この記事は
機械学習のプロジェクトを進める際に遭遇する
環境構築にまつわるtips集
プロジェクトのたびに忘れては検索しているので個人用にまとめていたものの一部を公開してみます
Tipsなので、このようなTipsがあると知っている場合は、検索すればわかりますが。
知らないことを知らないと調べることもできないので。
だれかの参考になればいいなと思い公開してみます。
初学者向けです
主にクラウドやIDEなどなど環境に関わることなので、
Pandasやグラフなどのトピックは省きました。
シェルスクリプト
Bashの書き方。
急に忘れる、設定・変数・環境変数のsnippets
シェルスクリプトを書くときはset -euしておく - Qiita
# !/bin/bash
set -eu # e: errorで止まる, u: 未知変数エラーで止まる
# 変数
DATA=/home/nohara/data/
# 第一引数
DEBU=$1
# Pythonの自作モジュールをパスに追加
export PYTHONPATH='../src'
# ディレクトリの中身削除するなら
rm -rf ${DATA}/02_interim/*
# 何かを実行
pipenv run python 001_pre_process.py \
-i ${DATA}/01_raw/data.csv \
-o ${DATA}/02_interim/data.pkl \
-d ${DEBUG}
# 何かを実行
pipenv run python 002_train.py \
-i ${DATA}/02_interim/data.pkl \
-o ${DATA}/03_outputs/model.pkl \
-d ${DEBUG}
set -euを入れておきましょう。
これがないと、前後関係を無視してコードが走ってしまいエラーやバグの原因になります.
Makefile
Makefileの書き方
変数・事前動作などなど.
よく使うスクリプトを登録しておくと便利です
SHELL=/bin/bash
nb:
pipenv run jupyter notebook --port 8888 --no-browser
mlflow:
pipenv run mlflow ui --host=0.0.0.0:5000
pep:
pipenv run autopep8 --in-place --aggressive --aggressive -r .
pipenv run yapf -i -r .
pipenv run isort .
backup:
gsutil -m rsync -r ./ gs://hogehoge/backup
以下の用に使えます.
# jupyter notebook を起動
$make nb
# mlflow ui を起動
$make mlflow
# pep でコード整形を実行
$make pep
# 例えばGCSへコードをバックアップ
$make backup
SSH
キーの作り方。作り方はこの記事の通り.
お前らのSSH Keysの作り方は間違っている - Qiita
ssh-keygen -t rsa -b 4096 -C "your.name@mail.com"
./.ssh/configを書くだけで、ssh ts_proj_1といったように接続が楽になります。
Host ts_proj_1
HostName 32.184.123.21
User tomoyuki.nohara
Host image_proj_1
HostName 32.184.123.12
User tomoyuki.nohara
私は、複数のインスタンスを使っていますが、機械学習用途の場合だとどのインスタンスでも、
jupyter notebookやmlflowを使うので、特定のポートは共通設定として登録しています。
便利です。
Host ts_proj_1
HostName 32.184.123.21
User tomoyuki.nohara
Host image_proj_1
HostName 32.184.123.12
User tomoyuki.nohara
# アスタリスクを使って共通設定を追加可能
Host *
LocalForward 8888 localhost:8888
LocalForward 5000 localhost:5000
LocalForward 5001 localhost:5001
LocalForward 23750 /var/run/docker.sock # Dockerへアクセス
AddKeysToAgent yes # パスフレーズを聞かれる頻度が減る
UseKeychain yes # パスフレーズを聞かれる頻度が減る
ServerAliveInterval 60 # 再接続の設定
fish
あまりシェルにこだわりなければ、とりあえずaptでfish入れておけば
入力がすごく楽になります。
# ubuntu
$ sudo apt install fish
# mac
$ brew install fish
使い方 fish と打つだけ.
すると補完が効くようになるのでとても便利です。
$ fish
便利
Git
何はともあれgitのセットアップ.
$ git config --global user.name "nopara"
$ git config --global user.email "nopara@mail.com"
あと、毎回パスワードを入れるのが面倒な場合、一定期間パスワードをキャッシュするオプションも地味に便利です
# gitのパスワードを一定期間だけ聞いてこなくなる.
$ git config --global credential.helper 'cache --timeout=3600'
基本形.
