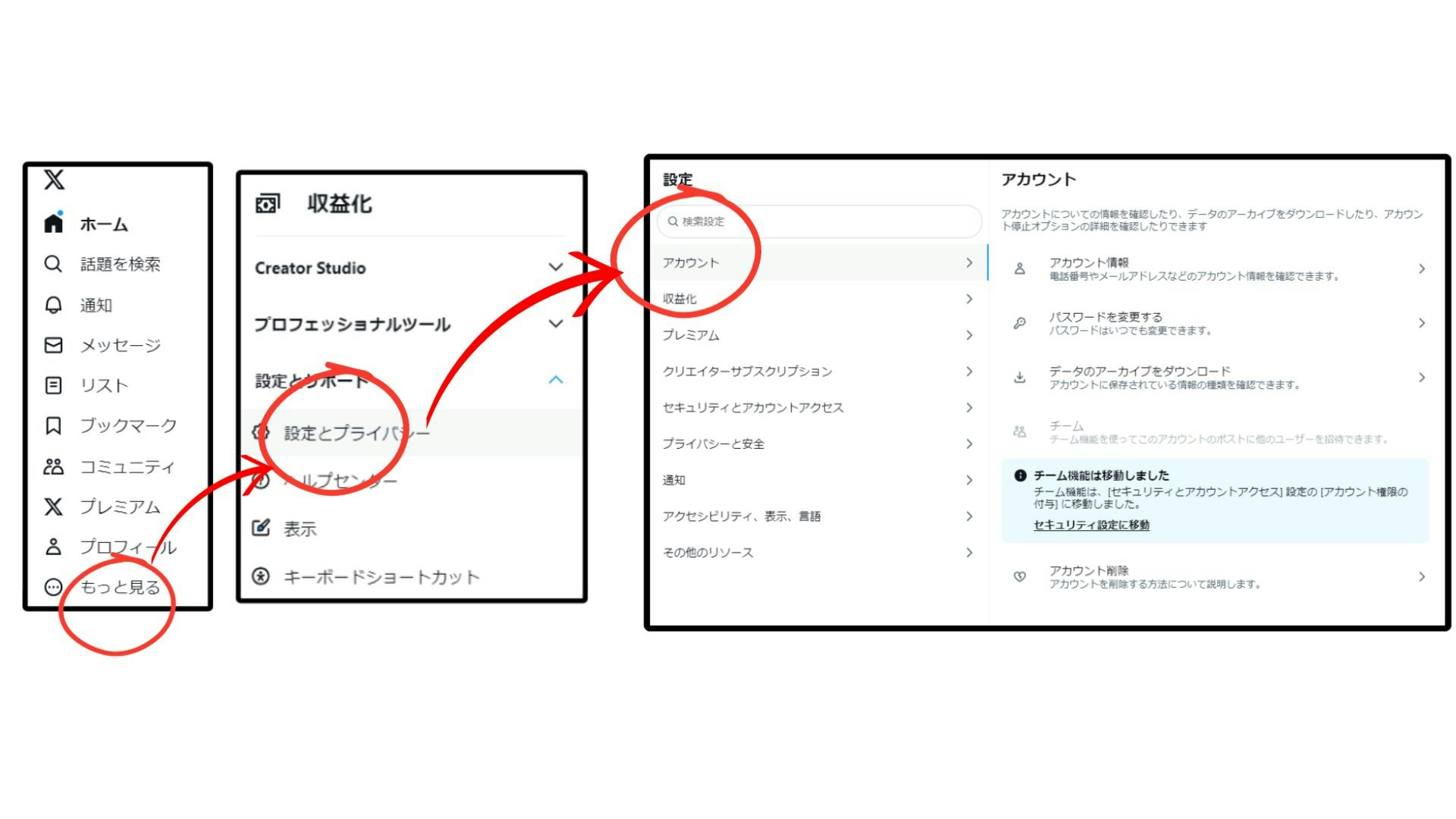
詳細は下記サイトをご参照ください(短期間に何度かリクエストを送ってしまったため現在この先の画面がお示しできず、、、)。
こちらから
しばらくするとメールで連絡があります(1日くらい?)ので、データをダウンロードしてください
解凍すると、「data」「assets」というフォルダがあります。このdataの中の「tweets.js」を使用します。
フォントのダウンロード
日本語でWordCloudを生成するにはフォントのダウンロードが必要です。
こちらからダウンロードしてください。
私はゴシックにしました。解凍すると、下のような感じになるので、ttf(TrueTypeフォントファイルと書かれているもの)を使用します。
Google Colaboratoryを立ち上げる
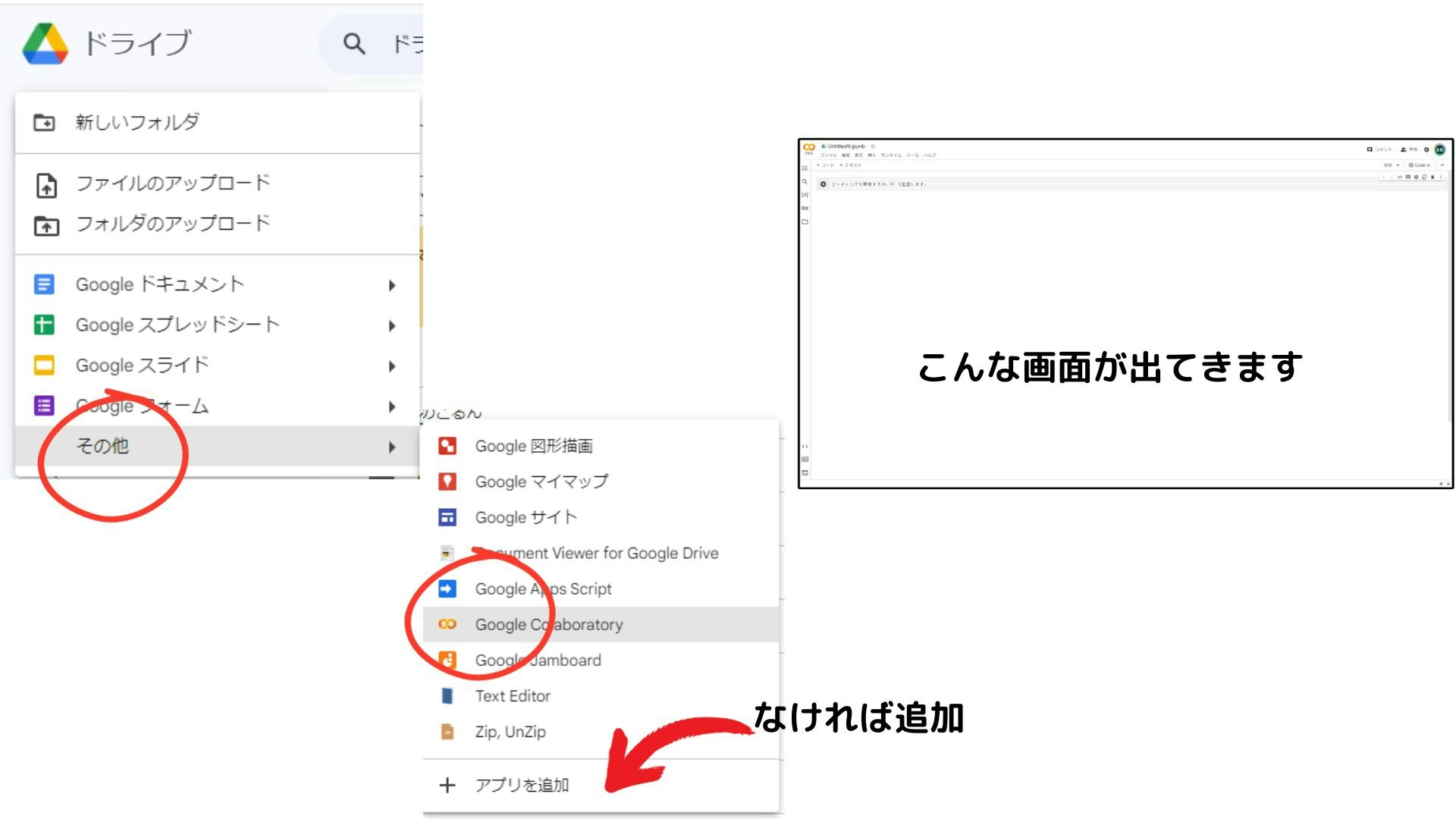
GoogleDriveから「その他」を選択して「GoogleColaborator」アプリを追加します。
既に追加されている場合は不要です。
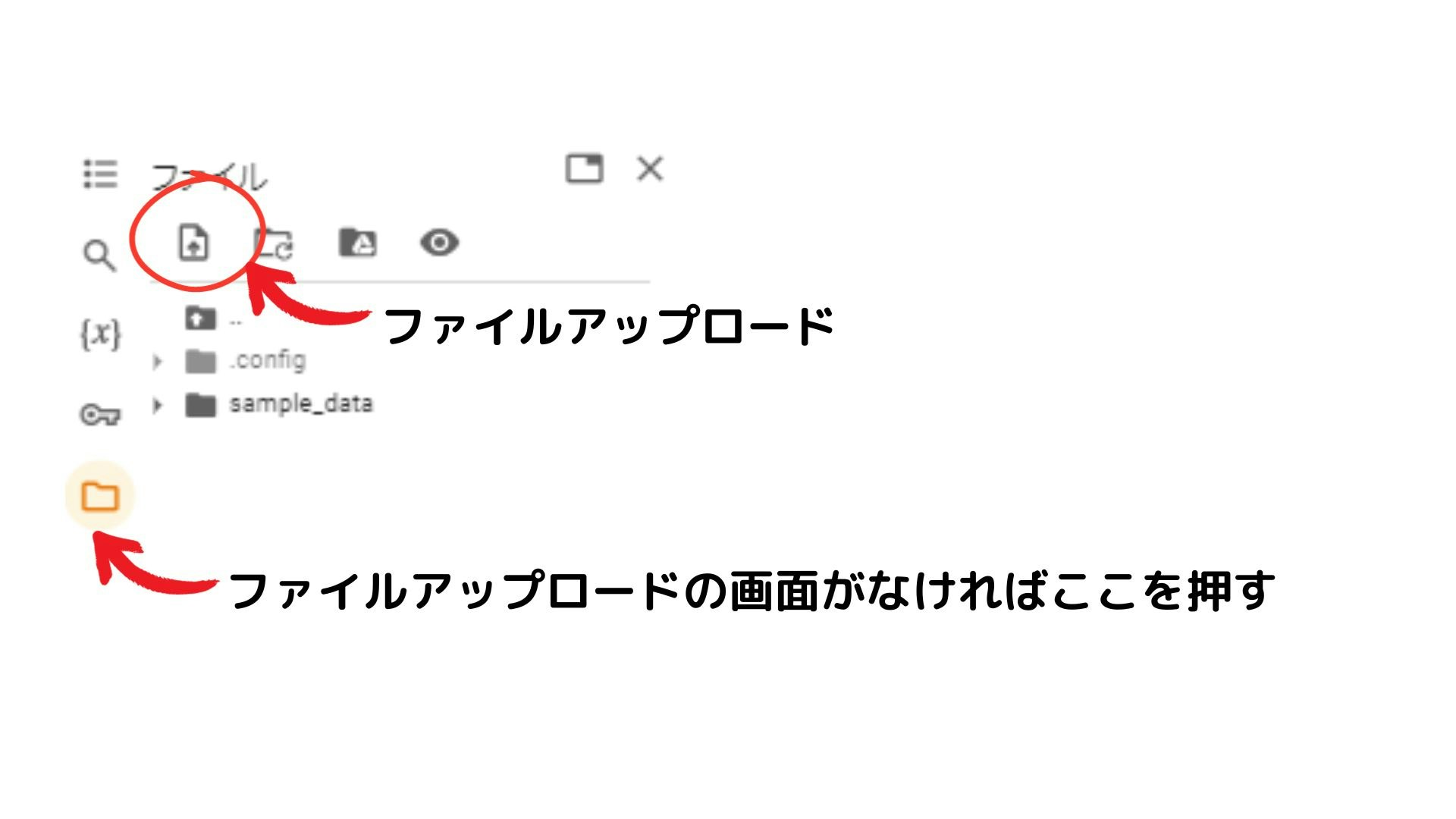
ファイルのアップロード
下記の2つをアップロードしてください。
・tweets.js
・ipaexg.ttf
このファイル名が同じであれば下記のコードのコピペで動くと思います。異なる場合はファイル名を合わせてください。
ファイルのドロップでもアップロード可能です。
!pip install mecab-python3
import json
from datetime import datetime
import re
