この記事を書く理由
単純に情報量が少ないのと、公式メンバーによるミスリードがあったから。
公式メンバーのミスリードって言うのが下記URL先のDiscussionでの公式メンバーの返答内容!
「Parsing csv file with dynamic headers/columns」(ヘッダー/カラムを動的に取得してCSVファイルを解析する)
↓問題の返信内容
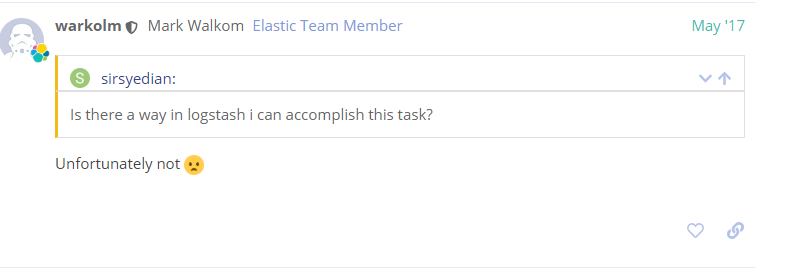
仕事上、初めてLogstashを使うことになって調べていたときにこのコメント!
俺、信じたからね!冗談抜きで信じて打ち合わせのときに言っちゃったからね!!
「LogstsashだとCSVファイルのカラム名とか動的に変更できない」って!!!
けど、公式ドキュメントとか読みながら色々と試したら、Column名を動的にできちゃったときにどれだけ公式メンバーのこのコメントにムカついたか!!!!
そんなこんなでやり方について書こうという気になりました。
使用環境
Elasticsearch 6.5.4
Kibana 6.5.4
Logstash 6.5.4 ※ Version 5.6以降なら適用可能
Logstash Config設定
テスト用ファイルとして「hoge.csv」というファイルを用意します。
※追記
なぜかCSVファイルの1行目はバグの影響で読み取ってくれません。
Worker ThreadのバグでVersion6.xは2行目からしか読み込まないとのことだが、試しにWorker=1で動かしても1行目は読み込まれませんでした。
正確には、改行コードが無い行は読み込まないだけでした。やらかした。。。orz
【参考】:"autodetect_column_names" does not work with multiple worker threads
fizz,buzz,666
foo,bar,124
サンプル csv_test.config
先に実行するプログラムを記述しますね。
input {
file {
path => ["path/to/hoge.csv"]
sincedb_path => "nul"
start_position => "beginning"
# If you need.
codec => plain { charset => "Shift_JIS" }
}
}
filter {
# get filename
grok {
match => ["path", "%{PATH}/%{GREEDYDATA:filename}\.csv"]
}
# import csv data
csv {
# set Column's names
columns => ["foo","bar","Number"]
separator => ","
}
# convert data type
mutate {
convert =>{
"Number" => "integer"
}
}
# If you use Logstash(Version 5.x~), you must use ruby filter. add_field can't change data types.
# add dynamic column's(field's) name
ruby{
code => '
event.set("foo" + event.get("filename"), event.get("foo"));
event.set("bar" + event.get("filename"), event.get("bar"));
event.set("Number" + event.get("filename"), event.get("Number"));
'
}
# Remove Needless Field
mutate{
remove_field => [ "path", "@version" ]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "test_%{filename}"
}
# output to stdout
stdout { codec => rubydebug }
}
各項目の説明
Input
説明を端折りますが、データ入力部分の設定です。
CSVファイルをExcelとかで作成した場合だと、Codecの"Shift-JIS"が必要になるってぐらいです。
Output
Logstashの出力先です。こちらも説明を端折りますね。
Grok_Filter
grok {
match => ["path", "%{PATH}/%{GREEDYDATA:filename}\.csv"]
}
正規表現を使って、文字列を辞書型配列に変換してくれる便利なFilterです。
この辞書型配列のデータはそのままOutputされるまで保持されるみたいです。※ここ重要
GrokはLogデータや標準出力にも適用できるので、頻繁に使われています。
このGrokだけでも十二分な量の文章になり、またよく記事に書かれたりするので割愛します。
今回はファイル名を得たいので、pathだけに使用。
Grokの処理を確認したのであれば、下記のデバッガーが便利です。
参考:Grok Debugger
CSV_Filter
csv {
# set Column's names
columns => ["foo","bar","Number"]
separator => ","
}
CSVファイル用のFilterです。ヘッダー(1行目)にあるカラム名を読み込んでくれたりとかしてくれます。
今回は動的に変更するためにカラム名を設定。
ちなみに公式ドキュメントには動的に設定する機能はFilter共通のadd_filedだけしかなかったです。
これがLogstashの仕様を理解するきっかけになった。
Mutate_Filter(Convert)
mutate {
convert =>{
"Number" => "integer"
}
}
CSVから読み込んだデータを適切なデータタイプに変更する処理。
Ruby_Filter (Logstash Version 5.x~)
ruby{
# Key:Value => "カラム名"+"ファイル名":"CSVデータ"
#event.set("カラム名" + event.get("ファイル名"), event.get("CSVデータ"));
code => '
event.set("foo" + event.get("filename"), event.get("foo"));
event.set("bar" + event.get("filename"), event.get("bar"));
event.set("Number" + event.get("filename"), event.get("Number"));
'
}
Grokで読み込んでおいたファイル名を各カラムにくっつけた文字列をKeyに設定。
Valueにはとカラム名(Key)から紐づいたCSVから読み込んだデータを設定。
まぁ、やってることは付け替えてるだけです。
※ここでOutputのデータ量が増えます。要らないデータは後で削除しましょう
add_fieldでも動的にカラム名を設定できるが、LogstashのVersion5.xからデータタイプを文字列から変更できなくなった。
そのため、代わりにRubyFilterを使わざるを得ない!
Mutate_Filter(Remove)
mutate{
remove_field => [ "path", "@version" ]
}
最後に余計なデータは省きましょうねー。
実行
下記のコマンドを実行して動作確認してね(雑)
logstash -f csv_test.config
追記
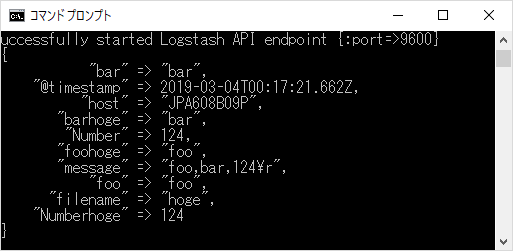
成功したらこんな感じのJSONデータが出てくる。
filenameのhogeが各カラムに追加されてます。
最後に
全て鵜呑みにしてはいけないという教訓を得ましたよ。
とはいえ初心者である以上、最初は鵜呑みにせざるを得ないんだが。。。orz
追記
もっと便利にしようとするなら、rubyフィルターの処理にfor文とかを入れてCSVのカラム数分処理させることやろね。
追記_2
autodetect_column_namesがバグで機能しないため、捻ったやり方をせざるを得ない。環境変数を使うとか。
追記3
公式のCSVフィルターのプログラムを1行弄れば動的にカラム名を変えれるようにはできる。
けど、データ型の変更をどうするか。。。