# 基本件
git add .
git commit -m ":)"
git push origin master
タグを切った際の挙動
# タグを追加
git tag -a v1.0 -m "model v1"
# タグもpush
git push origin --tags
VSCode - Remote SSH の除外ファイル設定
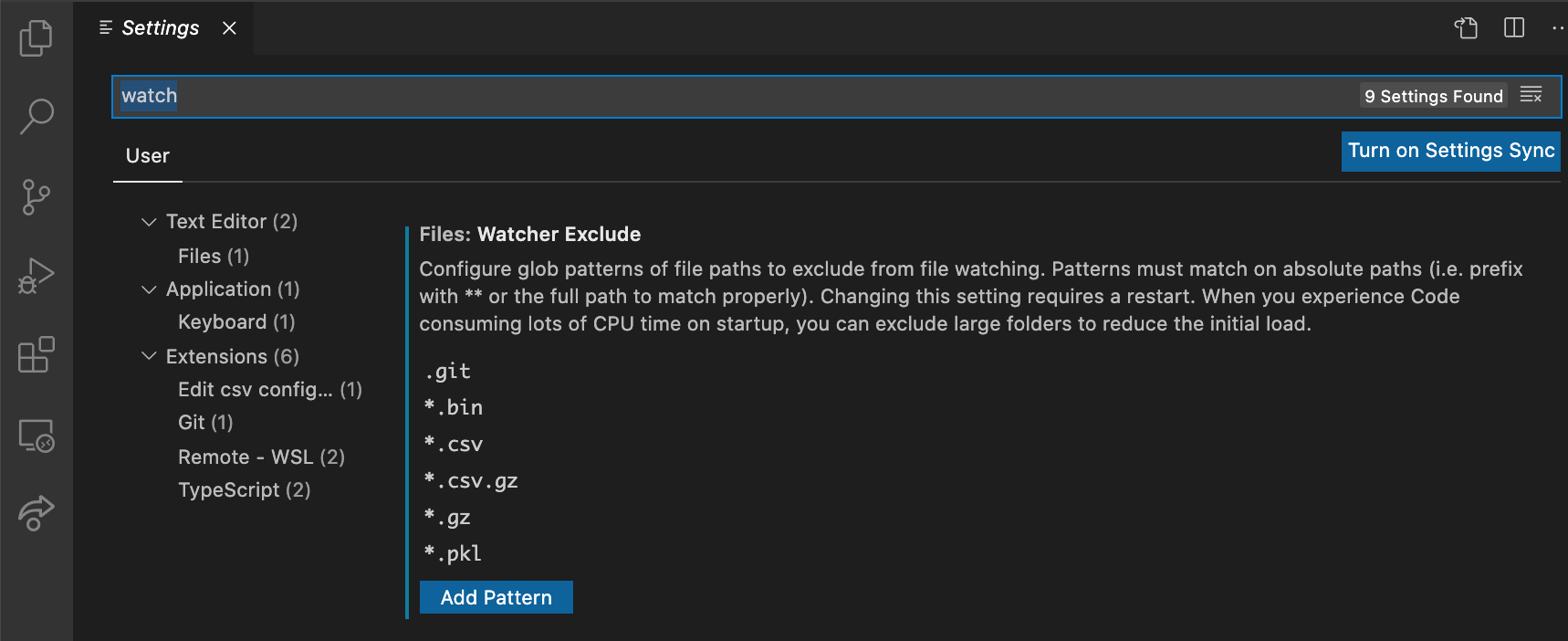
これ、プロジェクトの後半でよくハマって焦るやつ。VSCodeのRemote SSHプラグインを使って、クラウドインスタンスで作業するのですが、その際、Remote SSHは、指定したディレクトリの中身全てを「同期」しようと頑張ってしまいます。そのため、作業ディレクトリにdataなどが含まれたり、分析の最中に出力した大きなファイルがあると、同期に時間がかかってしまい、最悪の場合は全く動かなくなってしまいます。
そのため、初めの段階で除外するファイルやディレクトリを事前に指定しておくことをお勧めします。
リモート接続時に無視するディレクトリの指定
Running Visual Studio Code on Linux
hyperdash
hyperdashio/hyperdash-sdk-py: Official Python SDK for Hyperdash
# install
pipenv install hyperdash
# Login (アカウントがある場合)
pipenv run hyperdash login --email
# 実行
pipenv run hd run -n "Long Preprocess" bash download.sh
Slack 通知
slackへの通知は意外と簡単にできます
!pipenv install slackweb
import sys
import slackweb
slack = slackweb.Slack(url="https://hooks.slack.com/services/T02D36VHP/asfda")
if len(sys.argv) >= 2:
msg = sys.argv[1]
slack.notify(text=msg)
else:
slack.notify(text="finish")
GCP 関連
auth
# ログイン
gcloud auth login
# プロジェクト一覧
gcloud projects list
# プロジェクトの設定
gcloud config set project your_proj_id
GCE インスタンスの操作
# インスタンスの起動・停止
gcloud compute instances list
gcloud compute instances start <your-instance-name>
gcloud compute instances stop <your-instance-name>
SSH Configの作成.