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# tweets.jsファイルの内容を読み込む
file_path = '/content/tweets.js'
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# JavaScriptの配列部分をJSONとして抽出
json_data = content[content.find('['):] # '[' からファイル終端まで
# JSONをPythonのリストに変換
tweets = json.loads(json_data)
# Twitterの日付形式を解析する関数
def parse_twitter_date(date_str):
return datetime.strptime(date_str, '%a %b %d %H:%M:%S +0000 %Y')
# 2023年のツイートのみを抽出
start_date = datetime(2023, 1, 1)
end_date = datetime(2023, 12, 31)
tweets_in_2023 = [tweet['tweet']['full_text'] for tweet in tweets
if start_date <= parse_twitter_date(tweet['tweet']['created_at']) <= end_date]
# 英字を除去する関数
def remove_english_characters(text):
return re.sub(r'[a-zA-Z]', '', text)
# 数字を除去する関数
def remove_digits(text):
return re.sub(r'\d', '', text)
# 英字と数字を除去
tweets_no_english = [remove_english_characters(tweet) for tweet in tweets_in_2023]
tweets_no_digits = [remove_digits(tweet) for tweet in tweets_no_english]
# 英字と数字を除去したテキストをファイルに保存
output_file_no_digits_path = '/content/tweets_2023_no_digits.txt'
with open(output_file_no_digits_path, 'w', encoding='utf-8') as file:
for tweet in tweets_no_digits:
file.write(tweet + '\n')
# テキストファイルを読み込み
with open('/content/tweets_2023_no_digits.txt', 'r', encoding='utf-8') as file:
text = file.read()
# ワードクラウドの生成
wordcloud = WordCloud(font_path='/content/ipaexg.ttf',
background_color='white',
width=800,
height=400).generate(text)
# ワードクラウドの表示
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