~/.ssh/configにoptionが作成される.
# SSH Configを自動作成
gcloud compute config-ssh
GCSへの同期
# ローカル -> GCS 転送
gsutil cp ./dataset.csv gs://your-gucket-name/datas/
# -r は再帰処理。ディレクトリ送るときに使う。
gsutil cp -r gs://your-gucket-name/datas/ ./data
# 大量に送る
# -r : recursive
# -d : ローカルにないファイルをリモートから削除
# -m : 並列
gsutil -m rsync -r -d ./datalake gs://abeja_datalake/1702719765261
GCEファイヤーウォールの自動更新
おまけですが結構便利です。
セキュリティの都合でインスタンスに ipアドレス制限をかけている場合、インターネット環境が変わるたびにコンソールからグローバルIPを登録するのが辛いなと思っていました。
以下のスクリプトで、グローバルIPを取得して、指定のファイヤーウォールを更新してくれます。
# /bin/bash
FIREWALL_NAME=ssh-access # <-------- 自分のファイヤーウォール名に書き換える
# Get Global IP ..
GIP=$(curl https://httpbin.org/ip | jq -r ".origin")
# 一覧取得 / アップデート
gcloud compute firewall-rules list
gcloud compute firewall-rules update $FIREWALL_NAME --source-ranges=$GIP
gcloud compute firewall-rules describe $FIREWALL_NAME
Jupyter Notebook
横幅を広げる。
どんなエクステンションよりも気に入っているハックです。
横広になりテーブルなどがとてもみやすくなります。
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:90% !important; }</style>"))
tqdm
いつも使わせてもらっております。
引数や、その他の便利な使い方
tqdm/tqdm: A Fast, Extensible Progress Bar for Python and CLI
class tqdm():
def __init__(self, iterable=None, desc=None, total=None, leave=True,
file=None, ncols=None, mininterval=0.1,
maxinterval=10.0, miniters=None, ascii=None, disable=False,
unit='it', unit_scale=False, dynamic_ncols=False,
smoothing=0.3, bar_format=None, initial=0, position=None,
postfix=None, unit_divisor=1000):
よく使うのは、descとdisableの二つ
from tqdm.auto import tqdm
# desc: ログ出力用のdescribe
# disable: 表示/非表示
for target in tqdm(tqrgets, desc="Download hoge", disable=False):
...
pandasのapplyの処理がが長い場合に、tqdmを使ってプログレスバーを出すことができます.
pandasのapplyの進捗をtqdmで表示 - iMind Developers Blog
tqdm.pandas(desc="my bar!")
df.progress_apply(lambda x: x**2)
df.progress_map(lambda x: x**2)
warningを非表示
import warnings
warnings.filterwarnings('ignore')
timer
kaggle知見のコード。いつも使わせてもらっています。
import time
from contextlib import contextmanager
@contextmanager
def timer(name):
t0 = time.time()
yield
print(f'[{name}] done in {time.time() - t0:.0f} s')
ABEJAでは

ABEJAでは一緒に仕事をする仲間を募集しています!!
興味がある方がいましたら、カジュアル面談からでも、気軽にご連絡ください!!