いくつか裏話
WordCloud用に処理(データの中から去年1年のテキスト部分だけ取り出す)についてChatGPT(GPT4.0)に問いかけると、処理の仕方ではなく「ファイルをアップロードしたら作成しますよ」と言ってくれました。
twitter.jsファイルをGPT4.0のチャット画面で添付し、
このファイルの window.YTD.tweets.part0 = [] にツイートの情報が格納されています。2023年1月1日から12月31日までのツイートの「full_text」を抽出したファイルを作成してください。
と投げかけると作成可能でした。この記事を書くにあたって、そこの処理をどうやったかChatGPTに聞いて教えてもらったコードが上記です。実際それで作成できることを確認しました。
初め、処理をしていないデータを用いたところ
WordCloudはそのままでは日本語対応していないのを知らず、以前に作っていたコードそのままで動かしたところ、下記のようなものができました。
これを見た段階では、日本語対応していないのではなく単に英語の頻度が多いためにこうなっているのだと考え、英数字を抜いた日本語のみのテキストファイルを突っ込んだ結果がこちら。ここでようやく気付きました。

ぜひ共有してください
この記事を見ていただき実際に作成された方はぜひXでシェアしていただけると嬉しいです!!
ぽちずかんの宣伝
ぽちずかん
↑初めのご挨拶で書いたぽちずかんの登録はこちらです。
1歳~小学生低学年くらいの子が対象で、外出先での時間つぶしなどに有効です。
完全無料で、現在「どうぶつ」「うみのいきもの」「はたらくくるま」「アルファベット・すうじ」が公開されています。